前言
Nginx-包教包会-入门 一文中介绍了怎么使用 Nginx 搭建 web 服务器。
但有的时候呢,我们需要对资源进行访问控制。比如说需要登录才能访问,访问链接具有时间段限制。
又比如说防止恶意攻击,使用限流,限制带宽等等
我们也会使用 Nginx 作为代理服务器,将我们的动态内容的请求转发到应用服务器去处理。
下一期,总结一下 Nginx 相关的配置,给出一个配置模板
本文内容
- 基于
ngx_http_auth_basic_module模块,使用用户名和密码限制资源的访问 - 基于
ngx_http_auth_request_module集成已有的授权验证 - 基于
ngx_http_secure_link_module限制连接的时效性和访问控制 - 基于请求的限流、基于并发链接数限流,限制每个链接的带宽
- 为什么要使用 Nginx 作为代理服务器及代理的配置,及获取用户的真实 ip 。
- 基于代理的负载均衡
授权才能访问 Nginx 中的资源
有的时候我们想简单限制用户的访问。可以使用 ngx_http_auth_basic_module 模块,我们预先设置好账号和密码,用户需要使用特定的用户和密码才能访问。在网站没有用户登录管理功能的时候,可以作为一个替代品。
| Syntax: | auth_basic string | off; | | :------- | -------------------------------------------- | | Default: | auth_basic off; | | Context: | http, server, location, limit_except |
| Syntax: | auth_basic_user_file file; |
|---|---|
| Default: | — |
| Context: | http, server, location, limit_except |
Nginx 自带登录验证
密码生成
可以使用 htpasswd 生成密码,也可以使用 OpenSSL 生成密码。
yum install httpd-tools -y
# htpasswd --h 可以查看帮助命令
# 在指定文件位置生成,用户zhang1 和它的密码,输入之后,会让你设置你的密码
htpasswd -c /etc/nginx/mypasswd zhang1
# 在已有的文件中添加用户 zhang2
htpasswd /etc/nginx/mypasswd zhang2
mypasswd 中文件的内容
zhang1:$apr1$5dvJBg5z$aY.ncM55O8caHgyOvd.G0/
zhang2:$apr1$3YUp0G3g$agIpFCfS4K3rfqn.F29VB1
配置访问控制
然后再 nginx 中添加这个配置
location / {
auth_basic "sdaf";
auth_basic_user_file /etc/nginx/mypasswd;
}
nginx -s reload 刷新配置,然后再访问资源就需要输入预先设置好的用户名和密码。

第三方授权访问
ngx_http_auth_basic_module 尽管可以限制访问,但是作用太鸡肋了,它相当于另一套登录逻辑。它不能集成我们已有的授权功能。
Nginx 中的模块 ngx_http_auth_request_module 也支持第三方的授权的验证的。
nginx -V 看你的编译的模块中是否包含此模块。
| - | 说明 |
|---|---|
| 语法 | auth_request uri |
| 默认 | auth_request off; |
| 上下文 | http、server、location |
auth_request 启用基于子请求 (uri) 结果的授权。子请求返回一个 2xx 响应吗,则允许访问。如果返回 401 和 403 则拒绝访问。
下面模拟一个场景进行实现。
子请求(/auth)的验证基于 cookie 中的 Authorization ,存在返回 200 状态码。不存在返回 403 状态码。
在 nginx 配置 403 状态码跳转到我们的登录页面。
http://localhost:9090 下的资源都需要限制访问。
server {
listen 9090 default_server;
server_name "$host"; root /usr/local/var/www; index index.html; location / { # 9090 下的请求,都去访问 /auth 看看有没有权限访问 auth_request /auth; } location =/auth { # 代理去访问我们已有的登录授权 proxy_pass http://localhost:8087/auth; proxy_pass_request_body off; proxy_set_header Content-Length ""; } # 403 状态码,跳转我们已有的授权登录功能 error_page 403 = @login; location @login { # oriUrl 使我们用于登录成功之后的跳转链接 return 302 http://localhost:8087/login.html?oriUrl=$scheme://$http_host$request_uri; } } 用户访问资源,如果鉴权失败会跳转到登录页面,在登录页面登录之后,重新跳转到用户访问的资源路径。
登录页面实现逻辑:点击登录,地址栏刷新地址,请求接口 http://localhost:8087/login?oriUrl=xxx,访问成功,接口会设置 cookie 并跳转到 oriUrl 指定的资源。
login.html 内容,这里我不想在写 ajax 去请求接口饭后进行跳转,所以改变浏览器地址栏
<!DOCTYPE html>
<html lang="en"> <head> <meta charset="UTF-8"> <title> 登录 </title> </head> <body> 登录页面,点击登录之后跳转到访问的页面. <br> <a id="login"><button>登录</button></a> <script> let elementById = document.getElementById("login"); elementById.onclick=()=>{ window.location.href="/login"+window.location.search; } </script> </body> </html> 服务端代码,http://localhost:8087
服务端会鉴权接口只判断有没有 Authorization cookie。
登录接口也比较简单,没有进行账号密码验证,访问既返回 cookie。并跳转。
@RestController
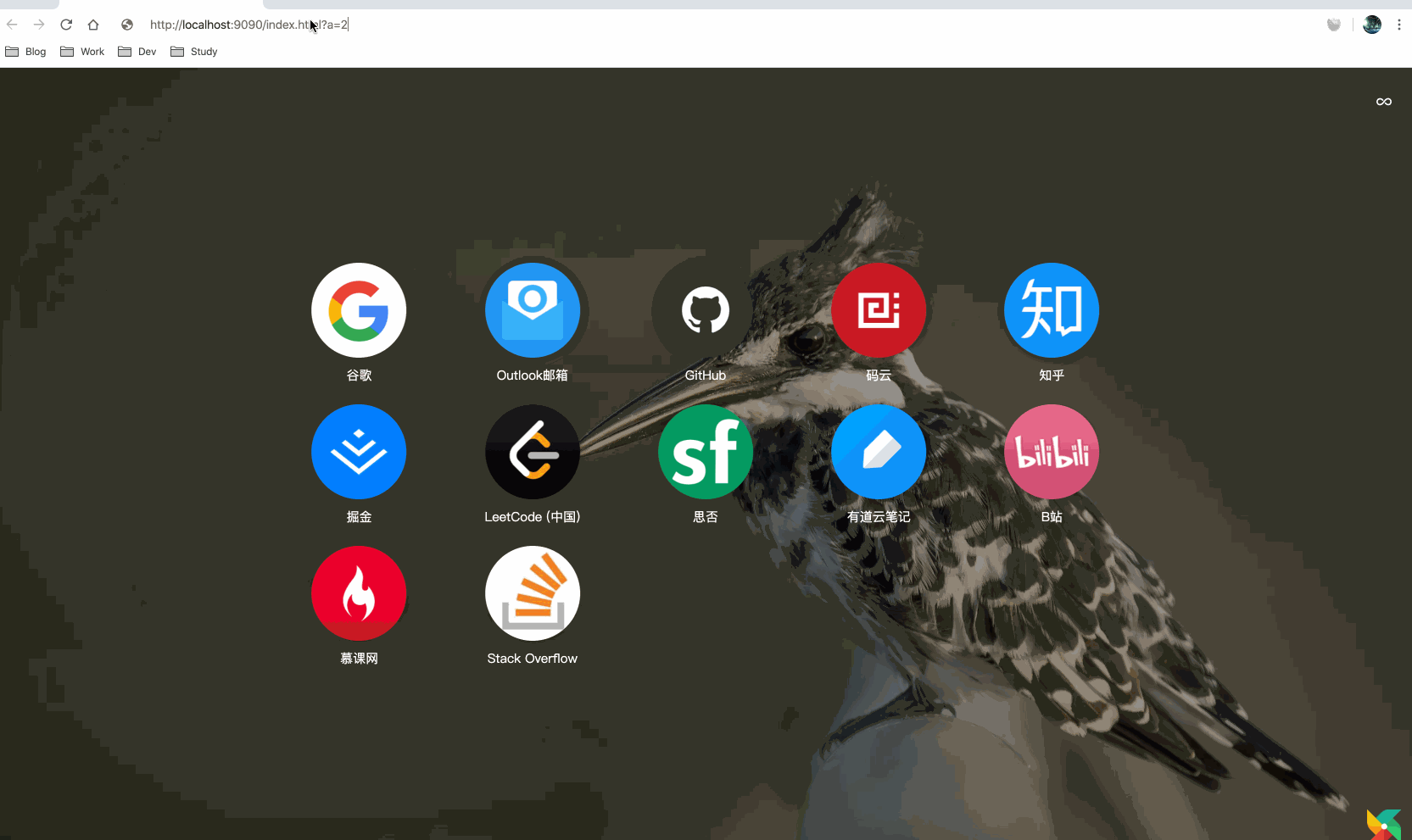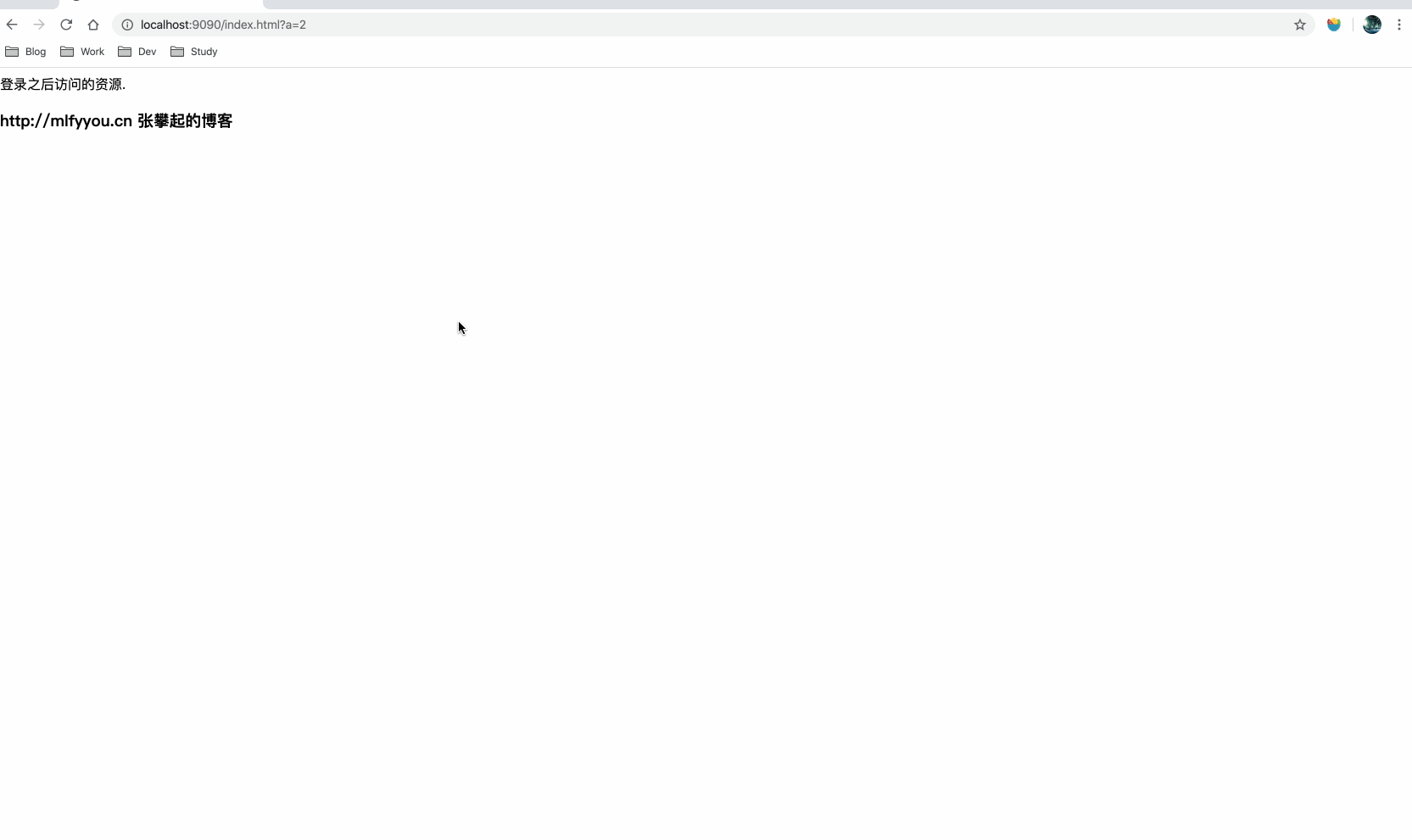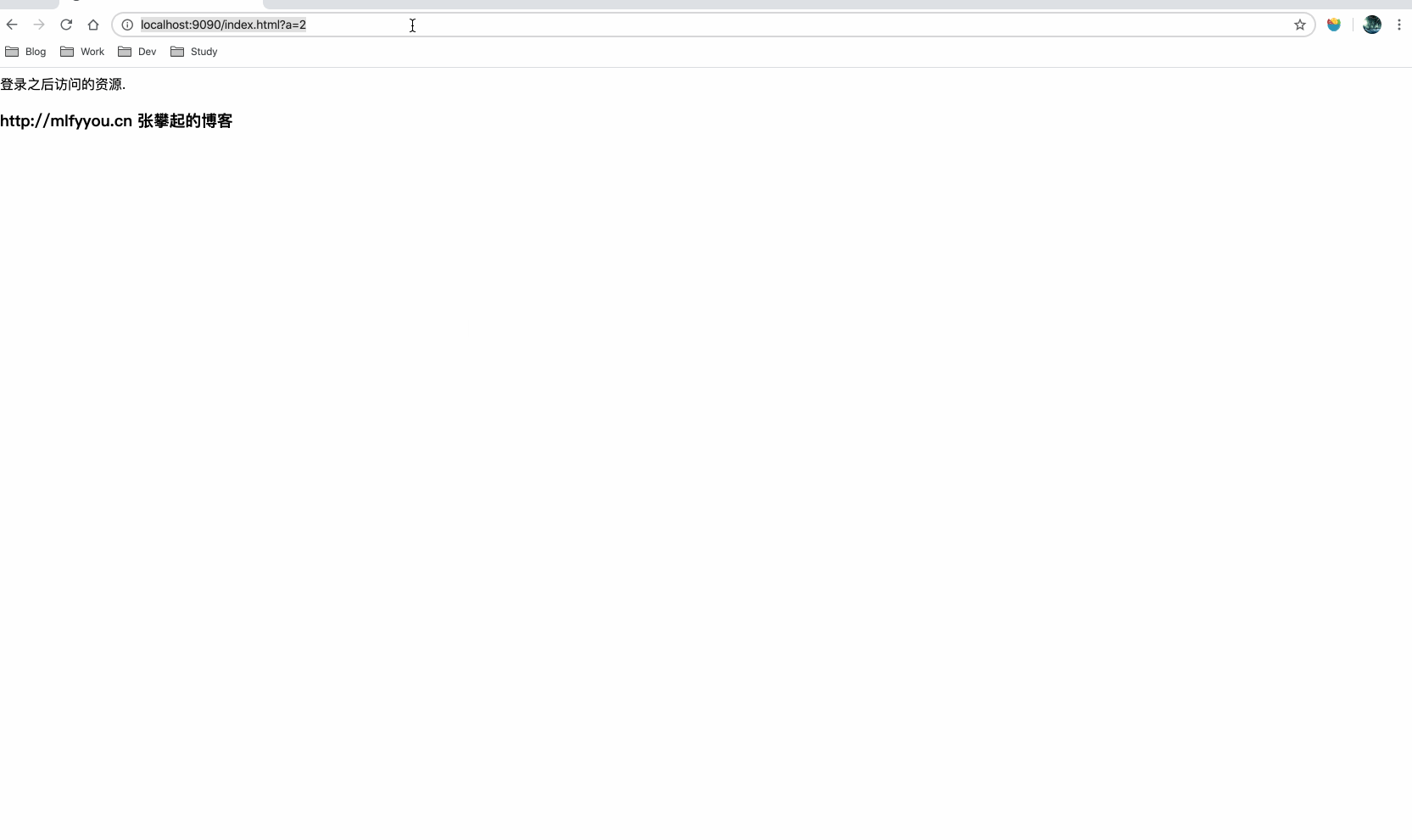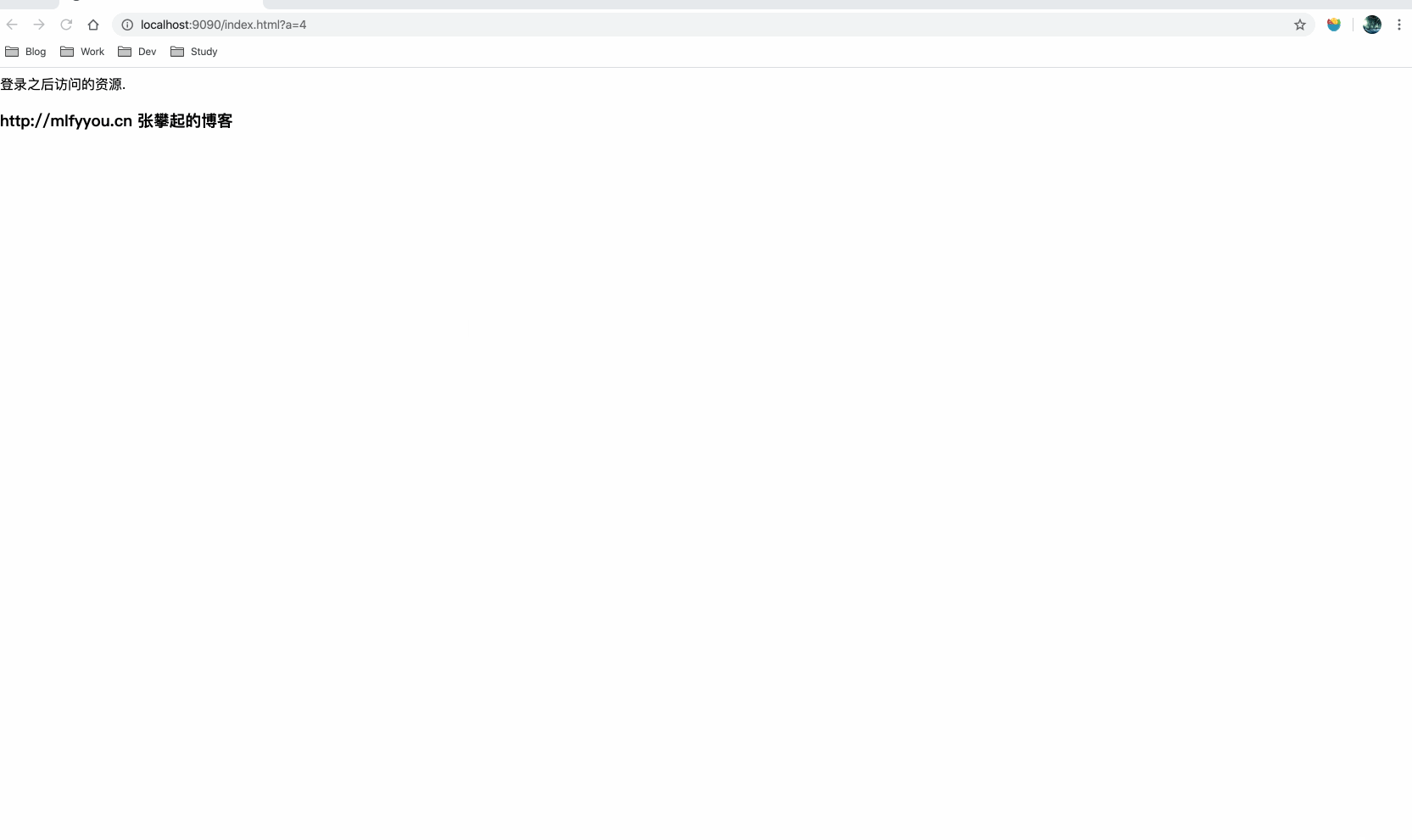
public class AuthController { // 用于资源鉴权,逻辑比较简单,就看有没有 cookie @GetMapping("/auth") public ResponseEntity<String> res(HttpServletRequest request) { Cookie[] cookies = Optional.ofNullable(request.getCookies()).orElse(new Cookie[0]); Optional<Cookie> authorization1 = Stream.of(cookies).filter(item -> { String value = item.getName(); return Objects.equals("Authorization", value); }).findFirst(); if (authorization1.isPresent()){ return ResponseEntity.status(200).body("success"); } return ResponseEntity.status(403).body("fail"); } // 登录逻辑,也比较简单,访问就会设置 cookie 及跳转 @GetMapping("/login") public RedirectView request(HttpServletRequest request, HttpServletResponse response){ final Cookie cookie = new Cookie("Authorization", "Authorization"); cookie.setPath("/"); cookie.setDomain("localhost"); response.addCookie(cookie); final String oriUrl = request.getParameter("oriUrl"); final RedirectView redirectView = new RedirectView(); redirectView.setUrl(oriUrl); return redirectView; } } 效果演示,访问 http://localhost:9090/index.html 的时候由于没有登录,nginx 错误状态码 403 跳转到了登录页面,在登录页面点击登录,跳转到 http://localhost:9090/index.html
ngx_http_secure_link_module
有的时候呢,我们希望访问的链接具有时效性。比如微信发布的文章中,文章路径有时效性,过了这个时效性就没有办法访问了。或者有的资源必须带有一些字段我们才让其访问。
secure_link
| - | 说明 |
|---|---|
| 语法 | secure_link expression; |
| 默认 | - |
| 上下文 | http、server、location |
定义从哪里取到的链接的 md5 和 过期时间,以逗号隔开
# 从请求参数中取链接的 md5 和过期时间
secure_link $arg_md5,$arg_expires;
secure_link_md5
| Syntax: | secure_link_md5 expression; |
|---|---|
| Default: | — |
| Context: | http, server, location |
在secure_link_md5 的 expression 中可以通过 $secure_link_expires (只能在 secure_link_md5 expression; 使用)获取链接指定的过期时间。
nginx 会校验取到的 md5 (secure_link 指定的第一个值)和 secure_link_md5 指定的 expression 计算出来的 md5 是否一致, 不一样会将 secure_lin 设置为 "" 。校验 md5 成功,校验过期时间,过期将 secure_link 设置为 "0” ,校验成功设置为 "1" 。
location /s/ {
secure_link $arg_md5,$arg_expires;
secure_link_md5 "123$secure_link_expires$uri hello"; # md5 不一致返回空 if ($secure_link = "") { return 403; } # secure_link 为 0 标识,链接过期了 if ($secure_link = "0") { return 410; } } 我们需要事先将链接计算好,然后将连接发布出去。
比如说我想限制 /s/a.jpg 访问。那么我需要使用算法计算链接。比如说
shell 命令生成 md5 的值。
#!/bin/bash
# 服务 IP 端口
IP=localhost:8888
LINK_URL="/s/a.jpg"
NOW=$(date +%s)
TIMESTAMP=$((NOW + 10))
SECRET_STR=hello
md5=$(echo -n "123${TIMESTAMP}${LINK_URL} ${SECRET_STR}" | openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d =) echo "http://${IP}${LINK_URL}?md5=${md5}&expires=${TIMESTAMP}" 上述脚本会打印出访问链接。
java 生成 md5 的值
一般我们都会在服务端进行生成链接。
public class HttpSecureLink {
public static final String site = "http://localhost:8888"; public static final String secret = " hello"; public static String createLink(String path, long expireTime) { final long l = LocalDateTime.now().toEpochSecond(ZoneOffset.of("+8")) + expireTime; String time = String.valueOf(l); String md5 = Base64.encodeBase64URLSafeString(DigestUtils.md5("123" + time + path + secret)); String url = site + path + "?md5=" + md5 + "&expires=" + time; return url; } public static void main(String[] args) { System.out.println(createLink("/s/a.jpg", 10L)); } } 需引入 jar
<dependency>
<groupId>commons-codec</groupId> <artifactId>commons-codec</artifactId> <version>1.14</version> </dependency> 这样我们的链接就可以限制到哪些用户可以访问,还可以具有一定的时效性。
基于请求限流
ngx_http_limit_req_module 采用 漏桶算法 进行限流。
<img src="http://oss.mflyyou.cn/blog/20200405104827.png?author=zhangpanqin" alt="28171216_TJQR" style="zoom:67%;" />
水滴比作网络请求,当水滴超过桶的容量,请求会被拒绝。漏桶算法是以匀速掉落水滴(处理请求)。
比如说 rate=3r/m 是 20000ms(20s) 一个匀速处理请求。nginx 是毫秒作计量单位。超过的请求就会被抛弃掉。桶的容量实际是一个队列,limit_req 中的 burst 配置队列的大小,burst 可以应对突发请求。
比如 rate=3r/m ,那么 20s 处理一个请求。这 20s 来两个请求就会有一个请求被抛弃掉。
rate=3r/m 和 burst=3 可以应对突发请求,20s 内来了五个请求,一个被处理,三个请求放到缓冲队列等待处理,剩下的一个被抛弃掉。然后匀速处理请求,一个一个消耗掉队列中的请求,队列中有空余位置,又可以应对突发请求了。
设置以什么为标识限流
| - | 说明 |
|---|---|
| 语法 | limit_req_zone key zone=name:size rate=rate; |
| 默认 | - |
| 上下文 | http |
key 可以包含文本、变量及组合。设置限制请求的标识。
以下配置相当于根据访问用户的 ip 限制访问,每秒只能 10 个请求。
比如说,我访问 http://localhost:9091/2.jpg 限流了,我再去访问http://localhost:9091/1.jpg也是会被限流。
limit_req_zone $binary_remote_addr zone=one:10m rate=10r/s;
下面这个以用户的 ip +访问路径为限制标识。
比如说,我访问 http://localhost:9091/2.jpg 限流了,但是我可以访问 http://localhost:9091/1.jpg。
limit_req_zone $binary_remote_addr$uri zone=one11:10m rate=3r/m;
size 相当于为设置保存 key 的空间,超过这个空间大小,就会使用缓存策略,清楚掉最近最少使用的状态。
设置哪些地方限流
| - | 说明 |
|---|---|
| 语法 | limit_req zone=name [burst=number] [nodelay]; |
| 默认 | - |
| 上下文 | http、server、location |
一般我们都会配置 limit_req zone=one11 burst=4 nodelay;
nodelay 为配置缓冲队列中的请求,不延迟执行,但是队列中的空间还是需要匀速消耗请求去恢复。
###设置限流的响应状态码
| - | 说明 |
|---|---|
| 语法 | limit_req_status code; |
| 默认 | limit_req_status 503; |
| 上下文 | http、server、location |
设置拒绝请求的响应状态码。
列子讲解
limit_req_zone $binary_remote_addr$uri zone=one:10m rate=3r/m;
server { listen 9091 default_server; location / { limit_req zone=one burst=4 nodelay; root /Users/zhangpanqin/stduy_app/break2; } } 缓冲队列为 4。每 20 s 处理一个请求。nodelay 让队列中的请求不延迟执行。
第一个 20 s 内,可以处理 5 个请求。队列和匀速加一块正好五个。
第二个 20 s 内,就只能处理 1 个请求。因为队列中的容量没有回复。
如果接下来一段时间都没有请求处理的话,那么队列就会每 20 s 回复一个位置,回复的位置可以处理请求,这样慢慢达到 4 个。又可以 20 s 内处理 5 个请求了。
limit_req_zone 配置的是用户的 ip 和 path 作为限流标识。
比如说,我访问 http://localhost:9091/2.jpg 五次限流之后,但是我可以访问 http://localhost:9091/1.jpg五次。
基于链接数限流
有的时候我们基于请求限流还不能达到我们的目的,因为瞬间流量控制不了,我上面举的例子是基于 ip 和 path 限流,如果被恶意攻击,那么可能好几百的请求被处理,这显然不符合正常用户的行为。
比如说你有一个文件下载功能,每个文件 1 分钟只能下载一次,但是恶意攻击的话,你的 100 个文件我同时下载,这样的带宽和流量就被白白消耗了。
针对上述情况,我们可以结合连接数限流,每个 ip 限制并发链接 5 个。这样就没有办法一次性下载 100 个文件了。
ngx_http_limit_conn_module 就是针对并发链接限制的,服务器处理了请求并读取了整个请求头,并发链接才会计数。
limit_conn_zone
| - | 说明 |
|---|---|
| 语法 | limit_conn_zone key zone=name:size; |
| 默认 | - |
| 上下文 | http |
key 用于限流标识。zone 定义存储的大小和名称。
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_conn 在哪里限制
| - | 说明 |
|---|---|
| 语法 | limit_conn zone number; |
| 默认 | - |
| 上下文 | http、server、location |
配置允许的最大并发链接数。
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /download/ { limit_conn addr 1; } } limit_conn_status 配置限流时的响应状态码
| - | 说明 |
|---|---|
| 语法 | limit_conn_status code; |
| 默认 | limit_conn_status 503; |
| 上下文 | http、server、location |
配置限流时响应状态码,我们可以根据状态码跳转到提示页面。
error_page 503 = @limit2;
location @limit2 { add_header Content-Type application/json; return 200 "你被限流了,稍后再试"; } 基于响应带宽限制
| - | 说明 |
|---|---|
| 语法 | limit_rate rate; |
| 默认 | limit_rate 0; |
| 上下文 | http、server、location、location 中的 if |
设置为 0 标识不限制响应。rate 为字节/秒为单位。
# 每秒 4k 响应
set $limit_rate 4k;
代理
ngx_http_proxy_module 允许将一个请求传递给另一个服务器。
nginx 的代理有一个好处是,它会将客户端的请求信息全部读取之后,客户端的请求信息比较大的话,会放到临时文件中去,读取完之后请求信息之后再转发至代理服务器。这样做的好处是,降低了上游服务器的负载,缺点是延长了响应的时间,多占了内存。
比如我们有一个上传文件的功能,直接上传服务器可能比较慢,而且还占用链接,但是我们使用 nginx 代理的话,它会先经过 nginx 上,,读取请求内容根据内容大小是否保存临时文件,然后再通过内容传输到我们的服务器。这样应用服务器的链接占用时间就会比较短(nginx 与上游的代理服务器处于内网)。而 nginx 占用链接的内存比较小,而且处理并发能力更强。
nginx 收到代理服务器的响应内容会边缓存边发送给客户端。
我会列举一些我了解并常用的配置。
proxy_buffering
# 启用代理代理服务器缓冲,默认开启
proxy_buffering on;
启用缓存时,nginx 会尽可能接受来自代理服务器响应,将其保存至 proxy_buffer_size 和 proxy_buffers 指令设置的缓冲区中。内存如果放不下整个响应的话,会将一部分内容写入到临时文件中。
proxy_buffer_size
| - | 说明 |
|---|---|
| 语法 | proxy_buffer_size size; |
| 默认 | proxy_buffer_size 4k | 8k; |
| 上下文 | http、server、location |
设置从代理服务器读取的响应头的缓冲区大小。默认情况下等于一个系统内存页大小。建议设置成内存页的整数倍,如果响应头比较大,可以修改此部分
# 获取内存页大小
getconf PAGESIZE
第一次测试,我返回 10m响应体。响应头很小,低于 4k。服务端的端口为 8087。
@GetMapping("/proxy")
public ResponseEntity<String> proxy(){
final String collect = Stream.generate(() -> {
return "a";
}).limit(1024*1024*10).collect(Collectors.joining());
return ResponseEntity.status(200).header("a","collect1").body(collect); } nginx 配置如下,浏览器请求 http://localhost:9092/test/proxy,请求成功。
server {
listen 9092 default_server;
location /test/ {
proxy_pass http://localhost:8087/; } } 第二次测试,我返回 10m 响应体,外加大于 4k 的响应头。请求失败。
@GetMapping("/proxy")
public ResponseEntity<String> proxy(){ final String collect = Stream.generate(() -> { return "a"; }).limit(1024*1024*10).collect(Collectors.joining()); final String collect1 = Stream.generate(() -> "b").limit(1024 * 5).collect(Collectors.joining()); return ResponseEntity.status(200).header("a",collect1).body(collect); } 将注释打开,才能访问成功
server {
listen 9092 default_server;
location /test/ {
proxy_pass http://localhost:8087/; #proxy_buffer_size 8k; } } proxy_buffers
| - | 说明 |
|---|---|
| 语法 | proxy_buffers number size; |
| 默认 | proxy_buffers 8 4k | 8k; |
| 上下文 | http、server、location |
设置单个连接从代理服务器读取响应的缓冲区的 number (数量)和 size (大小)。
默认情况下,缓冲区大小等于一个内存页。为 4K 或 8K,因平台而异。
避免设置 number 小,size 大的。比如 proxy_buffers 10 1m;
只需要满足缓冲区 number 乘 size 可以容纳响应体即可。
从上游的代理服务器读取的响应内容,会存到 proxy_buffers 设置的缓冲区中,写满一个缓冲区,继续写下一个。当缓冲区总大小容纳不下的时候,会写到临时文件中去。已经写过的缓冲区 (size)不会被操作,除非发送给客户端。
proxy_busy_buffers_size
| - | 说明 |
|---|---|
| 语法 | proxy_busy_buffers_size size; |
| 默认 | proxy_buffer_size 8k | 16k; |
| 上下文 | http、server、location |
proxy_busy_buffers_size 用于指定缓冲区(proxy_buffers 和 proxy_buffer_size)写入多大内容的时候往客户端发送。默认为 proxy_buffers 中 size 的两倍。
proxy_temp_file_write_size 一次写入临时文件的数据大小
| - | 说明 |
|---|---|
| 语法 | proxy_temp_file_write_size size; |
| 默认 | proxy_temp_file_write_size 8k | 16k; |
| 上下文 | http、server、location |
当缓冲区没法容纳从代理服务器返回的响应内容时,需要按照 proxy_temp_file_write_size 配置的 size 写入临时文件中
proxy_temp_path 定义临时文件的目录
需要注意的是,worker 进程要有读写临时目录的权限,否则会丢失数据。
| - | 说明 |
|---|---|
| 语法 | proxy_temp_path path [level1 [level2 [level3] ] ] |
| 默认 | proxy_temp_path proxy_temp; |
| 上下文 | http、server、location |
proxy_temp_path /spool/nginx/proxy_temp 1 2;
proxy_pass
| - | 说明 |
|---|---|
| 语法 | proxy_pass URL; |
| 默认 | - |
| 上下文 | http、server、location |
默认情况下,反向代理不会转发请求头 Host,如果需要转发需要配置
proxy_set_header Host $host;
设置代理的 URL。会将匹配的 location 路径替换成指定的 URL。
<font color=red>注意这里 proxy_pass 是否以 / 结尾,处理是不一样的。</font>
server {
listen 80;
location /api/flyyou/ {
proxy_pass http://localhost:8080; } } 访问 http://localhost:80/api/flyyou/a 会转发到 http://localhost:8080/api/flyyou/a
proxy_pass 不以 / 结尾,会将匹配的路径追加到代理去。
都以 / 就是替换,就是替换处理。
server {
listen 81;
location /api/flyyou/ {
proxy_pass http://localhost:8081/; } } 访问 http://localhost:81/api/flyyou/a 会转发到 http://localhost:8081/a
proxy_set_header 传递请求头到代理服务器
| - | 说明 |
|---|---|
| 语法 | proxy_pass_header name value; |
| 默认 | - |
| 上下文 | http、server、location |
proxy_set_header test1 $remote_addr;
proxy_set_header Host $proxy_host;
proxy_set_header Connection close; proxy_pass_request_body 设置是否传递请求体到代理服务器
| - | 说明 |
|---|---|
| 语法 | proxy_pass_request_body on | off; |
| 默认 | proxy_pass_request_body on; |
| 上下文 | http、server、location |
proxy_pass_request_headers 是否将原始请求的请求头传递给代理服务器
| - | 说明 |
|---|---|
| 语法 | proxy_pass_request_headers on | off; |
| 默认 | proxy_pass_request_headers on; |
| 上下文 | http、server、location |
ngx_http_proxy_module 模块支持内嵌变量
$proxy_host
proxy_pass 指令中指定的代理服务器的名称和端口
$proxy_port
proxy_pass 指令中指定的代理服务器的端口或协议的默认端口
$proxy_add_x_forwarded_for
X-Forwarded-For 客户端请求头字段,其中附加了 $remote_addr 变量,以逗号分割。
如果客户端请求头中不存在 X-Forwarded-For 字段,则变量等于 $remote_addr 变量。
总结
nginx 作为代理服务器的时候,并发大的时候还是比较占用内存的。但是服务器的内存还要预留一部分给系统调用。
以下设置是针对每一个请求的。
# 大于响应头即可,设置为内存页大小的倍数,getconf PAGESIZE 获取内存页大小
proxy_buffer_size 4k;
# 设置大于响应体内容大小即可,在日志记录中看发送响应大小或估算,注意 size 不要设置的太大
proxy_buffers 32 8k; # 设置为 proxy_buffers 中 size 的 2 倍 proxy_busy_buffers_size 16k; # 设置和 proxy_busy_buffers_size 一样大小 proxy_temp_file_write_size 16k; # 为了便于查找文件,可以设置临时文件目录 proxy_temp_path /var/nginx/proxy_temp; 获取用户真实 ip
当我们访问一个资源的时候,可以使用命令 traceroute mflyyou.cn 查看经过了哪些网关。网络运营商不会为每一个用户分配公网 ip,会有一个内网路由将一部分用户的请求分发到一个公网 ip 上去。我们能获取到的就是这个 公网 ip。
有的时候我们不单单要知道用户从哪个 ip 访问的,还想知道,中间经过了哪些代理 ip。
我使用了两个 nginx 和一个 java 后端服务。
本地 Nginx => 公网 Nginx => 后端服务。
本地 nginx 配置
server {
listen 9092 default_server;
location /test/ {
proxy_pass http://mflyyou.cn/mytest/; proxy_buffer_size 8k; # 记录的是用户经过了哪些 ip proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; } } 公网 nginx 配置
location /mytest/api/{
# 记录的是用户建立公网链接时的 ip
proxy_set_header X-REAL-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_pass http://localhost:8087/; } 后端 java 服务
@GetMapping("/ip")
public IpData getIPData(HttpServletRequest request){
final String header = request.getHeader("X-Forwarded-For");
final String realIp = request.getHeader("X-REAL-IP"); final IpData ipData = new IpData(); ipData.setXForwardFor(header); ipData.setXRealIp(realIp); return ipData; } 当我本地访问 http://localhost:9092/test/api/ip
{"xforwardFor":"127.0.0.1, 155.10.116.110","xrealIp":"155.10.116.110"}
基于代理的负载均衡
简单负载均衡
nginx 支付的负载均衡策略有:
- 轮询(round-robin) - 发送给应用服务器的请求以轮询的方式分发
- 最少连接(
least_conn) - 下一个请求被分配给具有最少数量活动连接的服务器 - ip 哈希(
ip_hash) - 使用哈希函数确定下一个请求应该选择哪一个服务器(基于客户端 的 IP 地址)
默认轮训策略。
以下配置可以作为研究使用,实际生产不会这样配置的,一般都会转发到不同的服务器上去。
upstream passserver2 {
# ip_hash;
# least_conn;
server 127.0.0.1:8081; server 127.0.0.1:8082; server 127.0.0.1:8083; } server { listen 9088 default_server; server_name localhost; location / { proxy_pass http://passserver2; } } server { listen 8081 default_server; server_name localhost; location =/api { add_header Content-Type application/json; return 200 "我是 8081 服务器"; } } server { listen 8082 default_server; server_name localhost; location =/api { add_header Content-Type application/json; return 200 "我是 8082 服务器"; } } server { listen 8083 default_server; server_name localhost; location =/api { add_header Content-Type application/json; return 200 "我是 8083 服务器"; } } server
| - | 说明 |
|---|---|
| 语法 | server address [parameters]; |
| 默认 | - |
| 上下文 | upstream |
我们也可以通过 parameters 给应用服务器设置更细粒度的控制。
有一些参数需要商用 nginx 才能使用,我就没有列出来。
weight 控制权重
weight=number;
weight 默认为 1。通过设置权重,会让某个服务有更多的概率处理请求。
通常可以将服务器配置比较高的服务器设置的权重更大。
8081 会有 3/6 的概率。
8082 会有 2/6 的概率。
8083 会有 1/6 的概率。
upstream passserver2 {
server 127.0.0.1:8081 weight=3;
server 127.0.0.1:8082 weight=2; server 127.0.0.1:8083; } max_fails 配置允许的失败次数
max_fails=number
默认为 1。需要与 fail_timeout 配合使用。表示 fail_timeout 内允许的失败次数,超过之后,就不会分配请求。
upstream passserver2 {
server 127.0.0.1:8081 weight=3 max_fails=3 fail_timeout=15; server 127.0.0.1:8082 weight=2; server 127.0.0.1:8083; } fail_timeout
fail_timeout=time
默认 10 秒。
upstream passserver2 {
server 127.0.0.1:8081 weight=3 max_fails=3 fail_timeout=15; server 127.0.0.1:8082 weight=2; server 127.0.0.1:8083; } backup 设置备用机
当别的服务器都挂了之后才会启动服务。
8081 和 8082 都挂掉之后,8083 才开始提供服务。
upstream passserver2 {
server 127.0.0.1:8081 weight=3 max_fails=3 fail_timeout=15; server 127.0.0.1:8082 weight=2; server 127.0.0.1:8083 backup; } max_conns 限定服务器的最大连接数
max_conns=number
指定某个服务器的最大连接数,超过这个数,不会分配新的请求,除非低于这个数。
upstream passserver2 {
server 127.0.0.1:8081 weight=3 max_fails=3 fail_timeout=15; server 127.0.0.1:8082 weight=2 max_conns=1000; server 127.0.0.1:8083 backup; } 本文由 张攀钦的博客 http://www.mflyyou.cn/ 创作。 可自由转载、引用,但需署名作者且注明文章出处。
如转载至微信公众号,请在文末添加作者公众号二维码。微信公众号名称:Mflyyou

来源:锌闻网
推荐:餐饮品牌设计