贝叶斯分类是一种统计学分类方法,在分类问题中表现出良好的性能。很明显朴素贝叶斯基于贝叶斯定理,下面来简单复习下贝叶斯定理。
在说之前我们来看下条件概率的计算,所谓"条件概率"(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
现在需要计算在事件B发生的情况下,事件A发生的概率。

有了这个之后,我们可以对对条件概率公式进行变形,可以得到如下形式:
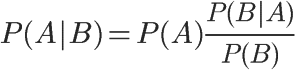
在贝叶斯法则中,每个名词都有约定俗成的名称:
P(A)是A的先验概率或边缘概率。之所以称为"先验"是因为它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B|A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
P(B)是B的先验概率或边缘概率,也作标准化常量(normalized constant)。
按这些术语,Bayes法则可表述为:
后验概率= (相似度 *先验概率)/标准化常量
也就是说,后验概率与先验概率和相似度的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准相似度(standardised likelihood),Bayes法则可表述为:后验概率 = 标准相似度 * 先验概率
贝叶斯法则(Bayes'theorem/Bayes theorem/Bayesian law) 贝叶斯的统计学中有一个基本的工具叫“贝叶斯法则”, 尽管它是一个数学公式,但其原理毋需数字也可明了。如果看到一个人总是做一些好事,则那个人多半会是一个好人。这就是说,当不能准确知悉一个事物的本质时,可以依靠与事物特定本质相关的事件出现的多少去判断其本质属性的概率。 用数学语言表达就是:支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
对贝叶斯定理有了些印象之后,我们很快就会问为什么有个朴素贝叶斯。朴素贝叶斯分类假定一个属性值对于给定类的影响独立于其他属性值。这一假定称作类条件独立。做此假设显然是为了方便简化计算,并在此意义下称为“朴素的”(Native,原生的,简单的)。下面来说说朴素贝叶斯分类器的学习过程。
整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。