机器学习复习
1 - 下面是你在课程中看到的代码,在哪种情况下你会使用二值交叉熵损失函数?
model.compile(loss=BinaryCrossentropy())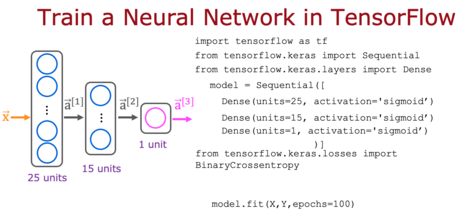
A. 回归任务(预测一个数字的任务)
B. BinaryCrossentropy()不应该被用于任何任务
C. 有3个或更多类(类别)的分类任务
D. 二分类(正好有2个类的分类)
答案:D
2 - 下面代码中的哪一行执行了参数更新
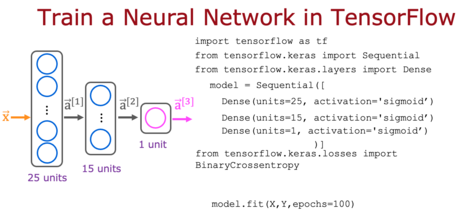
model = Sequential([
Dense(units=25, activation='sigmoid’),
Dense(units=15, activation='sigmoid’),
Dense(units=1, activation='sigmoid’)
])
model.compile(loss=BinaryCrossentropy())
model.fit(X,y,epochs=100)A. model.fit(X,y,epochs=100)
B. 都没有执行
C. model = Sequential([...])
D. model.compile(loss=BinaryCrossentropy())
答案:A
3 - 对于神经网络的隐藏层,下面哪一个激活函数是最常用的?
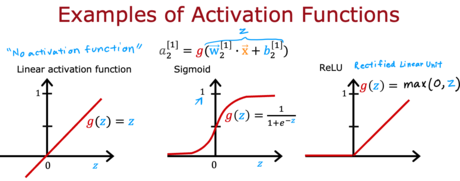
A. 大多数隐藏层不使用激活函数
B. Linear
C. ReLU
D. Sigmoid
答案:C
4 - 对于房价预测任务,你会选择哪个激活函数(选择两个)。
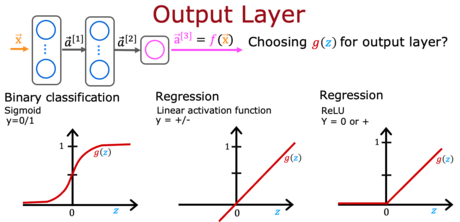
A. ReLU
B. Sigmoid
C. linear答案:BC
5 - 一个有很多层但没有激活函数(在隐藏层)的神经网络是无效的;这就是为什么我们应该在每个隐藏层使用线性激活函数。
A. 错
B. 对
答案:错
6 - 对于一个有4个可能输出的多分类任务,所有激活的总和加起来是1。对于一个有3个可能输出的多类分类任务,所有激活的总和应该加到......?

A. 1
B. 少于1
C. 大于1
D. 会随着输出x的值而变化
答案:A
7 - 对于多分类,交叉熵损失被用于训练模型。如果输出有4个可能的类别,对于一个特定的训练例子,该例子的真实类别是第3类(y=3),那么交叉熵损失简化为什么?
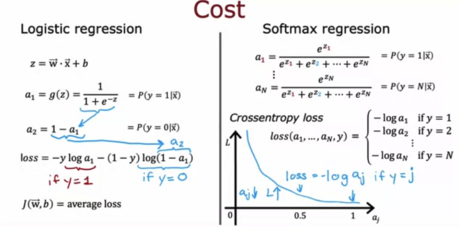
A. \(-\log \left(a_{3}\right)\)
B. \(\frac{-\log \left(a_{1}\right)+-\log \left(a_{2}\right)+-\log \left(a_{3}\right)+-\log \left(a_{4}\right)}{4}\)
C. \(z_3\)
D. \(\frac{z_3}{z_1 + z_2 + z_4}\)
答案:A
8 - 对于多分类,实现softmax回归的推荐方法是在损失函数中设置 from_logits=True,同时在模型的输出层中定义... ...?

A. 一个Linear激活
B. 一个Softmax激活
答案:A
9 - Adam优化器是推荐的优化器,用于寻找模型的最佳参数。如何在TensorFlow中使用Adam优化器?

A. 对model.compile()的调用会自动选择最佳优化器,不管是梯度下降、Adam还是其他。所以不需要手动选择优化器
B. Adam优化器只对Softmax输出起作用。因此,如果一个神经网络有一个Softmax输出层,TensorFlow将自动选择Adam优化器
C. 在调用model.compile时,设置优化器=tf.keras.optimizers.Adam(learning_rate=1e-3)
D. 对model.compile()的调用默认使用Adam优化器
答案:C
10 - 课程讲座中涉及到一种不同的层类型,该层的每个单一神经元都不看输入到该层的所有输入向量的值。讲座中讨论的这个层类型的名称是什么?
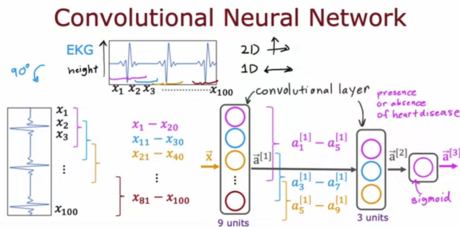
A. 卷积层
B. 全连接层
C. 图像层
D. 一维或二维层(根据输出维度)
答案:A