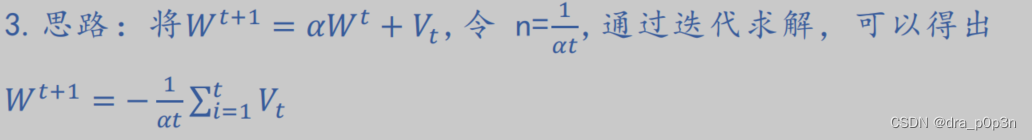主成分分析(PCA)
原理

当样本数远小于特征数怎么办

与奇异值分解的异同

CNN
卷积和池化工作原理

池化也叫子采样

CNN过拟合风险措施

SGD


核方法
核方法是一类把低维空间的非线性可分问题,转化为高维空间的线性可分问题的方法。核方法的理论基础是Cover’s theorem,指的是对于非线性可分的训练集,可以大概率通过将其非线性映射到一个高维空间来转化成线性可分的训练集。
K-means和谱聚类
kmeans是一种基于距离的聚类算法,它将数据点划分为k个簇,使得每个簇内的数据点与其质心(簇内数据点的平均值)的距离之和最小。
谱聚类是一种基于图论的聚类算法,它将数据点看作图中的节点,根据数据点之间的相似度构建一个邻接矩阵,然后通过对邻接矩阵进行特征分解,得到一个低维空间中的嵌入表示,再在这个空间中用kmeans进行聚类。
kmeans和谱聚类各有优缺点:
- kmeans优点:简单、快速、易于实现;缺点:需要预先指定k值;对异常值敏感;假设簇是球形或圆形;对初始质心选择敏感;可能陷入局部最优解。
- 谱聚类优点:不需要预先指定k值;对异常值不敏感;不假设簇是特定形状;能够发现非凸或连通性强的簇;缺点:计算量大,需要存储和分解邻接矩阵;对相似度度量选择敏感;可能受到噪声或重复值的影响。
数据有m种表示,如何设计融合这些不同特征的聚类算法



感知机
迭代上界计算

处理非线性可分数据

SVM
使用核函数SVM的原始优化目标是:
min w , b 1 2 ∣ w ∣ 2 + C ∑ i = 1 n ξ i \min_{w,b} \frac{1}{2} |w|^2 + C \sum_{i=1}^n \xi_i \ w,bmin21∣w∣2+Ci=1∑nξi
s . t . y i ( w ⊤ ϕ ( x i ) + b ) ≥ 1 − ξ i , i = 1 , … , n ξ i ≥ 0 , i = 1 , … , n s.t. y_i (w^\top \phi(x_i) + b) \geq 1 - \xi_i, i = 1,\dots,n \ \xi_i \geq 0, i = 1,\dots,n s.t.yi(w⊤ϕ(xi)+b)≥1−ξi,i=1,…,n ξi≥0,i=1,…,n
其中 ϕ ( x ) \phi(x) ϕ(x)表示将 x x x映射后的特征向量。
推导其对偶形式如下:
首先构造拉格朗日函数:

随机梯度下降算法以高效地求解大规模核SVM对偶问题的思路如下: