论文:Convolutional Neural Networks with Alternately Updated Clique
论文链接:https://arxiv.org/abs/1802.10419
代码链接:https://github.com/iboing/CliqueNet
这篇文章是CVPR2018的oral,提出了一个新的网络结构,旨在进一步提高网络特征的利用率。该网络的思想是:在一个block中,每一层即是其他层的输入,也是其他层的输出。如何做到在一个block中每一层即是其他层的输入,又是其他层的输出?原文表述如下:Concretely, the several previous layers are concatenated to update the next layer, after which, the newly updated layer is concatenated to re-update the previous layer, so that information flow and feedback mechanism can be maximized. 后面会详细介绍。
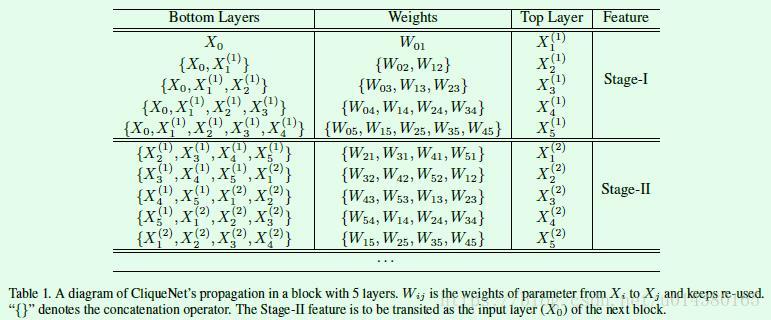
Figure1是一个包含4个网络层的block示意图,unfold的形式结合后面的Table1和公式1会更容易理解。两个概念:一个是block,一个block可以包含多个stage;另一个是stage,表示参数更新的不同阶段。Figure1中一个block包含两个stage,stage-I是首次更新,stage-II是第二次更新。熟悉DenseNet网络结构的同学应该可以看出Stage-I的操作和DenseNet是一样的,也就是说前面层的输出concate在一起作为当前层的输入。Stage-II的输入则可以从公式1和Table1看出规律:其他层最新的输出。

Table1是一个包含5个网络层的block示意图,X代表层输出,右上角的(1)或(2)表示stage-I或stage-II。Stage-I的操作和DenseNet类似,Stage-II则是不断用top layer中最新的其他4个层输出作为另一个层的输入去更新对应的权重W。
前面介绍的这些操作可以用公式来表达,如下所示,公式1表示Clique Block的操作,Xi(k)中的(k)表示stage k,和Table1对应。该公式和前面Figure1和Table1结合看容易理解,公式分两部分,前半部分是相同stage的前面层输出集合作为当前层的输入,后半部分是前stage的后面层输出集合作为当前层的输入。注意这两部分不是前面介绍的两个stage的含义。

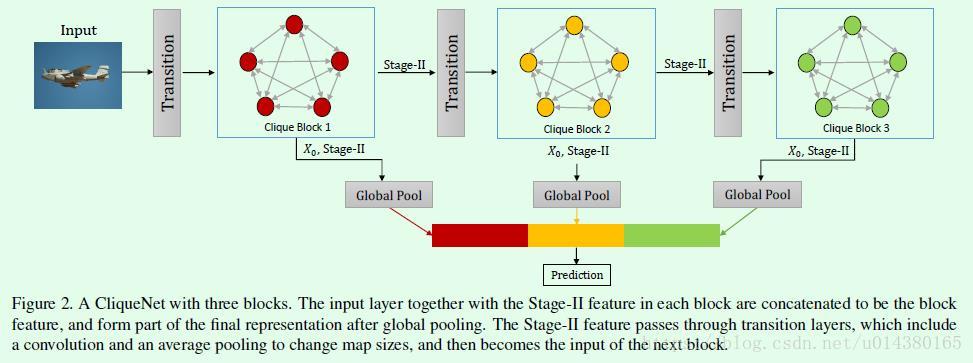
Figure2表示包含3个block的CliqueNet,每个block都会有两个输出:X0和stage-II的输出,这二者通过concate后再接一个global pooling层,作为预测的一部分。因此每个block的输出是该block的输入和该block的stage-II的输出的concate结果。X0表示第一个block的输入,后续每个block的输入是前一个block的stage-II输出经过transition层后得到的结果。文章中提到的一个亮点是:We adopt a multiscale feature strategy to compose the final representation with the block features in different map sizes. 指的就是这里不同block的输入做concate去预测结果。另外要提到的是连接两个block的transition操作,文章采用的是attentional transition(类似SE-Net网络的做法),目的是使得传给下一个block的特征质量更高。
attentional transition结构如Figure4所示,和SE-Net的思想非常像,其含义就是基于W*H*C的feature map生成1*1*C的attention,该1*1*C的attention的每个值都是0到1的概率,用来表征每个channel的重要性,将1*1*C的attention和W*H*C的feature map做点乘就得到attentional transition后的输出feature map。

Table3是作者在ImageNet数据集上用的CliqueNet网络结构图。主要包含4个block,每个block中的两个数字(比如block1中的36*5,表示S0有5个layer,每个layer的卷积核数量是36)。S0、S1、S2、S3表示不同层数配置的网络,因此Table3一共包含4种CliqueNet,比如CliqueNet-S1,CliqueNet-S2等。每个block之间都采用transition连接。

实验结果:
Table4是在CIFAR-10、CIFAR-100和SVHN数据集上的结果对比,这里CliqueNet网络均采用3个block,可以看出CliqueNet在减少网络参数的同时降低了错误率。

Table5是在ImageNet数据集上的结果对比。对于浅层网络的改进要优于深层网络,作者在文章中提到一部分原因是因为硬件资源的限制(只有4块GPU机器),因此无法设置较大的batch size。参数减少方面是挺明显的,主要原因在于传给每个block的feature map的维度都不算大。

Figure5是对DenseNet网络和CliqueNet网络的不同层之间的参数权重分析,可以看出在DenseNet中,相邻层之间的权重值比较大,也就是相互之间的信息传递较多。而在CliqueNet中,不同层之间的信息传递要分散和均匀一些。

最后这个图Figure6也非常有意思,是对stage-I和stage-II的特征做可视化,可以看出stage-II的特征更加集中在目标区域。
