参考:
- d2l
- 今日学习——卷积神经网络(CNN)
https://blog.csdn.net/m0_61165991/article/details/124176077 - 图像工程(上册)-图像处理
- 傅里叶变换
https://blog.csdn.net/qq_43369406/article/details/131350139 - CNN卷积神经网络基础知识
https://blog.csdn.net/qq_43369406/article/details/127134277
x.1 前储知识(optional可跳过)
x.1.1 信号处理
x.1.2 数字图像处理
参考图像工程(上册)-图像处理
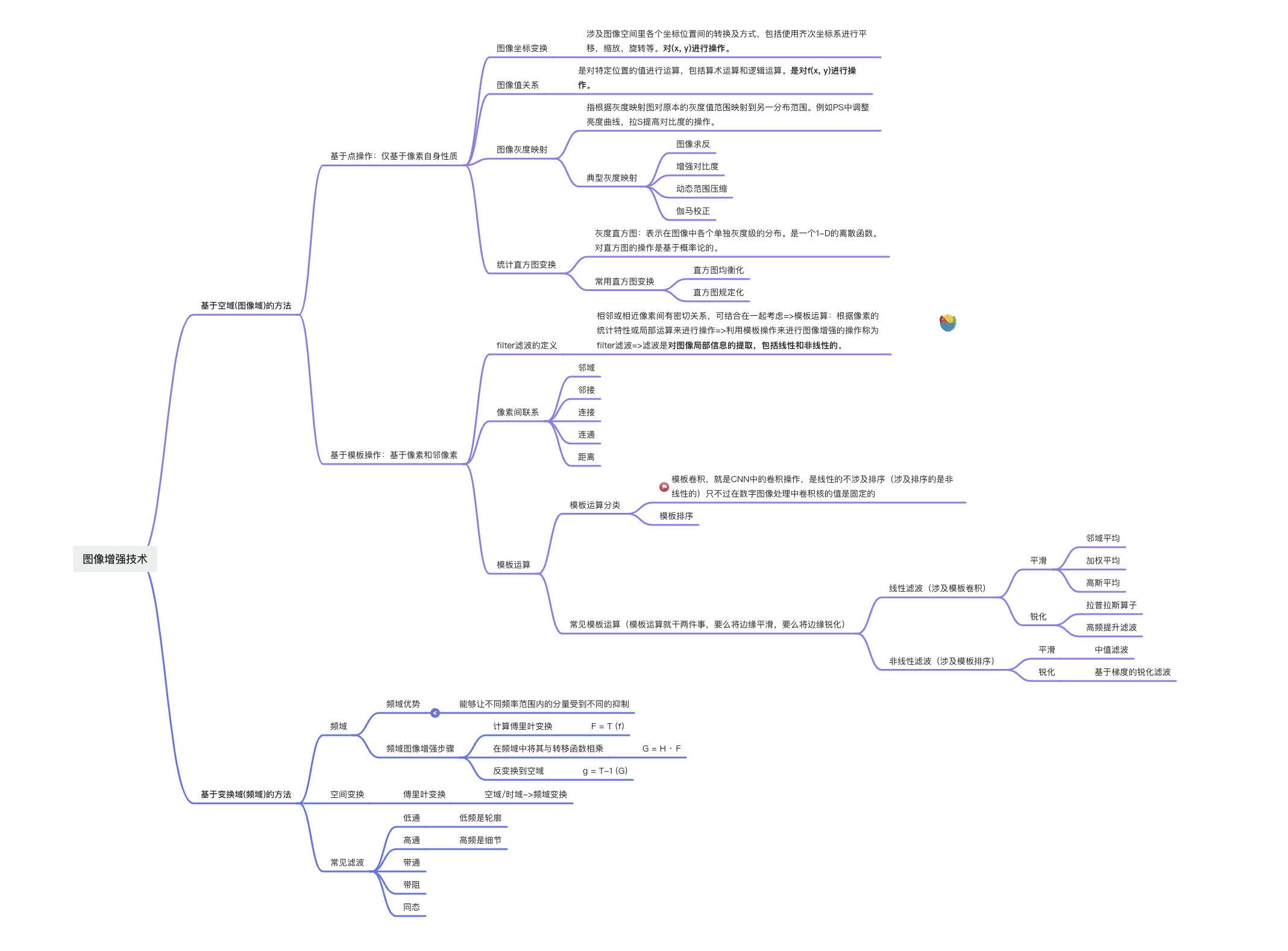
x.1.2.1 空域/时域
x.1.2.2 傅里叶变换
参考傅里叶变换 https://blog.csdn.net/qq_43369406/article/details/131350139
x.1.2.3 频域
x.2 filter/kernel例子,二维卷积
filter滤波器/kernel卷积核的概念的由来是信号处理和数字图像处理技术,卷积就类似空域中的模板卷积,下面来举一个边缘检测的小例子,
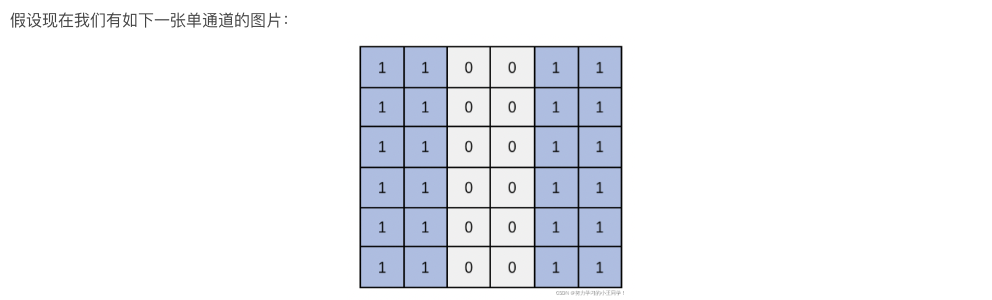
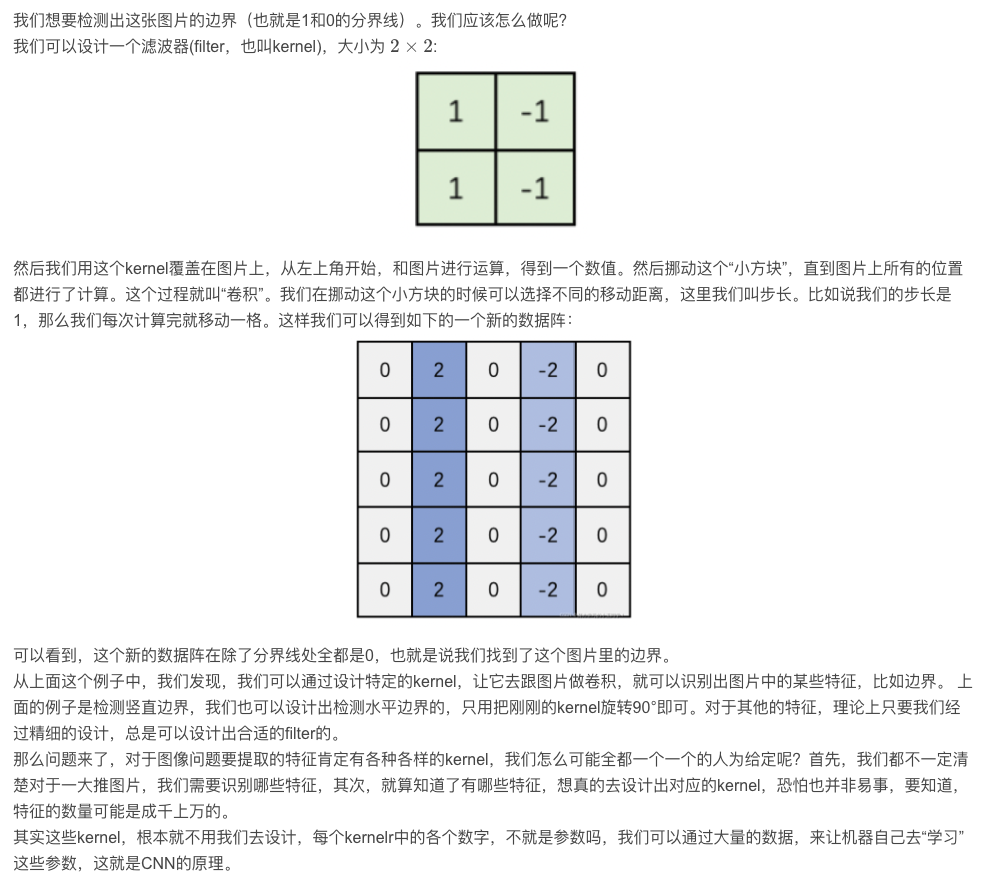
上面这个操作,也就是我们常说的2-D卷积的操作,参看卷积是什么https://blog.csdn.net/qq_43369406/article/details/131351280
x.3 From Fully Connected Layers to Convolutions
x.3.1 CNN和图像的性质
我们学习了线性模型,非线性模型如MLP,MLP适合处理表格数据,行对应样本,列对应特征,对于表格类数据我们使用MLP来寻找特征间交互的通用模式(PR)。我们也可以将多张图片展平为多个一维向量后传入MLP训练,但是这会忽略每张图片的空间结构信息,例如第一行第一个像素和第二行第一个像素它们是相邻的,但是展平为一维向量后,我们往往会丢失这一层关系。
为了更好利用相邻像素间的相互关联性这一先验知识,诞生了convolutional neural network, CNN, 卷积神经网络。CNN具有如下优点:
- CNN需要的参数少于Full Connect Neural Network(FCNN)
- 卷积易于用GPU并行计算
- CNN适合图像
卷积神经网络的提出需要具有两种假设,translation invariance平移不变性,locality局部性,这些性质都可以在下图中寻找特定人Waldo得到体现
- translation invariance: 不管检测对象出现在图像中的那个位置,神经网络的前面基层应该对相同的图像区域具有类似的反应。
- locality: 神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系。

x.3.2 卷积操作
我们参考数学中的卷积,再不进行翻转的情况下只考虑互相关运算;在考虑局部性质后,我们只选取小于原图大小的尺寸较小的卷积核,即限制在2 delta的范围;考虑多个通道的存在我们引入四维表示,第一第二纬度是长宽,第三纬度(输入通道数),第四维度(输出通道数)。最终我们得到卷积计算公式如下(严格意义上讲是cross-correlation互相关计算公式后再加上bias偏置),式中V是卷积核值,X是输入特征矩阵值,H是输出特征矩阵值,u是bias:
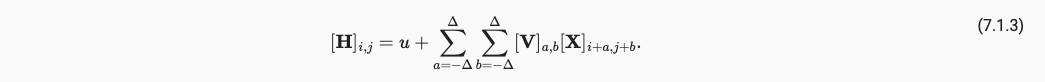
我们可以更改卷积核中的参数以达到不同效果,如平滑或者锐化。而CNN则是将卷积核中参数设置为可学习的,通过将输出特征矩阵和label进行运算,反向传播卷积核中的参数,以使得CNN模型能够达到在图像中找到我们所需要的物体的结果。
x.3.3 receptive field
在CNN中,互相关运算称为卷积运算;卷积核张量上的权重称为元素。
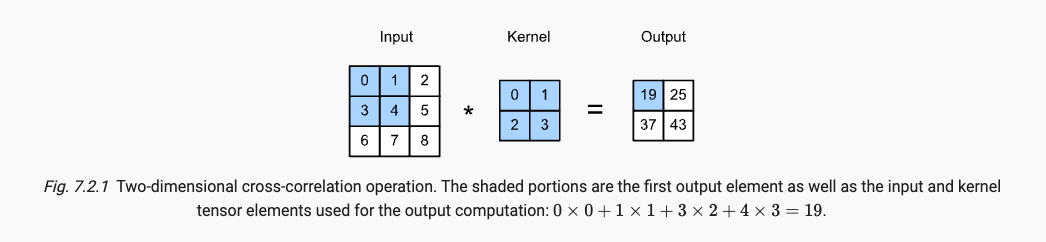
receptive field感受野,指的是:对于某一层的任意元素x,其感受野指在forward propagation, FP前向传播期间可能影响该层元素x计算的所有元素,来自于前面的所有层。例如在上面的output中19的感受野就是input的四个位置元素。
x.4 kernel_size, stride, padding
对于卷积神经网络我们需要注意以下信息:
- Pytorch中特征矩阵排列顺序如下(Batch_size, Channel, Height, Width),后简写为(B, C, H, W)。如果三维则为(B, C, S, H, W), S represents Slice。kernel_size是卷积核大小,kernel_size是卷积核个数,H_out为输出特征矩阵高,H_in为输入特征矩阵高。stride为步幅,padding为填充。
- stride是每一步走多远
- padding填充的是0,默认是上下左右都会填充。
- 卷积核纬度等于输入特征矩阵维度
- 输出特征矩阵维度等于卷积核个数
- 卷积核参数个数计算公式为
(kernel_size*kernel_size*C+1)*kernel_num。kernel_size*kernel_size*C是weight参数,1是bias参数,一个卷积核可能有多个维度,但是只有一个偏置。 - 输出特征矩阵大小计算公式为
H_out = (H_in - kernel_size + padding)/stride + 1 - 在dense net中常用的不改变输出特征矩阵大小的卷积核参数:3, 1, 1; 1, 1, 0; 对应关系为kernel_size, stride, padding.
如下,是一个二维输入特征矩阵,个数为1的卷积核。
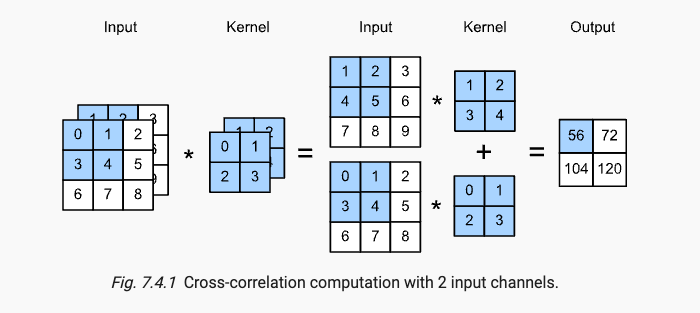
x.5 pooling 汇聚/池化层
卷积汇聚虽然都可以进行下采样,但是他们的区别如下:
- 卷积在下采样的同时可以对特征进行提取,运行速度会慢一些,参数需要学习
- 池化进行下采样只能进行特征降维,运行速度快,参数不需要学习
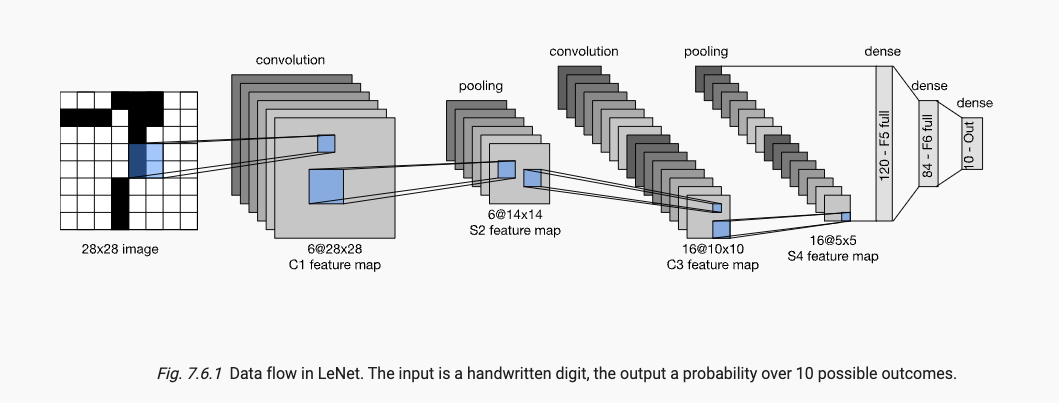
x.6 LeNet
data flow数据流向如下:
参考代码如下:
https://github.com/yingmuzhi/deep_learning/tree/main/chapter7