第七章其他神经网络类型
理解Elman神经网络
理解Jordan神经网络
ART1神经网络
不断发展的NEAT
到目前为止在这本书中我们主要看了前馈神经网络,神经网络中的所有连接并不是都需要前馈。还可以创建递归连接,本章将介绍允许创建一个递归连接的神经网络。
虽然ART1不是一个递归神经网络,我们也将看看ART1神经网络,这种网络类型很有趣,因为它不像大多数其他神经网络一样,它没有一个明显的学习阶段,ART1神经网络学习它的识别模式,这样不断的学习,就像人的大脑。
这章将从Elman和Jordan神经网络开始,这些网络通常被称为简单递归神经网络(SRN)
7.1Elman神经网络
Elman神经网络和约旦神经网络是具有附加层的递归神经网络,其功能与前几章中的前馈网络非常相似。他们使用类似前馈神经网络的训练技术。
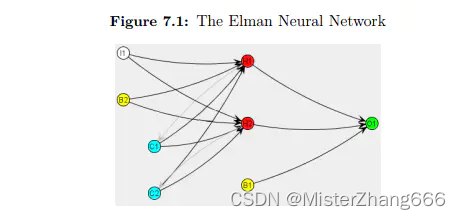
如图所示,Elman神经网络使用上下文神经元。它们被标记为C1和C2。上下文神经元允许反馈。反馈是前一次迭代的输出作为连续迭代的输入时使用的。注意,上下文神经元是从隐藏的神经元输出中提取的。这些连接没有权重。它们只是一个从隐藏神经元到上下文神经元的输出管道。上下文神经元记住这个输出,然后在下一次迭代中将其反馈给隐藏的神经元。
因此,上下文层总是向隐藏层反馈前面的迭代中自己的输出。从上下文层到隐藏层的连接是加权的。这个突触会随着网络的训练而学习。上下文层允许神经网络识别上下文。
要了解上下文对神经网络的重要性,请考虑以前的网络是如何训练的。训练集元素的顺序并不重要。训练集可以以任何需要的方式混乱,网络仍然以同样的方式训练。使用Elman或约旦神经网络,顺序变得非常重要。先前支持的训练集元素仍在影响神经网络。这对预测神经网络非常重要,使得Elman神经网络在时态神经网络中非常有用。
第8章将深入研究时态神经网络。时态网络试图查看数据的趋势并预测未来的数据值。前馈网络也可以用于预测,但输入神经元的结构不同。本章将重点讨论神经元是如何构造为简单递归神经网络的。Jeffrey Elman博士创建了Elman神经网络。Elman博士使用异或模式测试他的神经网络。但是,他没有使用我们前面章节中所看到的典型的XOR模式。他使用异或模式折叠到一个输入神经元。考虑下面的XOR真值表。
1.0 XOR 0.0 = 1.0
0.0 XOR 0.0 = 0.0
0.0 XOR 1.0 = 1.0
1.0 XOR 1.0 = 0.0
现在,把它折叠成一串数字。要做到这一点,只需一行一行地读左到右的数字。这产生如下:1.0 , 0.0 , 1.0 , 0.0 , 0.0 , 0.0 , 0.0 , 1.0 , 1.0 , 1.0 , 1.0 , 0.0
我们将创建一个神经网络,接受上面列表中的一个数字,并预测下一个数字。同样的数据将在本章后面的约旦神经网络中使用。此神经网络的样本输入如下:
Input Neurons : 1.0 ==> Output Neurons : 0.0
Input Neurons : 0.0 ==> Output Neurons : 1.0
Input Neurons : 1.0 ==> Output Neurons : 0.0
Input Neurons : 0.0 ==> Output Neurons : 0.0
Input Neurons : 0.0 ==> Output Neurons : 0.0
Input Neurons : 0.0 ==> Output Neurons : 0.0
训练一个典型的前馈神经网络是不可能的。培训信息将是矛盾的。有时0的输入结果是1,其他时间则是0。1的输入也有类似的问题。
神经网络需要上下文,它应该查看之前的内容。我们将回顾一个使用Elman和前馈网络来预测输出的例子。Elman神经网络的一个例子可以在下面的位置找到。org.encog.examples.neural.recurrant.elman.ElmanXOR
当我们运行时候,程序产生的输出如下:
Training Elman , Epoch #0 Error :0.32599411611972673
Training Elman , Epoch #1 Error :0.3259917385997097
Training Elman , Epoch #2 Error :0.32598936110238147
Training Elman , Epoch #3 Error :0.32598698362774564
Training Elman , Epoch #4 Error :0.32598460617580305
Training Elman , Epoch #6287 Error :0.08194924225166297
Training Elman , Epoch #6288 Error :0.08194874110333253
Training Elman , Epoch #6289 Error :0.08194824008016807
Training Elman , Epoch #6290 Error :0.08194773918212342…
Training Elman , Epoch #7953 Error :0.0714145283312322
Training Elman , Epoch #7954 Error :0.0714145283312322Training Elman , Epoch #7955 Error :0.0714145283312322Training Elman , Epoch #7956 Error :0.0714145283312322Training Elman , Epoch #7957 Error :0.0714145283312322Training Elman , Epoch #7958 Error :0.0714145283312322Training Elman , Epoch #7959 Error :0.0714145283312322Training Elman , Epoch #7960 Error :0.0714145283312322Training Feedforward , Epoch #0 Error :0.32599411611972673Training Feedforward , Epoch #1 Error :0.3259917385997097Training Feedforward , Epoch #2 Error :0.32598936110238147Training Feedforward , Epoch #3 Error :0.32598698362774564Training Feedforward , Epoch #4 Error :0.32598460617580305…Training Feedforward , Epoch #109 Error :0.25000012191064686Training Feedforward , Epoch #110 Error :0.25000012190802173Training Feedforward , Epoch #111 Error :0.2500001219053976Training Feedforward , Epoch #112 Error :0.25000012190277315Training Feedforward , Epoch #113 Error :0.2500001219001487Best errorrate with Elman Network : 0.0714145283312322Best errorrate with Feedforward Network : 0.2500001219001487
Elman应该能够进入10%范围,前馈不应该低于25%。在这种情况下递归Elment网能学的更好。如果你的结果不好,重新运行,或者训练更长时间。
你可以看到,该计划试图训练前馈和与时间异或数据Elman神经网络。前馈神经网络学不好的数据,但是Elman网络更好地学习。在这种情况下,前馈神经网络得到49.9%和Elman神经网络达到7%。上下文层帮助很大。本程序采用随机权值初始化神经网络。如果第一次运行时不会产生好的结果,重新运行。一个更好的起始重量可以有所帮助。
7.1.1创建Elman神经网络
在这个例子中,调用createElmanNetwork创建Elman神经网络,该方法显示如下:

正如你所见,从上面的代码中,事实上使用ElmanPattern创建Elman神经网络,这里提供了一个快速的方式构造一个Elman神经网络。
7.1.2训练Elman神经网络
Elman神经网络往往是特别容易陷入局部极小值。一个局部最小值是一个点,可导致培训停滞。可视化的权值矩阵和阈值与高山和峡谷视图。为得到最低的误差,你要找到最低的山谷。有时训练发现低谷,搜索附近这山谷附件想找到更低处。它可能找不到几英里远更低的山谷。
这个例子的训练使用几个策略训练有助于避免这种情况。本例的训练代码如下所示。同样的训练用于前馈和Elman神经网络,采用反向传播的一个非常小的学习速率。然而,添加一些训练的策略有很大的帮助。网络法的方法来训练神经网络。方法如下所示。

一个被该程序使用的策略是Hybridstrategy。如果主要培训技术停滞不前,这使得替代技术培训被应用。我们将使用模拟退火作为替代的训练策略。

你可以看到,我们使用基于对象的训练集的得分。关于模拟退火的更多信息,请参考6章,“更多的监督训练”。主要的训练方法是反向传播。

我们将使用一个StopTrainingStrategy告诉我们何时停止训练。误差率停滞时,stoptrainingstrategy将停止训练。默认情况下,停滞定义为小于0.00001%的改善超过100次。
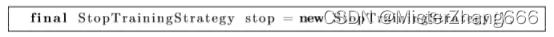
主训练技术添加策略:

我们还利用了贪婪的策略。此策略只允许迭代来改善神经网络的误差率。

循环继续,直到停止策略表明停止时间到。
7.2Jordan神经网络
Encog还包含了一个约旦的神经网络模式。约旦神经网络与Elman神经网络非常相似。图7.2显示了一个约旦神经网络。
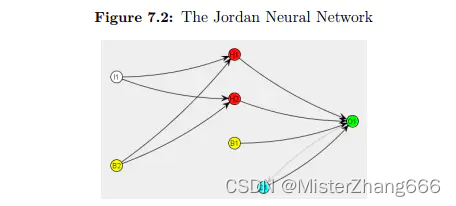
正如您所看到的,使用上下文神经元并标记为C1,类似于Elman网络。然而,输出层的输出被反馈回上下文层,而不是隐藏层。这种体系结构的微小变化可以使约旦神经网络更好地用于某些时序预测任务。
约旦神经网络和输出神经元有相同数量的上下文神经元。这是因为上下文神经元是由输出神经元提供的。异或运算符只有输出神经元。在使用约旦神经网络进行异或运算时,这将给您留下一个上下文神经元。约当网络在输出神经元较多的情况下工作更好。
构建约旦神经网络应使用JordanPattern。下面的代码演示了这一点。

上面的代码将创建一个类似图7.2的Jordan神经网络
Encog包括异或网络使用Jordan神经网络的例子。这个例子主要包括在XOR算子上比较Elman和约旦的完备性。如前所述,当输出神经元较多时,约旦倾向于做得更好。Jordan的encog异或实例将无法到达一个很低的误差率和没有明显优于前馈神经网络。约旦示例可以在以下位置找到。

在执行时,上面的例子将前馈到约旦,以相似的方式,如前面的例子。
7.3ART1神经网络
ART1神经网络自适应共振理论(ART)神经网络的一种类型。ART1,由Stephen Grossberg和Gail Carpenter开发的,只支持双极性输入。ART1神经网络进行训练,用于分类。新的模式提供给ART1网络被分为新的或现有的类。一旦使用了最大类数,网络将报告它已超出类数。
ART1网络似乎是一个简单的两层神经网络。然而,不像一个前馈神经网络的输入层和输出层之间的两个方向有权重。输入神经元用于提供模式给ART1网络。ART1采用双极性数字,所以每个输入神经元打开或关闭。一个值代表开,负值代表关。
输出神经元定义ART1神经网络识别的组。每个输出神经元代表一个组
7.3.1使用ART1神经网络
我们将看到如何利用ART1网络。这里给出的示例将创建一个网络,提供一系列模式来学习识别。此示例可在以下位置找到。
这个例子构建ART1网络。新的模式提供给这个网络来识别和学习。如果一个新的模式与前面的模式相似,那么新模式将被标识为属于原始模式的同一组。如果模式与前面的模式不相似,则创建一个新组。如果每个输出神经元已经有一个组,那么神经网络报告它不能学习更多的模式。这个例子的输出可以在这里看到。

上述结果表明,向神经网络输入了模式。右边数表示ART1网络放置模式到哪个组里。有些模式按以前的模式分组,而其他模式则形成新的组。一旦所有的输出神经元被分配到一个组,神经网络就不能学习更多的模式。一旦发生这种情况,网络报告所有类都已用尽。
首先,必须创建一个ART1神经网络。这可以用以下代码完成。

这将创建一个具有指定数量的输入神经元和输出神经元新ART1网络。在这里,我们创建了一个包含5个输入神经元和10个输出神经元的神经网络。这种神经网络将能够把输入分成10个集群。
因为输入模式存储为字符串数组,所以必须将它们转换为可以呈现给神经网络的布尔数组。因为ART1双极性,它只接受布尔值。下面的代码将每个模式字符串转换成布尔值数组。

模式存储在PATTERN数组中。转换后的模式将存储在boolean input数组中。
现在布尔数组表示输入模式,我们可以将模式呈现给神经网络来分类。这通过以下代码完成,从循环遍历每个模式开始:
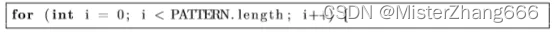
首先,我们创建一个bipolarneuraldata对象,持有输入模式。创建第二个对象保存来自神经网络的输出。
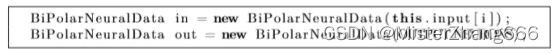
我们使用输入计算输出:

确定输出神经元是否获胜,如果是,就属于这个集群:

如果神经元没有获胜,打印一下。

ART1是一个网络可以用于飞行数据的聚类。没有明显的学习阶段;它聚类收到的数据。
7.4NEAT神经网络
扩张拓扑神经进化(NEAT)是一种进化神经网络的结构和权重的遗传算法。由得克萨斯大学奥斯汀分校的Ken Stanley开发。NEAT减轻了神经网络编程中神经网络隐层结构优化任务的繁琐程度。
一个NEAT神经网络有一个输入和输出层,就像更常见的前馈神经网络一样。一个NEAT网络只有输入层和输出层。其余的是随着训练的进展而演变的。NEAT神经网络内部的连接可以是前馈的、递归的或自连接的。所有这些连接类型都将被巧妙地尝试,因为它试图演化出一个能够完成给定任务的神经网络。
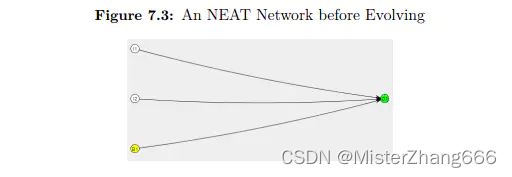
你可以看到,上述网络只有一个输入层和隐含层。这是不足以了解异或。这些网络的发展通过增加神经元和连接。图7.4显示了一个神经网络,进化过程的异或操作。
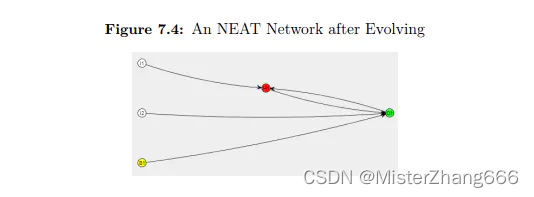
上述网络是从以前的网络演化而来的。在第一输入神经元和输出神经元之间添加一个附加的隐式神经元。此外,输出神经元又回到第一个隐神经元。这些小的补充允许神经网络学习XOR运算符。连接和神经元并不是唯一进化的事物。这些神经元之间的权重也在进化。
如图7.4所示,一个NEAT网络没有像传统的前馈网络那样有明确定义的层。有一个隐藏的神经元,但不是真正的隐藏层。如果这是一个传统的隐藏层,输入神经元将被连接到隐藏的神经元。
NEAT是一种复杂的神经网络类型和训练方法。此外,还有一个新版本NEAT,叫HyperNEAT,超出了这本书的范围。我会发布一本书注重NEAT和HyperNEAT的encog应用。本节将重点介绍如何使用NEAT作为前馈神经网络的一个潜在的替代,提供你所有的在Encog中用NEAT的关键信息。
7.4.1创建Encog NEAT群体
本节将展示如何使用一个NEAT网络来学习XOR运算符。在这个例子中,与前馈神经网络学习XOR运算符相比,代码差别很小。Encog的一个核心目标是让机器学习的方法,尽可能的可互换。
您可以在下面的位置看到这个示例。

这个例子首先创建一个XOR训练集,为神经网络提供XOR输入和期望输出。要检查XOR运算符的预期输入和输出,请参阅第3章。
接下来,创造一个NEAT群体。在此之前,我们创建一个单一的神经网络进行培训。NEAT需要创建一个完整的网络群体。这个群体将世代相传,产生更好的神经网络。只有适宜的群体才能培育出新的神经网络。

上述群体是由两个输入神经元,一个输出神经元和1000的群体规模创建的。群体越多,网络的训练就越好。然而,较大的群体会跑得慢,消耗更多的内存。
早些时候我们说过,只有适宜的群体才能繁衍后代。

最后一个必要步骤是为整洁的网络设置一个输出激活函数。这是不同于“”NEAT激活功能”,这通常是sigmoid或TANH。相反,这个激活函数应用于从神经网络读取的所有数据。
任何低于0.5的神经网络输出坐为0处理,0.5之上的作为1处理。这可以用步骤激活函数来完成,如下所示。

现在已经建立了群体,它一定要进行培训。
7.4.2训练Encog NEAT神经网络
训练一个NEAT神经网络同训练encog其他神经网络非常相似:创建一个培训对象开始遍历迭代。随着这些迭代的进展,群体中的神经网络的质量将会增加。
一个NEAT神经网络使用NEATTraining类训练。在这里你可以看到一个NEATTraining对象被创建。

对象训练群体到1%的错误率。

一旦群体训练,就能得到最好的神经网络。

建立了一个神经网络,必须测试它的性能,首先,清除之前运行的任意递归层。

现在,从神经网络中显示结果。

这将产生以下输出。

神经网络只进行了两次迭代来产生一个知道如何充当XOR运算符的神经网络。网络从上面的结果中学到了XOR运算符。只有当两个输入不是相同的值时,XOR才会产生1的输出。
7.5总结
虽然前面章节重点主要在前馈神经网络,但这章探索了一些其他Encog支持的网络类型,包括了Elman, Jordan, ART1和NEAT神经网络。
在这章中你学习到关于递归神经网络,这个包含了连接到前一层,Elman和Jordan神经网络使用了上下文层,上下文层允许他们学习跨越多个训练数据项的模式,它们对时序神经网络很有用。
ART1神经网络能够使用在学习二进制模式,不像其他神经网络,它没有明显的学习和使用状态,ART1神经网络学习使用它不需要训练状态。这模仿了人脑,人类在完成任务是学习一项任务。
本章也介绍了NEAT神经网络,NEAT网络没有隐藏层,像一个典型的前馈神经网络,一个NEAT只有输入和输出层,这个结构是对于隐藏神经元的演变,NEAT网络使用遗传算法训练。
在下一章我们将看看时序神经网络,一个时序神经网络尝试预测未来,这个类型的神经网络对于大量的字段比如金融,信号处理和商业业务很有用,下一章将展示怎样为神经网络预测未来构造输入数据。