权值更新
在前面的反向传播中我们计算出每一层的权值W和偏置b的偏导数之后,最后一步就是对权值和偏置进行更新了。
在之前的BP算法的介绍中我们给出了如下公式:
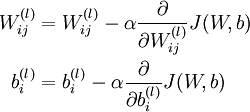
其中的α为学习速率,一般学习率并不是一个常数,而是一个以训练次数为自变量的单调递减的函数。使用变化的学习率有以下几点理由:
1、开始时学习率较大,可以快速的更新网络中的参数,是参数可以较快的达到目标值。而且由于每次更新的步长较大,可以在网络训练前期“跳过”局部最小值点。
2、当网络训练一段时间后,一个较大的学习率可能使网络的准确率不再上升,即“网络训练不动”了,这时候我们需要减小学习率来继续训练网络。
在我们的网络中,含有参数的层有卷积层1、卷积层2、全连接层1和全连接层2,一共有4个层有参数需要更新,其中每个层又有权值W和偏置b需要更新。实际中不管权值还是偏置,还有我们前面计算出了的梯度,都是线性存储的,所以我们直接把整个更新过程用到的数据看作对一维数组就可以,不用去关注权值W是不是一个800*500的矩阵,而且这样的话,权值更新和偏置更新的具体实现可以共用一份代码,都是对一维数组进行操作。
权值更新策略

caffe中的学习率更新策略
在\src\caffe\solvers\sgd_solver.cpp文件的注释中,caffe给出如下几种学习率更新策略:
- // Return the current learning rate. The currently implemented learning rate
- // policies are as follows:
- // - fixed: always return base_lr.
- // - step: return base_lr * gamma ^ (floor(iter / step))
- // - exp: return base_lr * gamma ^ iter
- // - inv: return base_lr * (1 + gamma * iter) ^ (- power)
- // - multistep: similar to step but it allows non uniform steps defined by
- // stepvalue
- // - poly: the effective learning rate follows a polynomial decay, to be
- // zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
- // - sigmoid: the effective learning rate follows a sigmod decay
- // return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
- //
- // where base_lr, max_iter, gamma, step, stepvalue and power are defined
- // in the solver parameter protocol buffer, and iter is the current iteration.
可以看出,学习率的更新有fixed、step、exp、inv、multistep、poly和sigmoid几种方式,看上边的公式可以很清楚的看出其实现过程。
实际中我们的网络使用的是inv的更新方式,即learn_rate=base_lr * (1 + gamma * iter) ^ (- power)。
Caffe中权值更新的实现
在配置文件\examples\mnist\lenet_solver.prototxt中,保存了网络初始化时用到的参数,我们先看一下和学习率相关的参数。
- # The base learning rate, momentum and the weight decay of the network.
- base_lr: 0.01
- momentum: 0.9
- weight_decay: 0.0005
- # The learning rate policy
- lr_policy: "inv"
- gamma: 0.0001
- power: 0.75
根据上面的参数,我们就可以计算出每一次迭代的学习率learn_rate= base_lr * (1 + gamma * iter) ^ (- power)。
获取学习率之后,我们需要使用学习率对网络中的参数进行更新。在\src\caffe\solvers\sgd_solver.cpp中包含了进行权值更新的具体函数ApplyUpdate(),下面我们介绍一下这个函数。
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
CHECK(Caffe::root_solver());
//GetLearningRate()函数获取此次迭代的学习率
Dtype rate = GetLearningRate();
if (this->param_.display() && this->iter_ % this->param_.display() == 0) {
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
}
ClipGradients();
//对网络进行更新,一共4个层,每层有W和b2个参数需要更新,故size=8
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
//归一化,我们的网络没有用到这一函数
Normalize(param_id);
//正则化
Regularize(param_id);
//计算更新用到的梯度
ComputeUpdateValue(param_id, rate);
}
//用ComputeUpdateValue计算得到的梯度进行更新
this->net_->Update();
}

void SGDSolver<Dtype>::Regularize(int param_id) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params();
const vector<float>& net_params_weight_decay =
this->net_->params_weight_decay();
Dtype weight_decay = this->param_.weight_decay();
string regularization_type = this->param_.regularization_type();
// local_decay = 0.0005 in lenet
Dtype local_decay = weight_decay * net_params_weight_decay[param_id];
...
if (regularization_type == "L2") {
// axpy means ax_plus_y. i.e., y = a*x + y
caffe_axpy(net_params[param_id]->count(),
local_decay,
net_params[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
}
...
}

void SGDSolver<Dtype>::ComputeUpdateValue(int param_id, Dtype rate) {
const vector<Blob<Dtype>*>& net_params = this->net_->learnable_params();
const vector<float>& net_params_lr = this->net_->params_lr();
// momentum = 0.9 in lenet
Dtype momentum = this->param_.momentum();
// local_rate = lr_mult * global_rate
// lr_mult为该层学习率乘子,在lenet_train_test.prototxt中设置
Dtype local_rate = rate * net_params_lr[param_id];
// Compute the update to history, then copy it to the parameter diff.
...
// axpby means ax_plus_by. i.e., y = ax + by
// 计算新的权值更新变化值 \delta w,结果保存在历史权值变化中
caffe_cpu_axpby(net_params[param_id]->count(), local_rate,
net_params[param_id]->cpu_diff(), momentum,
history_[param_id]->mutable_cpu_data());
// 从历史权值变化中把变化值 \delta w 保存到历史权值中diff中
caffe_copy(net_params[param_id]->count(),
history_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
...
}

caffe_axpy<Dtype>(count_, Dtype(-1),
static_cast<const Dtype*>(diff_->cpu_data()),
static_cast<Dtype*>(data_->mutable_cpu_data()));
在ComputeUpdateValue用到了lr_mult学习率因子参数,这个在之前的配置信息里面也见过,同一层中的weight和bias可能会以不同的学习率进行更新,所以也可以有不同的lr_mult。
最后this->net_->Update()函数使用前边ComputeUpdateValue计算出来的偏导数对参数进行了更新
layer {
name: "conv2_1/2/conv"
type: "Convolution"
bottom: "conv2_1/2/pre"
top: "conv2_1/2"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 24
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.1
}
pad_h: 1
pad_w: 1
kernel_h: 3
kernel_w: 3
stride_h: 1
stride_w: 1
}
}