网上介绍selenium的文章已经很多了, 这篇文章是一个持续更新的包,暂时用的人还不多—ichrome。
pip install ichrome
一、需求:解决阿里滑动验证问题。
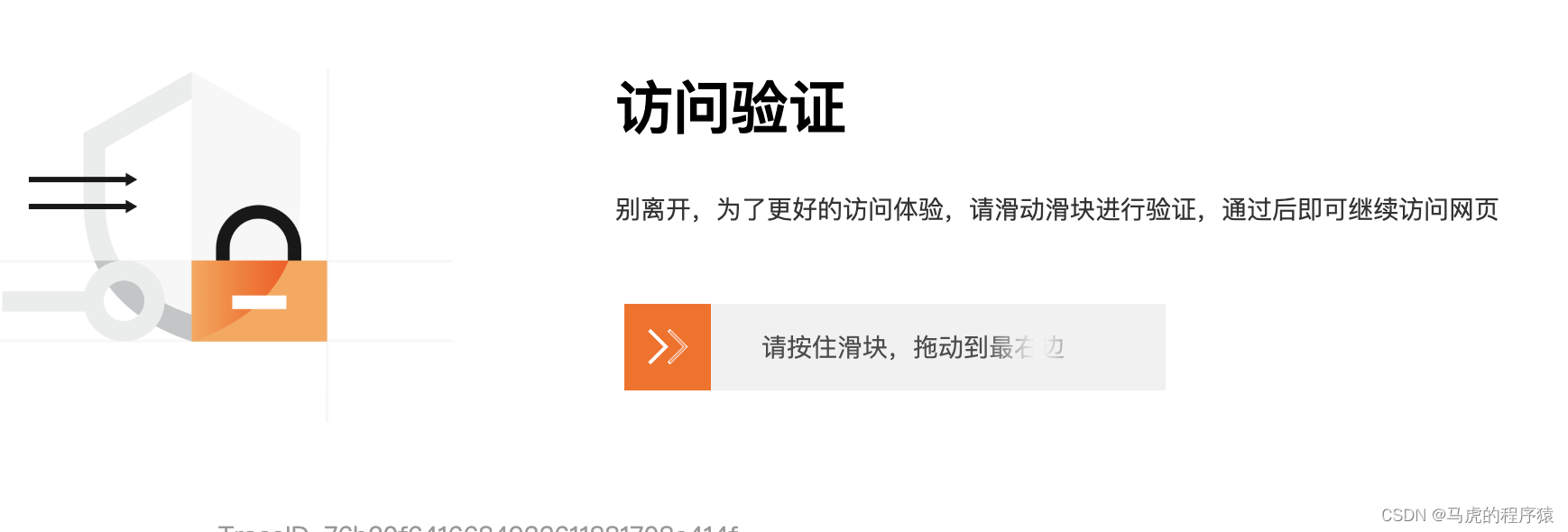
使用selenum访问时候配置liunx系统特别麻烦,注入JS也是无法通过验证。
二、话不多说上代码,异步启动:
asyncio.run(get_detail_anj())
三、pyautogui——进行滑动操作(单独写出来了,需要多次调用):
pip install pyautogui
# 因为需要代理,但是不知道怎么加,就只能这样加上去了。teb是启动的浏览器,循环最多十次跳出。
async def hdyz(tab):
n = 0
while True:
title = await tab.title
if title == '':
pyautogui.moveTo(860, 230)
pyautogui.click()
pyautogui.typewrite('账号')
time.sleep(1)
pyautogui.press('tab')
pyautogui.typewrite('密码')
pyautogui.press('Enter')
time.sleep(5)
elif "滑动验证页面" in title:
pyautogui.press('F5')
pyautogui.PAUSE = 1 # 调用在执行动作后暂停的秒数,只能在执行一些pyautogui动作后才能使用,建议用time.sleep
pyautogui.FAILSAFE = False
pyautogui.moveTo(880, 430, duration=0.5) # 定位元素 可以将x,y写入,duration 是移动时间
pyautogui.dragTo(random.randint(1190, 1220), random.randint(420, 440), duration=0.5, button='left')
elif "滑动验证页面" not in title:
time.sleep(10)
html = await tab.get_html(timeout=5) #给出html
break
elif '无法访问' in title or '无法连接':
break
n += 1
if n == 10:
break
return html
四、启动浏览器和输出部分:
async def get_detail_anj():
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/8"
"5.0.4183.102 Safari/537.36",
}
n = 1
while True:
try:
url = 'baidu.com'
proxyurl = f"{
'127.0.0.1':8000}" #代理
#headless为是否显示浏览器
async with AsyncChromeDaemon(headless=False, user_agent=headers, proxy=proxyurl) as cd:
async with cd.connect_tab(index=0) as tab:
for page in range(n, 1000):
url = url+page #页数
await tab.goto(requrl, timeout=5) #浏览器访问网页
html = await hdyz(tab) #调用滑动取出html
r = etree.HTML(html)
cookies = await tab.get_cookies() #还可以取出全部cookies
if not in html: #设置个xpath页数位了跳出
break
except:
# print('访问错误重新访问', url)
n = page
五、整合下代码:
import random
import asyncio
import re
import time
import pyautogui
import redis
import requests
from ichrome import AsyncChromeDaemon
from lxml import etree
async def hdyz(tab):
n = 0
while True:
title = await tab.title
if title == '':
pyautogui.moveTo(860, 230)
pyautogui.click()
pyautogui.typewrite('账号')
time.sleep(1)
pyautogui.press('tab')
pyautogui.typewrite('密码')
pyautogui.press('Enter')
time.sleep(5)
elif "滑动验证页面" in title:
pyautogui.press('F5')
pyautogui.PAUSE = 1 # 调用在执行动作后暂停的秒数,只能在执行一些pyautogui动作后才能使用,建议用time.sleep
pyautogui.FAILSAFE = False
pyautogui.moveTo(880, 430, duration=0.5) # 定位元素 可以将x,y写入,duration 是移动时间
pyautogui.dragTo(random.randint(1190, 1220), random.randint(420, 440), duration=0.5, button='left')
elif "滑动验证页面" not in title:
time.sleep(10)
html = await tab.get_html(timeout=5) #给出html
break
elif '无法访问' in title or '无法连接':
break
n += 1
if n == 10:
break
return html
async def get_detail_anj():
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/8"
"5.0.4183.102 Safari/537.36",
}
n = 1
# ip 或者其他出问题可以重新访问这一页
while True:
try:
url = 'baidu.com'
proxyurl = f"{
'127.0.0.1':8000}" #代理
#headless为是否显示浏览器
async with AsyncChromeDaemon(headless=False, user_agent=headers, proxy=proxyurl) as cd:
async with cd.connect_tab(index=0) as tab:
for page in range(n, 1000):
url = url+page #页数
await tab.goto(requrl, timeout=5) #浏览器访问网页
html = await hdyz(tab) #调用滑动取出html
r = etree.HTML(html)
pg_list = r.xpath("//span[@class='wel']/text()")
cookies = await tab.get_cookies() #还可以取出全部cookies
if page == int(pg_list[-1]): #设置个xpath页数位了跳出
break
except:
# print('访问错误重新访问', url)
n = page
if __name__ == "__main__":
asyncio.run(get_detail_anj())
代码需要简答修改,无法直接使用。