1.1 安装pip
在最新的Python安装包中已经继承了pip,我们可以在Python的安装目录下查看是否有pip.exe或pip3.exe文件。如果有,则可以直接在windows命令提示符下输入pip或pip3命令。
我自己安装的Python版本是3.5.3,安装目录是D:\ToolSetupPath\python\Scripts,其中就有pip.exe和pip3.exe文件,如下:

在windows命令提示符下输入pip可以查看pip命令的说明信息,如下:
注意: 如果出现以上信息,就说明pip已经安装成功。如果提示pip不是内部或外部命令,则可以手动将D:\ToolSetupPath\python\Scripts目录添加到系统的环境变量下的Path下面,重新打开cmd命令行进行验证。
1.2 安装selenium
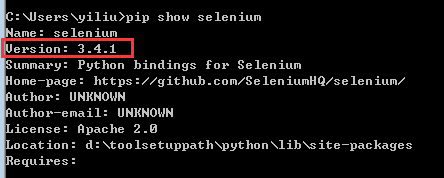
前面安装pip就是为了更方便的安装selenium包,打开cmd命令行窗口,输入以下命令: C:\Users\yiliu>pip install Selenium 即可。安装完成可以查看当前包的版本信息,输入命令:C:\Users\yiliu>pip show selenium
如果想卸载当前的安装包,则可以使用命令:C:\Users\yiliu>pip uninstall selenium
1.3 第一个自动化脚本
【代码】
# coding=utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
driver.find_element_by_id('kw').send_keys('Selenium2')
driver.find_element_by_id('su').click()
driver.quit()
代码解释:
第1行: #coding=utf-8
为了防止乱码,把编码统一成utf-8格式
等价于:#-*- coding:utf-8 -*-
第2行: from selenium import webdriver
这一句目的是导入selenium中的webdriver包,只有导入webdriver包,才能使用webdriver API进行自动化脚本开发。
第3行:driver = webdriver.Firefox()
这一句是把webdriver的Firefox对象赋值给变量driver。只有获得了浏览器对象后,才可以启动浏览器。打开网址,操作页面元素,Firefox浏览器驱动默认已经在webdriver包里了,所以可以直接调用。
第4行:driver.get(“http://www.baidu.com”)
这一句是获得浏览器对象后,通过get()方法,可以向浏览器发送网址(URL)
第5行:driver.find_element_by_id(“kw”).send_keys(“Selenium2”)
这一句是页面元素的定位。这里通过id=kw,定位到百度的输入框,并通过键盘输入方法send_keys()向百度输入框中输入 “Selenium2” 搜索关键字。
第6行: driver.find_element_by_id(“su”).click()
这一句通过id=su定位 【百度一下】的搜索按钮,并向搜索按钮发送单击事件click()。
第7行: driver.quit()
这一句是退出并关闭浏览器及相关的驱动程序。
1.4 遇到的问题及解决方法
问题1:
Traceback (most recent call last):
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\common\service.py", line 74, in start
stdout=self.log_file, stderr=self.log_file)
File "D:\ToolSetupPath\python\lib\subprocess.py", line 676, in __init__
restore_signals, start_new_session)
File "D:\ToolSetupPath\python\lib\subprocess.py", line 955, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "D:/pythonCode/baidu.py", line 4, in <module>
driver = webdriver.Firefox()
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\firefox\webdriver.py", line 142, in __init__
self.service.start()
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\common\service.py", line 81, in start
os.path.basename(self.path), self.start_error_message)
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
解决方法:
针对上述问题,
(1)selenium 3.x开始,webdriver/firefox/webdriver.py 的__init__中,executable_path="geckodriver";而2.x是executable_path="wires"
(2)firefox 47以上版本,需要下载第三方driver,即geckodriver,下载地址:https://github.com/mozilla/geckodriver/releases ,如下:
(3)将上述下载的文件解压后得到的geckodriver.exe文件放到python.exe目录下(原因是python已经加到环境变量的path下了)
问题2:
将geckodriver.exe文件放到python.exe目录下后再次执行代码程序,火狐浏览器能够打开,并且能够定位到百度页面,但是搜索功能无法执行,一直停留在如下页面
同时报以下错误:
D:\ToolSetupPath\python\python.exe D:/pythonCode/baidu.py
Traceback (most recent call last):
File "D:/pythonCode/baidu.py", line 7, in <module>
driver.find_element_by_id('kw').send_keys('Selenium2')
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\remote\webelement.py", line 349, in send_keys
'value': keys_to_typing(value)})
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\remote\webelement.py", line 493, in _execute
return self._parent.execute(command, params)
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 252, in execute
self.error_handler.check_response(response)
File "D:\ToolSetupPath\python\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 194, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.WebDriverException: Message: Expected [object Undefined] undefined to be a string
解决方法:
针对上述问题,网上查搜索原因,说是因为火狐浏览器升级到了最新版本导致的,将火狐浏览器回退到53版本以下就可以了,楼主试了以后,的确可行。
以上是采用的火狐浏览器,下面换成chrome来试试,由于Chrome浏览器驱动没有包含在webdriver包里,所以在此之前要下一个chrome的驱动,即chromedriver,下载地址:http://chromedriver.storage.googleapis.com/index.html ,我选择下载的是2.29版本(对应的谷歌浏览器版本是56开头的),下载页面如下:
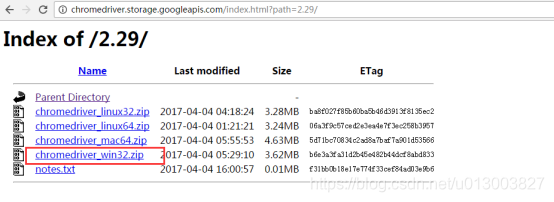
同样的道理,将下载的chromedriver.exe也放在python.exe同目录下,如下:
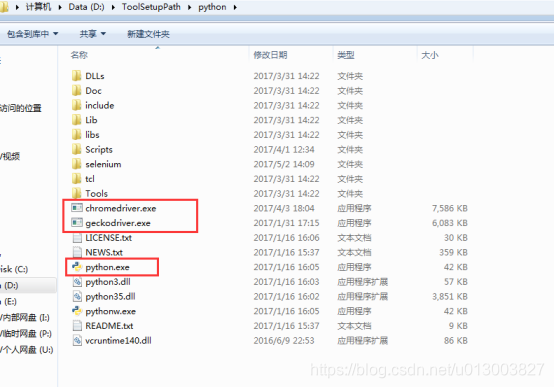
代码中将driver = webdriver.Firefox()修改为driver = webdriver.Chrome()即可。
运行代码程序,能够正确启动谷歌浏览器,并且能够进入到百度页面,进而能够搜索关键字 “Selenium2”,得到的结果如下:
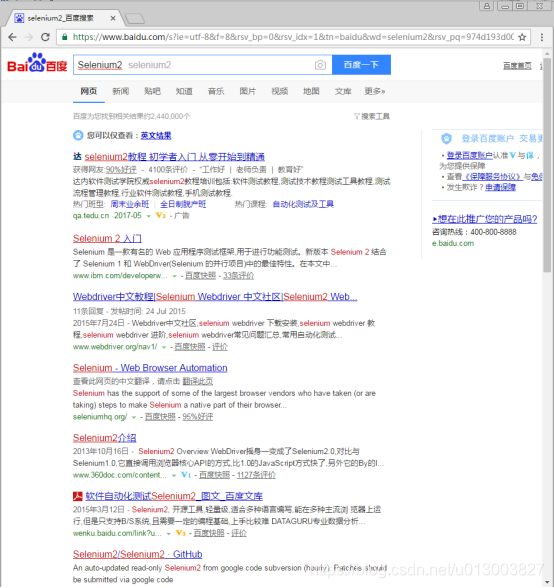
由于刚刚浏览器的操作过程太快了,没有看清实际操作过程,此时需要加time,让浏览器的操作慢下来,代码如下:
# coding=utf-8
from selenium import webdriver
import time #导入time函数库
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
time.sleep(5) #调出百度页面后休眠0.5秒
driver.find_element_by_id('kw').send_keys('Selenium2')
time.sleep(5) #百度输入框中输入Selenium2后停留5秒
driver.find_element_by_id('su').click()
driver.quit()
至此,第一个自动化脚本程序已经完成。
1.5 打印页面title
【代码】
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
print(driver.title) #打印页面title
driver.quit()
打印结果:
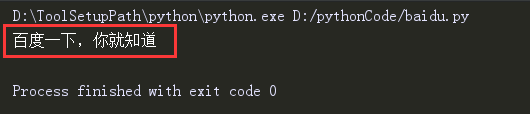
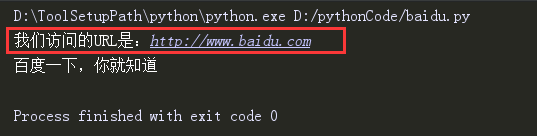
1.6 打印URL
# coding=utf-8
from selenium import webdriver
driver = webdriver.Chrome()
url="http://www.baidu.com"
print("我们访问的URL是:%s" %(url)) #打印URL
#通过get方法获取当前URL
driver.get(url)
print(driver.title) #打印页面title
driver.quit()
打印结果: