最近在看刘鹏飞写的关于prompt的综述,论文太长了。。 只能看一部分记录一部分笔记,离散的prompt理解起来较容易,所以重点记录一下关于continuous prompt的笔记,P-tuning v2也提到了之前一些论文的工作,所以今天记录下这篇论文相关的笔记,提到之前论文中的部分也大概写写。
论文地址
https://arxiv.org/pdf/2110.07602.pdfarxiv.org/pdf/2110.07602.pdf
1. Abstract
Prompt tuning是之前其他论文提出的一种方法,通过冻结语言模型仅去调整连续的prompts,在参数量超过10B的模型上,效果追上了fine-tune,但是在normal-sized模型上表现不好,并且无法解决序列标注任务。针对这两个问题,作者提出了P-tuning v2。
2. Related work
这篇论文跟之前的prompt tuning, prefix tuning 和p-tuning v1 有一定的联系,所以在这大概介绍一下便于对这边论文的理解。这几种方法都是基于优化continuous prompt,之前的工作都是手动设计模板或者自动生成模板,统称discrete prompt。discrete prompt有一定的局限性,找出的结果可能不是最优,而且对token的变动十分敏感,所以之后的研究方向也都是连续空间内的prompt。
2.1 Prefix tuning
这个是做NLG任务的,具体做法是为不同的任务,添加不同的prefix。训练时freeze预训练语言模型,只微调task-specific的prompt,并且prompt不止加在一开始的嵌入层上,每一层都加入可微调的参数,并在最后加了一个MLP。
2.2 P-tuning v1
出发点是让GPT这种生成模型,也具备NLU的能力。主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode再与input embedding进行拼接,并且pseudo token的位置不一定是前缀,也可以是中间位置。
2.3 Prompt tuning
在原有序列的输入词向量的基础上增加可训练的连续embedings,并通过特殊的初始化方法,在模型参数达到10B时,效果达到了与fine-tune持平,仅需微调0.01%的参数量。P-tuning v2也是延续这个文章的思路,解决了一些他存在的问题。
(其实P-tuning做法和Prefix tuning更类似,是优化后的prefix-tuning)
3. Structure

左图是之前的p-tuning,右图是p-tuning v2
可以看到p-tuning v2中,同prefix-tuning一样,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。而在左图之前的模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制,还有input embedding会直接影响模型的预测。这样改动可以让模型有更多task-specific的参数(从0.01%增加到0.1%-3%),把prompt加到每一层,也会对模型预测结果产生更直接的影响。
(这里加入的prompt是在预训练模型之外的,相当于每一层的输出传递到下一层时,前面加上了length*embedding dimension的几个向量,模型计算attention会利用这些prompt,但是prompt本身不会计算后面的句子去输出结果,只是每一层都加在前面,所以总的可训练的参数量是number of layers * prompt length * embedding dimensions。如果我理解错了请及时指正。。)
4. Optimization and Implementation
4.1 Reparameterization
在右图上方的一个结构,是prompt的一个encoder,可以用一个MLP当做可训练的参数,这个结构是可选择的,因为对于不同的task和datasets,作者发现它可能会提升效果,但也可能提升较小甚至是负提升,所以还需根据不同情况去决定是否使用。
4.2 Prompt Length
作者通过实验也发现根据不同的任务,对length的需求也不一样,比如一些简单的task倾向比较短的prompt(less than 20), 而一些比较难的序列标注任务,长度需求比较大(around 100)。
4.3 Multi-task Learning
在fine-tune for individual tasks之前,用共享的prompts去进行多任务预训练,可以让prompt有比较好的初始化。
4.4 Classification Head
这里提到了prompt tuning中的verbalizer这个结构,将label用一个语言表达器,去映射到label的拓展词上。作者认为这个结构有时候局限性很大,在全监督的数据集上和一些序列标注任务上(可能这就是prompt tuning在序列标注任务上效果不好的原因),所以作者还是用CLS去做标签分类。(结果如下图)

Comparison between [CLS] label with linearhead and verbalizer with LM head on RoBERTa-large.
5. Experiments
论文里在多种NLU任务上评估了模型,通过冻结预训练语言模型,只在continuous prompt上进行微调,并且实验都是用全监督的方法而不是few-shot。

Results on SuperGLUE development set

Results on Named Entity Recognition (NER), Question Answering (Extractive QA), and Semantic RoleLabeling (SRL)
可以看到在NLU很多任务上,效果和fine-tune效果差不多,而且有的超过了fine-tune的结果。在序列标注上,p-tuning v2效果没NLU任务那么明显,但是经过multi-task training,效果有很大提升,很多超过了fine-tune。
6. Conclusion
之前的prompt方法都是想在few-shot上取得进展的,在全监督的数据上,还是不如fine-tune的结果,除非模型足够大(超过10B),这篇论文使prompt这个方法在not large-scale上,也取得了优于fine-tune的结果,并且训练的参数远少于直接tune整个预训练模型。(个人感觉这种思路和一开始提出的prompt learning有点远了,可能已经算另一种领域了,说不定之后会有一个新的名词来定义。。)
7. References
- 择数AI:灵魂拷问: Prompt tuning 已经全面超过fine-tuning了吗?
- 金琴:一文了解Prompt的基本知识与经典工作
- 刘鹏飞:近代自然语言处理技术发展的“第四范式”
- 吃肉不长肉:Prompt专栏第2期-与Fine-tuning的效果对比
三、P-Tuning v2
3.1 缺少普遍性
在许多NLP应用中,提示优化和P-tuning已经被证明是相当有效的(参见第5节)。然而,考虑到缺乏普遍性,P-tuning还不是微调的全面替代方法。
缺少跨尺度的普遍性。Lester等人(2021)表明,当模型规模超过100亿个参数时,提示优化可以与微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和微调的表现有很大差异,这大大限制了提示优化的适用性。
缺少跨任务的通用性。尽管Lester等人(2021年)和P-tuning在GLUE和SuperGLUE等NLU基准上显示出优越性,但它们在另一大类硬序列NLU任务(即序列标注)上的有效性却没有得到验证。首先,序列标注需要预测一连串的标签,而不是单一的标签。其次,序列标注通常预测的是无实际意义的标签,这对于将其转化为有效的verbalizers来说可能是个挑战(Schick和Schütze,2020)。在我们的实验中(参见第4.3节和表3),我们表明Lester等人(2021)&P-tuning在典型的序列标注任务中的表现比微调差。
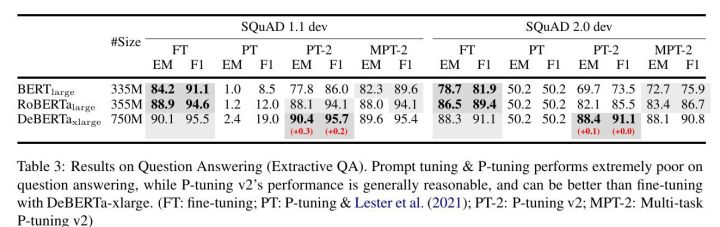
表3: 问答的结果(提取式QA)。Prompt tuning & P-tuning在问答上的表现极差,而P-tuning v2的表现基本合理,可以比DeBERTa-xlarge的微调更好。(FT:微调;PT:P-tuning & Lester等人(2021);PT-2:P-tuning v2;MPT-2:多任务P-tuning v2)
考虑到这些挑战,我们提出了Ptuning v2,它将前缀微调作为一个跨规模和NLU任务的通用解决方案。
3.2 深度提示优化 deep promts optimization
前缀微调(Li and Liang, 2021)最初是为自然语言生成(NLG)任务提出的,但我们发现它对NLU也非常有效。我们描述了一个适合NLU的前缀微调版本。
在(Lester等人,2021)和P-tuning中,连续提示只被插入transformer第一层的输入嵌入序列中(参照图2(a))。在接下来的transformer层中,插入连续提示的位置的嵌入是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
1. 可调控的参数量有限。大多数语言模型目前只能支持512的最大序列长度(由于注意力的二次计算复杂性的成本)。如果我们另外扣除我们的上下文的长度(例如,要分类的句子),那么我们用连续的提示语来填充的长度是有限的。
2. 用很深的transformer进行微调时,稳定性有限。随着transformer的不断深入,由于许多中间层的计算(具有非线性激活函数),来自第一个transformer层的提示的影响可能是意想不到的,这使得我们的优化不是一个非常平稳的。
鉴于这些挑战,P-tuning v2利用多层提示(即深度提示优化),如同前缀优化(Li and Liang, 2021)(参考图2(b)),作为对P-tuning和Lester等人(2021)的重大改进。不同层中的提示作为前缀token加入到输入序列中,并独立于其他层间(而不是由之前的transformer层计算)。一方面,通过这种方式,P-tuning v2有更多的可优化的特定任务参数(从0.01%到0.1%-3%),以允许更多的每个任务容量,而它仍然比完整的预训练语言模型小得多;另一方面,添加到更深层的提示(例如图2中的LayerN Prompts)可以对输出预测产生更直接和重大的影响,而中间的transformer层则更少(参见第4.4节)。
3.3 优化和实施
还有一些有用的优化和实施细节。
优化。重新参数化。以前的方法利用重新参数化功能来提高训练速度、鲁棒性和性能(例如,MLP的前缀微调和LSTM的P-tuning)。然而,对于NLU任务,我们发现这种技术的好处取决于任务和数据集。对于一些数据集(如RTE和CoNLL04),MLP的重新参数化带来了比嵌入更稳定的改善;对于其他的数据集,重新参数化可能没有显示出任何效果(如BoolQ),有时甚至更糟(如CoNLL12)。见第4.4节中我们的消融研究。
优化。提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在我们的实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与prefix-tuning(Li和Liang,2021)中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。见第4.4节中的讨论。
优化。多任务学习。多任务学习对我们的方法来说是可选的,但可能是相当有帮助的。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解(Gu等人,2021);另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。我们的实验表明,在一些困难的序列任务中,多任务学习可以作为P-tuning v2的有益补充,表示为MPT-2(参考表2,3,4)。
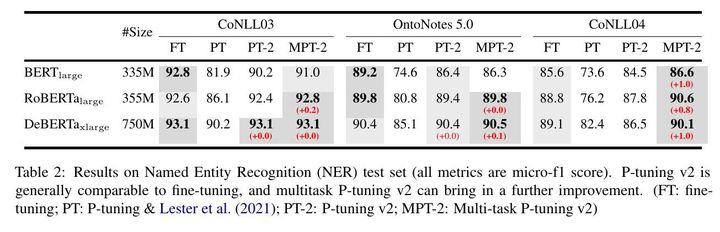
表2: 命名实体识别(NER)测试集的结果(所有指标都是micro-f1得分)。P-tuning v2总体上与微调相当,而多任务P-tuning v2可以带来进一步的改进。(FT:微调;PT:P-tuning & Lester等人(2021);PT-2:P-tuning v2;MPT-2:多任务P-tuning v2)
实施。[CLS]和标注分类,而不是verbalizer。Verbalizer(Schick和Schütze,2020)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,verbalizers并不是必须的。它阻碍了提示优化在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-tuning v2回到了传统的[CLS]标签分类(参照图2)范式,采用随机初始化的线性头。见第4.4节中的比较。
四、实验
4.1 设置
我们对不同的常用预训练模型和NLU任务进行了广泛的实验,以验证P-tuning v2的有效性。
评估设置。在这项工作中, “prompt tuning”, “P-tuning”, “P-tuning v2”, 和 "多任务 P-tuning v2"的所有结果都是通过冻结transformer的参数,只优化连续提示而得到的。特定任务参数的比率(如0.1%)是通过比较连续提示的参数和transformer的参数得出的。只有 "微调 "的结果是通过调整transformer的参数得到的(不使用连续提示)。
另一个需要注意的是,我们的实验都是在全数据监督学习的环境下进行的,而不是在few-shot学习的环境下进行的,这一点很重要,因为我们利用的一些特性(例如,使用具有线性头的类标签而不是具有LM头的言语者)只可能在监督的环境下发挥作用。
NLU任务。首先,我们包括GLUE(Wang等人,2018)和SuperGLUE(Wang等人,2019)基准的部分数据集来测试P-tuning v2的通用NLU能力,包括SST-2、MNLI-m、RTE、BoolQ和CB。更重要的是,我们以序列标注的形式引入了一套任务,要求语言模型预测输入序列中每个标注的类别,包括命名实体识别(CoNLL03(Sang和De Meulder,2003),OntoNotes 5.0(Weischedel等人。2013)和CoNLL04(Carreras和Màrquez,2004)),抽取式问答(SQuAD 1.1和SQuAD 2.0(Rajpurkar等人,2016))和语义角色标签(CoNLL05(Carreras和Màrquez,2005)和CoNLL12(Pradhan等人,2012))。
预训练的模型。我们包括BERT-large(Devlin等人,2018)、RoBERTa-large(Liu等人,2019)、DeBERTa-xlarge(He等人,2020)、GLMxlarge/xxlarge(Du等人,2021)进行评估。它们都是为NLU目的设计的双向模型,涵盖了从约300M到10B的广泛规模。
比较方法。我们将我们的P-tuning v2(PT-2)与vanilla fine-tuning(FT)、P-tuning & Lester等人(2021)(PT)进行比较。此外,对于有关序列标注的困难任务,我们提出了多任务P-tuning v2(MPT-2)的结果,更多细节见第4.3节。
4.2 P-tuning v2: 不同规模
表1展示了P-tuning v2在不同模型规模下的表现。对于简单的NLU任务,如SST-2(单句分类),Lester等人(2021)和P-tuning在较小的规模下没有显示出明显的劣势。但是当涉及到复杂的挑战时,如自然语言推理(RTE)和多选题回答(BoolQ),它们的性能会非常差。相反,P-tuning v2在较小规模的所有任务中都与微调的性能相匹配。令我们惊讶的是,P-tuning v2在RTE中的表现明显优于微调,特别是在BERT中。

表1: 部分GLUE和SuperGLUE开发集的结果(所有指标都是准确度)。在小于10B的模型上,P-tuning v2明显超过了P-tuning & Lester等人(2021),并与微调的性能相符。(FT:微调;PT:P-tuning & Lester等人(2021);PT-2:P-tuning v2)
就较大规模(2B到10B)的GLM(Du等人,2021)而言,P-tuning&Lester等人(2021)和微调之间的差距逐渐缩小了。在10B规模上,我们有一个类似于(Lester等人,2021)报告的观察结果,即提示优化变得与微调竞争。然而,P-tuning v2在所有尺度上都与微调相当,但与微调相比,只需要0.1%的特定任务参数。
此外,我们观察到,在一些数据集中,RoBERTa-large的性能比BERT-large差。部分原因是,我们根据经验发现提示优化对超参数相当敏感,有时优化就会被困住。P-tuning v2在优化过程中可以更加稳定和稳健。关于超参数的更多细节,请参考我们的代码库。
4.3 P-tuning v2: 跨越任务
在第4.2节中,我们讨论了P-tuning v2的一贯性,无论何种规模都可以与微调相媲美。然而,GLUE和SuperGLUE的大多数任务都是相对简单的NLU问题。另一个重要的硬NLU挑战系列在于序列标注,它与一些更高级的NLP应用有关,包括开放信息提取、阅读理解等等。
为了评估P-tuning v2在这些困难的NLU挑战中的能力,我们选择了三个典型的序列标注任务。名称实体识别、抽取式问答(QA)和语义角色标签(SRL),共八个数据集。

表4: 关于语义角色标签(SRL)的结果。P-tuning v2比Lester等人(2021)和P-tuning在SRL上显示出一致的改进。(FT:微调;PT:P-调和Lester等人(2021);PT-2:P-调 v2;MPT-2:多任务P-调 v2)
名称实体识别(NER)。NER的目的是预测所有代表一些给定的实体类别的词的跨度与句子。我们采用了CoNLL03(Sang和De Meulder,2003)、OntoNotes 5.0(Weischedel等人,2013)和CoNLL04(Carreras和Màrquez,2004)。对于CoNLL03和CoNLL04,我们在标准的训练-开发-测试分割上训练我们的模型。对于OntoNotes 5.0,我们使用了与(Xu et al., 2021b)相同的训练、开发、测试划分。所有的数据集都是以IOB2格式标注的。我们使用序列标注来解决NER的任务,通过分配标签来标注实体的开始和内部的一些类别。语言模型为每个token生成一个表示,我们使用一个线性分类器来预测标签。我们使用官方脚本来评估结果。对于多任务设置,我们结合三个数据集的训练集进行预训练。我们对每个数据集使用不同的线性分类器,同时共享连续的提示信息。
(提取式)问答(QA)。提取式QA是为了从给定的上下文和问题中提取答案。我们使用SQuAD(Rajpurkar等人,2016)1.1和2.0,其中每个答案都在上下文的连续跨度内。遵循传统,我们将问题表述为序列标注,为其指定两个标签之一。开始 "或 "结束 "这两个标签中的一个给每个标注,最后选择最有把握的开始和结束对的跨度作为提取的答案。如果最有把握的一对的概率低于阈值,该模型将假定该问题是不可回答的。对于多任务设置,我们用于预训练的训练集结合了SQuAD 1.1和2.0的训练集。在预训练时,我们假设所有的问题,无论其来源如何,都可能是无法回答的。
语义角色标签(SRL)。SRL为句子中的单词或短语分配标签,表明它们在句子中的语义作用。我们在CoNLL05(Carreras和Màrquez,2005)和CoNLL12(Pradhan等人,2012)上评估P-tuning v2。由于一个句子可以有多个动词,我们在每个句子的末尾添加目标动词token,以帮助识别哪个动词用于预测。我们根据相应的语义角色表示,使用线性分类器对每个词进行分类。对于多任务设置,预训练训练集是CoNLL05(Carreras和Màrquez,2005)、CoNLL12(Pradhan等人,2012)和propbank-release(用于训练SRL的常见扩展数据)的训练集的组合。多任务训练策略与NER类似。
结果。从表2、3、4中,我们观察到Ptuning v2在所有任务上都能与fineetuning相媲美。P-tuning和Lester等人(2021)的表现要差得多,特别是在QA上,这可能是三个任务中最难的挑战。我们还注意到,SQuAD 2.0中出现了一些不正常的结果(BERT/RoBERTa/DeBERTa使用Lester等人(2021)和P-tuning显示了相同的性能)。这可能是因为与SQuAD 1.1相比,SQuAD 2.0包含无法回答的问题,而Lester等人(2021)和P-tuning可能会得到平凡解。
多任务P-tuning v2通常会带来整体任务的明显改善,但QA除外(这可能还是混合了所有可回答的SQuAD 1.1和不可回答的SQuAD 2.0的结果),这意味着随机初始化提示的潜力没有得到充分开发。
4.4 消融研究
我们研究了一些重要的超参数和架构设计,它们可能在P-tuning v2中发挥核心作用。
提示深度。Lester等人(2021)&P-tuning和P-tuning v2的主要区别在于我们引入的多层连续提示。直观地说,由于中间transformer层的许多非线性激活函数,一个提示所处的transformer层越深,它对输出预测的影响就越直接。为了验证其确切的影响,给定一定数量的k来添加提示,我们按照升序和降序选择k层来添加提示作为前缀token;对于其余的层,我们改变它们的注意力mask,不允许其前缀提示参与计算。
如图4所示,在参数量相同的情况下(即添加提示语的transformer层数),按降序添加总是比按升序添加好。在RTE的情况下,只在第17-24层添加提示语可以产生与所有层非常接近的性能,进一步削减了我们可能需要调整的匹配微调的参数。

图4:使用BERTlarge对提示深度进行消融研究。"[x-y]"指的是我们添加连续提示的层间隔(例如,"21-24 "意味着我们将提示添加到21至24的transformer层)。同样数量的连续提示添加到较深的transformer层(即更接近输出层)可以产生比添加到开始层更好的性能。
嵌入与MLP再参数化。在前缀微调(Li and Liang, 2021)和Ptuning(Liu et al., 2021b)中,作者发现重新参数化对于提高训练速度、鲁棒性和性能都很有用。然而,我们进行的实验表明,重新参数化的效果在不同的NLU任务和数据集中是不一致的。
如图3所示,在RTE和CoNLL04中,MLP的重新参数化通常表明在几乎所有的提示长度上都比嵌入的性能好。然而,在BoolQ中,MLP和嵌入的结果具有竞争性;在CoNLL12中,嵌入的结果一直优于MLP。

图3: 使用RoBERTa-large对提示长度和reparamerization进行消融研究。给定某些NLU任务和数据集,结论可能非常不同。(MQA: 多选题QA)
提示长度。提示长度是P-tuning v2的另一个有影响力的超参数,其最佳值因任务而异。从图3中我们观察到,对于简单的NLU任务,通常情况下,较短的提示语就能获得最佳性能;对于困难的序列任务,通常情况下,比100长的提示语会有帮助。
我们还发现,重新参数化与最佳提示长度有着密切的联系。例如,在RTE、CoNLL04和BoolQ中,MLP的重参数化比嵌入更早达到其最佳结果。这一结论可能有助于对P-tuning的优化特性进行一些思考。
带LM头的Verbalizer与带线性头的[CLS]标签。带LM头的Verbalizer一直是以前的提示性微调方法的核心组成部分。然而,在有监督的情况下,对于P-tuning v2来说,用大约几千个参数来调整一个线性头是可以承受的。我们在表5中展示了我们的比较,其中我们保留了其他的超参数,只将[CLS]标签的线性头改为verbalizer的LM头。在这里,为了简单起见,我们对SST-2、RTE和BoolQ使用 "真 "和 "假";对CB使用 "真"、"假 "和 "中性"。结果表明,verbalizer和[CLS]的表现没有明显区别。

表5: 在RoBERTa-large上,带线性头的[CLS]标签和带LM头的口头语者之间的比较。
五、相关工作
预训练语言模型。自监督(Liu等人,2020)预训练语言模型(Han等人,2021a)已经成为自然语言处理的主干。从早期的GPT(Radford等人,2019)、BERT(Devlin等人,2018)、XLNet(Yang等人,2019)、RoBERTa(Liu等人,2019)的参数量有限(小于350M),T5(Raffel等人,2019)和GPT-3(Brown等人,2020)的出现推动了拥有10亿甚至万亿参数的巨型语言模型的发展。
提示。提示(Liu等人,2021a)指的是利用输入语境中的特殊模板来帮助语言模型预测的理解和生成。最近,由于GPT-3(Brown等人,2020)的成功,出现了各种提示策略,包括离散自然语言提示(Shin等人,2020;Gao等人,2020),连续提示(Liu等人,2021b;Li和Liang,2021;Lester等人,2021;Qin和Eisner,2021;Zhong等人,2021),调整偏差(Logan IV等人,2021)以及其他许多提示策略。
提示法在广泛的NLP应用中的优势和有效性在最近的文献中得到了验证,包括文本分类(Hu等人,2021;Min等人,2021;Sun等人,2021;Li等人,2021;Zhang等人,2021b)、实体打字(Ding等人,2021)、few-shot人学习(Zheng等人,2021;Xu等人。2021a; Zhao et al., 2021; Gu et al., 2021; Zhang et al., 2021a),关系抽取(Chen et al., 2021a; Han et al., 2021b; Sainz et al., 2021),知识探测(Zhong et al, 2021),命名实体识别(Chen等人,2021b),机器翻译(Tan等人,2021;Wang等人,2021b)和对话系统(Wang等人,2021a)。
在这项工作中,我们特别关注将提示方法扩展到更小的模型和困难序列NLU任务。
六、总结
我们提出了P-tuning v2,一种在不同规模和任务中都可与微调相媲美的提示方法。P-tuning v2不是一种概念上的新方法,而是一种优化和适应前缀优化和深度提示优化的NLU挑战。Ptuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的幅度超过了Lester等人(2021)和P-tuning。Ptuning v2可以成为微调的综合替代方案和未来工作的强大基线。