文章目录
一、背景
将预训练好的语言模型(LM)在下游任务上进行微调已成为处理 NLP 任务的一种范式,随着ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型,本文会讲解一些主流的微调技术。
当前主流大语言模型都是基于 Transformers 架构,下面我们来简单介绍一下 Transformers 和BERT。
1.1 Tansformer
在Transformer之前,主流的序列转换模型都是基于复杂的循环或卷积神经网络实现的,而这两者都有一些缺点:
- RNNs:固有的时序模型难以并行化处理,计算性能差。另外还存在长距离衰减问题
- CNNs:CNN对长序列难以建模(因为卷积计算时,卷积核/感受野比较小,如果序列很长,需要使用多层卷积才可以将两个比较远的位置关联起来)。但是使用Transformer的注意力机制的话,每次(一层)就能看到序列中所有的位置,就不存在这个问题。
Transformer是第一个完全基于注意力的序列转换模型,用多头自注意力(multi-headed self-attention)代替了 encoder-decoder 架构中最常用的循环层。但是卷积的好处是,输出可以有多个通道,每个通道可以认为是识别不同的模式,作者也想得到这种多通道输出的效果,所以提出了Multi-Head Attention多头注意力机制(模拟卷积多通道输出效果)。
1.1.1 模型结构
Transformer 整体架构如下:

编码器:编码器由N=6个相同encoder层堆栈组成。每层有两个子层。
-
multi-head self-attention -
FFNN层(前馈神经网络层,Feed Forward Neural Network),其实就是MLP,为了fancy一点,就把名字起的很长。
- 两个子层都使用残差连接(residual connection),然后进行层归一化(layer normalization)。
- 每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是当前子层的输出。
- 为了简单起见,模型中的所有子层以及嵌入层的向量维度都是 d model = 512 d_{\text{model}}=512 dmodel=512(如果输入输出维度不一样,残差连接就需要做投影,将其映射到统一维度)。(这和之前的CNN或MLP做法是不一样的,之前都会进行一些下采样)
这种各层统一维度使得模型比较简单,只有N和 d model d_{\text{model}} dmodel两个参数需要调。这个也影响到后面一系列网络,比如bert和GPT等等。
解码器:解码器同样由 N=6个相同的decoder层堆栈组成,每个层有三个子层。
-
Masked multi-head self-attention
在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,使用attention mask,屏蔽当前位置之后的那些位置。所以叫Masked multi-head self Attention。(对应masked位置使用一个很大的负数-inf,使得softmax之后其对应值为0)扫描二维码关注公众号,回复: 15441146 查看本文章
-
Encoder-Decoder Attention
编码器输出最终向量,将会输入到每个解码器的Encoder-Decoder Attention层,用来帮解码器把注意力集中中输入序列的合适位置。 -
FFNN
FFNN层包括两个线性变换,并在两个线性变换中间有一个ReLU激活函数,与编码器类似,每个子层都使用残差连接,然后进行层归一化。用公式表示就是:
F F N ( x , W 1 , W 2 , b 1 , b 2 ) = W 2 ( r e l u ( x W 1 + b 1 ) ) + b 2 = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x, W_1, W_2, b_1, b_2) = W_{2}(relu(xW_{1}+b_{1}))+b_{2}=max(0, xW_1 + b_1)W_2 + b_2 FFN(x,W1,W2,b1,b2)=W2(relu(xW1+b1))+b2=max(0,xW1+b1)W2+b2
假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示:

1.1.2 注意力机制
- 缩放的点积注意力(Scaled Dot-Product Attention)
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵 Q Q Q。key和value也一起组成矩阵 K K K和 V V V。 我们计算的输出矩阵为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
2. 多头自注意力,计算公式可表示为:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O where h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) \mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O \\ \text{where}~\mathrm{head_i} = \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i) MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
其中映射由权重矩阵完成: W i Q ∈ R d model × d k W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiQ∈Rdmodel×dk, W i K ∈ R d model × d k W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiK∈Rdmodel×dk, W i V ∈ R d model × d v W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v} WiV∈Rdmodel×dv and W O ∈ R h d v × d model W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}} WO∈Rhdv×dmodel。
我们采用 h = 8 h=8 h=8个平行attention层或者叫head。对于这些head中的每一个,我们使用 d k = d v = d model / h = 64 d_k=d_v=d_{\text{model}}/h=64 dk=dv=dmodel/h=64,总计算成本与具有全部维度的单个head attention相似。
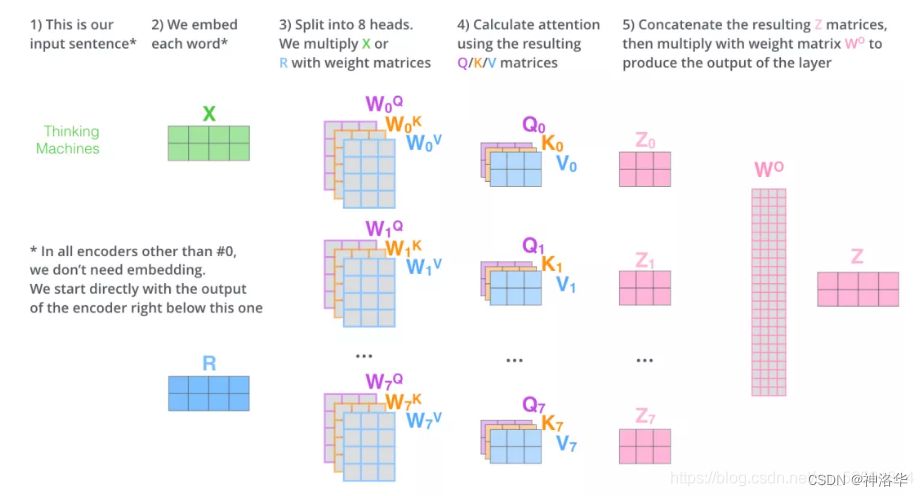
3. 输入 X 和8组权重矩阵 W Q W^Q WQ, W K W^K WK W V W^V WV相乘,得到 8 组 Q, K, V 矩阵。进行attention计算,得到 8 组 Z 矩阵(假设head=8)
4. 把8组矩阵拼接起来,乘以权重矩阵 W O W^O WO,将其映射回 d 维向量(相当于多维特征进行汇聚),得到最终的矩阵 Z。这个矩阵包含了所有 attention heads(注意力头) 的信息。
5. 矩阵Z会输入到 FFNN层。(前馈神经网络层接收的也是 1 个矩阵,而不是8个。其中每行的向量表示一个词)
1.1.3 注意力在Transformer中的应用
Transformer中用3种不同的方式使用multi-head attention:
-
multi-head self attention:标准的多头自注意力层,用在encoder的第一个多头自注意力层。所有key,value和query来自同一个地方,即encoder中前一层的输出。在这种情况下,encoder中的每个位置都可以关注到encoder上一层的所有位置。 -
masked-self-attention:用在decoder中,序列的每个位置只允许看到当前位置之前的所有位置,这是为了保持解码器的自回归特性,防止看到未来位置的信息 -
encoder-decoder attention:用于encoder block的第二个多头自注意力层。query来自前面的decoder层,而keys和values来自encoder的输出memory,这使得解码器在解码的每个时间步,都可以把注意力集中到输入序列中最感兴趣的位置。
1.2 BERT
在BERT出来之前,NLP领域还是对每个任务构造自己的神经网络,然后训练。BERT出来之后,就可以预训练好一个模型,来应用于很多不同的NLP任务了。简化训练的同时还提升了其性能。BERT和之后的工作使得NLP在过去几年有了质的飞跃。
BERT由两部分组成:预训练和微调。为了可以处理多种任务,BERT输入可以是一个句子,也可以是句子对,整个BERT结构如下:
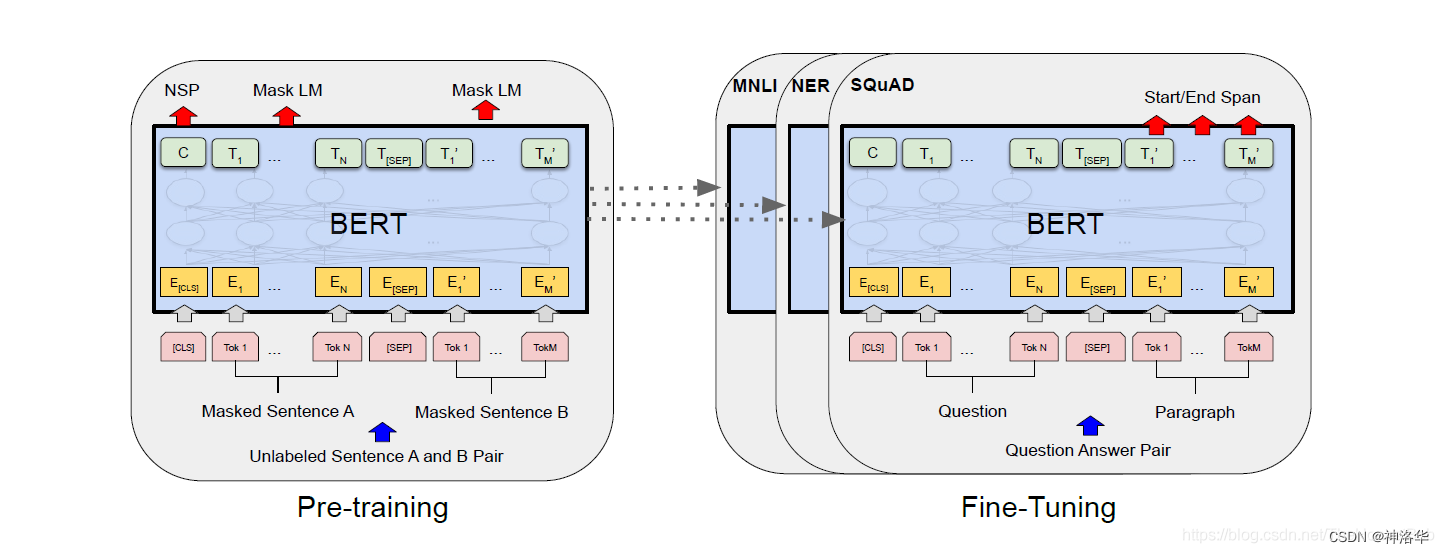
- [CLS]:即classification,放在句首,代表整个序列的信息。
- [SEP]:即separate,放在句尾,用于分割两个句子
- 用E表示输入embedding,用 C ∈ R H C\in \mathbb{R}^{H} C∈RH来表示特殊token[CLS]的最终隐向量,用 T i ∈ R H T_{i}\in \mathbb{R}^{H} Ti∈RH来表示第i个输入token的最终隐向量。
对于每个下游任务,我们只需将特定于任务的输入和输出连接到BERT中,然后端到端微调所有参数。在论文第四节详细介绍如何根据下游任务构造输入输出。
二、PEFT综述
- 论文《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》
- huggingface/peft:集成了LoRA、Prefix Tuning、P-Tuning、Prompt Tuning、AdaLoRA等PEFT方法
- 参考知乎《大模型参数高效微调技术原理综述》
参数高效微调(PEFT,Parameter-efficient fine-tuning)旨在通过仅训练一小部分参数来解决这个问题,这些参数可能是现有模型参数的子集或一组新添加的参数。这些方法在参数效率、内存效率、训练速度、模型的最终质量以及额外的推断成本(如果有)方面存在差异。本文提供了对2019年2月至2023年2月期间发表的40篇模型高效微调方法的系统概述、划分和比较。
2.1 PEFT的分类
PEFT方法可以通过多种方式进行分类,比如根据其基本方法或结构进行区分——是否向模型引入新的参数,还是仅微调不分现有的参数;根据微调目的进行分类——是否旨在最小化内存占用或仅追求存储效率。我们首先基于基本方法&结构进行分类,下图展示了这个分类体系的30种PEFT方法。
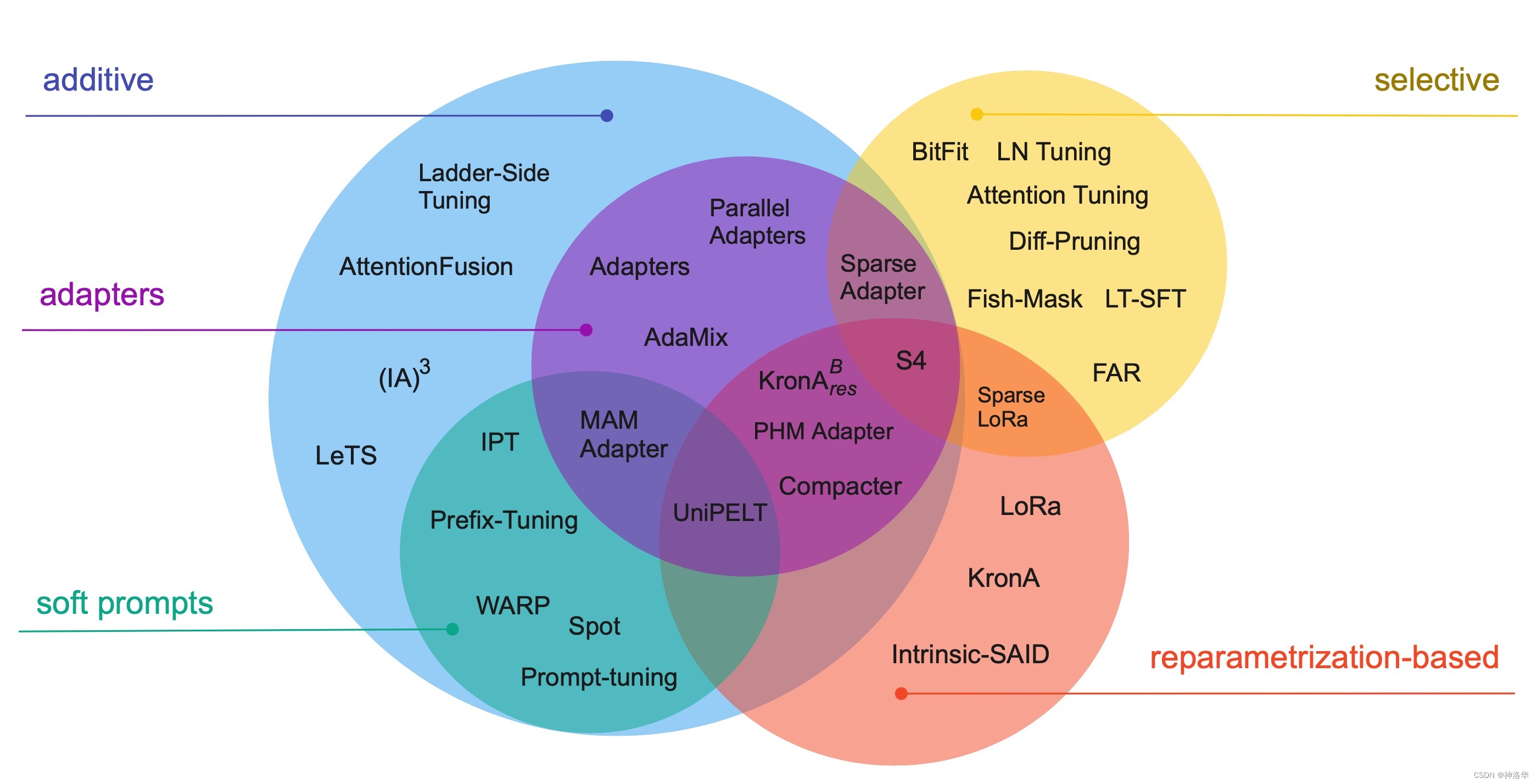
Additive methods:主要思想是通过添加额外的参数或层来扩充现有的预训练模型,并仅训练新添加的参数。到目前为止,这是参数高效微调方法中最大且广泛探索的类别。这种方法又分为:Adapters:即在Transformer子层后引入小型全连接网络,这种方法被广泛采用。Adapters有多种变体,例如修改适配器的位置、剪枝以及使用重参数化来减少可训练参数的数量。Soft Prompts:GPT-2旨在通过修改输入文本来控制语言模型的行为。然而,这些方法很难进行优化,且存在模型输入长度、训练示例的数量等限制,由此引入了soft 概念。Soft Prompts将模型的一部分输入嵌入通过梯度下降进行微调,将在离散空间中寻找提示的问题转化为连续优化问题。Soft Prompts可以仅对输入层进行训练(《GPT Understands, Too》、Prompt Tuning),也可以对所有层进行训练(Prefix-Tuning)。others:例如 L e T S LeTS LeTS、 L S T LST LST和 ( I A ) 3 (IA)^3 (IA)3等。
尽管这些方法引入了额外的参数到网络中,但它们通过减少梯度和优化器状态的大小,减少了训练时间,提升了内存效率。此外可以对冻结的模型参数进行量化(参考论文),
additive PEFT方法能够微调更大的网络或使用更大的批次大小,这提高了在GPU上的训练吞吐量。此外,在分布式设置中优化较少的参数大大减少了通信量。
Selective methods: 最早的selective PEFT方法是仅微调网络的几个顶层(冻结前层),现代方法通常基于层的类型(Cross-Attention is All You Need)或内部结构,例如仅微调模型的偏置(BitFit)或仅特定的行(Efficient Fine-Tuning of BERT Models on the Edge)。Reparametrization-based PEFT(重参数化):利用低秩表示来最小化可训练参数的数量。Aghajanyan等人(2020)证明了在低秩子空间中可以有效地进行微调,对于更大的模型或经过更长时间预训练的模型,需要进行调整的子空间更小。最知名的基于重参数化的方法LoRa,它将参数矩阵进行简单的低秩分解来更新权重 δ W = W d o w n W u p δW = W^{down} W^{up} δW=WdownWup。最近的研究(Karimi Mahabadi等,2021;Edalati等,2022)还探索了Kronecker product reparametrization( δ W = A ⊗ B δW = A ⊗ B δW=A⊗B)的使用,它在秩和参数数量之间取得了更有利的权衡。Hybrid methods:混合多种PEFT方法,例如,MAM Adapter结合了Adapters和Prompt
tuning;UniPELT加入了将LoRa;Compacter和KronAB对适配器进行了重参数化以减少其参数数量;最后,S4是一个自动化算法搜索的结果,它结合了所有的PEFT类别,额外参数数量增加0.5%的情况下最大化准确性。
2.2 不同PEFT方法的对比
参数效率(Parameter efficiency)涵盖了多个方面,包括存储、内存、计算和性能。然而,仅实现参数效率并不一定会导致减少RAM的使用。
为了比较PEFT方法,我们考虑了五个维度:存储效率、内存效率、计算效率、准确性和推理开销,彼此并不完全独立,但一个维度上的改进并不一定会带来其它维度的改进。
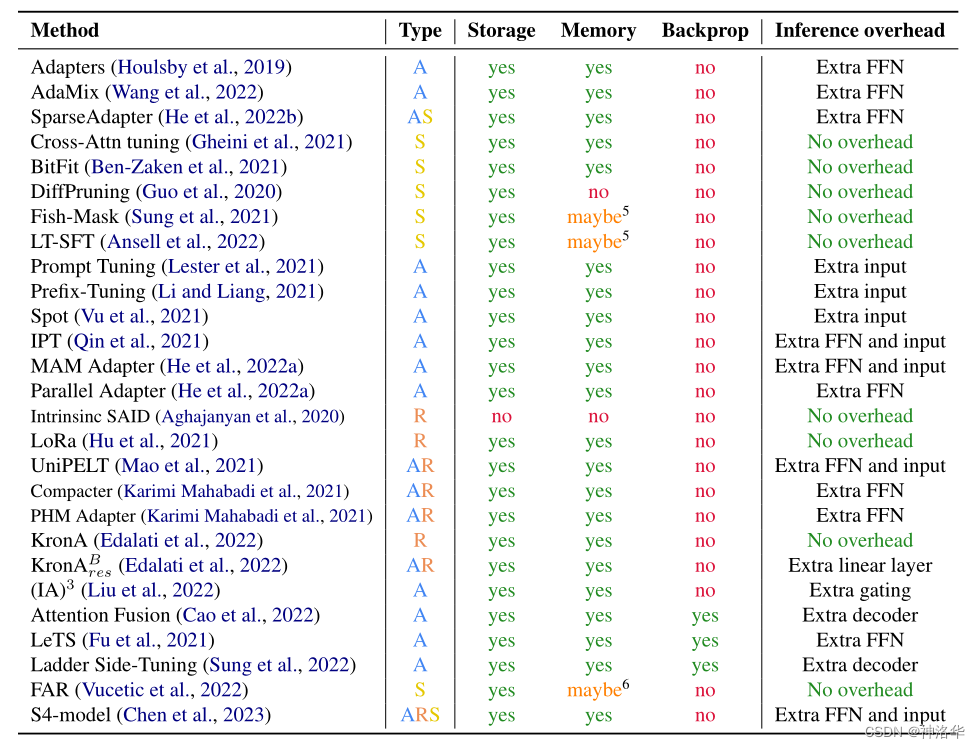
下表展示了各种参数高效方法的参与训练的参数量( trainable parameters)、最终模型与原始模型的改变参数量(changed parameters,特指通过梯度优化算法进行更新的参数数量),以及论文中参与评估的模型的范围(<1B、<20B、>20B)
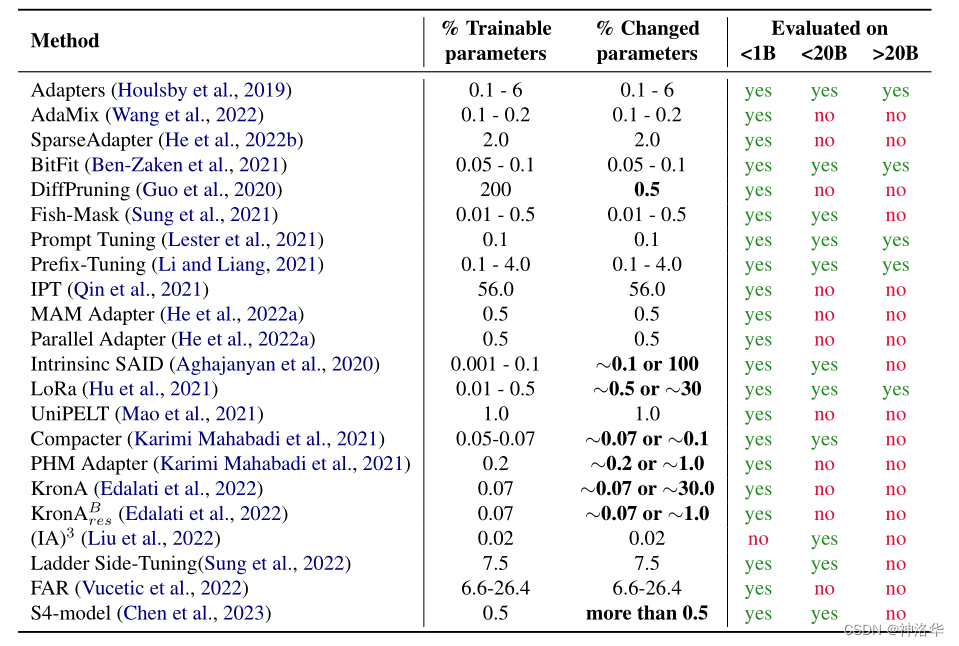
三、Additive methods
3.1 Adapter Tuning
3.1.1 Adapters(2019.2.2)
Adapters最初来源于CV领域的《Learning multiple visual domains with residual adapters》一文,其核心思想是在神经网络模块基础上添加一些残差模块,并只优化这些残差模块,由于残差模块的参数更少,因此微调成本更低。
Houlsby等人将这一思想应用到了自然语言处理领域。他们提出在Transformer的注意力层和前馈神经网络(FFN)层之后添加全连接网络。微调时,只对新增的 Adapter 结构和 Layer Norm 层进行微调,从而保证了训练的高效性。 每当出现新的下游任务,通过添加Adapter模块来产生一个易于扩展的下游模型,从而避免全量微调与灾难性遗忘的问题。
Adapters Tuning效率很高,通过微调不到4%的模型参数,可以实现与 fine-tuning相当的性能。

- 左侧:我们在每个Transformer layer中两次添加适配器模块——在多头注意力后的投影之后和在两个前馈层之后。
- 右侧:适配器整体是一个bottleneck结构,包括两个前馈子层(Feedforward)和跳连接( skip-connection)。
Feedforward down-project:将原始输入维度d(高维特征)投影到m(低维特征),通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d;Nonlinearity:非线性层;Feedforward up-project:还原输入维度d,作为Adapter模块的输出。通时通过一个skip connection来将Adapter的输入重新加到最终的输出中去(残差连接)
def transformer_block_with_adapter(x):
residual = x
x = SelfAttention(x)
x = FFN(x) # adapter
x = LN(x + residual)
residual = x
x = FFN(x) # transformer FFN
x = FFN(x) # adapter
x = LN(x + residual)
return x
Pfeiffer等人发现,在自注意力层之后(在归一化之后)插入Adapter,可以达到媲美上述在Transformer块中使用两个Adapters的性能。
3.1.2 AdaMix(2022.3.24)
论文《AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning》
3.1.2.1 Mixture-of-Adaptations
在 AdaMix 中,作者将 Adapter 定义为:

其中,out 是 Feedforward up-project 映射(本文用FFN_U表示),而 in 则是Feedforward down-project 映射(本文用FFN_D表示),中间非线性层则选用 GeLU 函数。这些 E i = 1 N {E}_{i=1}^{N} Ei=1N称之为expert(专家)。受多专家模型 (MoE: Mixture-of-Experts)启发,本文提出了 Mixture-of-Adapter,即将每一个 Adpater 视作一个专家。
为了将网络稀疏化以保持FLOPs恒定,还有一个额外的门控网络 G G G,其输出是一个稀疏的N维向量。专家 E E E加上传统的门控单元 G G G,模型的输出可以表示为:

3.1.2.2 Routing Policy
最近的工作已经证明,随机路由策略(stochastic routing policy)与经典路由机制(如 Switch routing)具有相同的效果,并具有以下优势:
- 由于输入示例被随机 routed到不同的专家,因此不需要额外的负载平衡,因为每个专家都有平等的机会被激活,简化了框架
- 专家选择的 Switch layer层没有额外的参数,因此也没有额外的计算,保持了参数和FLOP与单个适配器模块相同,这对于我们的参数高效微调设置来说,尤为重要。
- 使得适配器模块能够在训练过程中进行不同的转换,并获得任务的多个views
所以对于适配器模块的随机路由策略(FFN_U和FFN_D可以随机选择来自不同的专家),有: x ← x + f ( x ⋅ W d o w n ) ⋅ W u p x\leftarrow x+f(x\cdot W_{down})\cdot W_{up} x←x+f(x⋅Wdown)⋅Wup
以M = 4个适应模块为例,AdaMix结构如下(包括FFN_U、FFN_D和投影矩阵):

如上图所示,首先模型只考虑一个主分支,即左边的,来将最终预测结果做损失;其次,为了保证训练高效,在确定了主分支随机选择的专家后,右分支需要满足两个 FFN 专家的选择均与主分支不同。损失函数即为主分支的交叉熵加上两个分支的 KL 一致性损失:
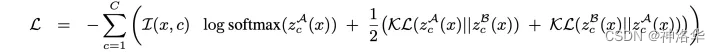
对于输入 x x x 在 L L L个 Transformer layers上。我们将特别添加一致性损失为任正则化项(
Consistency regularization),目的是使适配器模块共享信息并防止发散。
总体概括一下就是将门控单元替换为随机平均选择专家的方式(FFN_U和FFN_D随机选择),既减少了门控单元所消耗的参数和计算量,又能保证每个专家不会超负荷运作,同时精度也很好。
3.1.2.3 伪代码
def transformer_block_with_adamix(x):
"""
实现了带有AdaMix的Transformer块。其中包括自注意力层、残差连接和层归一化、前馈神经网络层以及AdaMix部分的实现
"""
residual = x
x = SelfAttention(x) # 自注意力层
x = LN(x + residual) # 残差连接和层归一化
residual = x
x = FFN(x) # 前馈神经网络层
# adamix开始
x = random_choice(experts_up)(x) # 随机选择上投影的expert
x = nonlinearity(x) # 非线性激活函数
x = random_choice(experts_down)(x) # 随机选择下投影的expert
x = LN(x + residual) # 残差连接和层归一化
return x
def consistency_regularization(x):
logits1 = transformer_adamix(x) # 使用不同的expert计算第一次前向传递的logits
# 第二次前向传递使用不同的expert
logits2 = transformer_adamix(x)
r = symmetrized_KL(logits1, logits2) # 对称化KL散度作为一致性正则化项
return r
AdaMix部分:
- 首先从上投影的expert中随机选择一个,并将输入x传递给该expert进行处理。
- 对输出进行非线性激活函数操作。
- 从下投影的expert中随机选择一个,并将激活后的结果传递给该expert进行处理。
- 将经过上述操作后的结果与残差连接,然后再进行层归一化,并返回结果。
consistency_regularization不分: - 使用AdaMix方法对输入x进行两次前向传递,每次选择不同的experts
- 计算这两次前向传递得到的logits之间的对称化KL散度,得到一致性正则化项并返回
代码中的
experts_up和experts_down是上投影和下投影的expert随机选择函数,而symmetrized_KL是对称化KL散度计算函数。
3.1.2.4 推理&实验结果
对于推理阶段,文章提出了另一个创新点——将所有 Adapter 混合,即将所有 Adapter 参数暴力平均啦,而不是像传统多专家模型中继续沿用门控单元或是随机分配,这样做是为了让参数和计算量达到最小和最高效。

下面是在GLUE开发集上使用RoBERTa-large编码器进行NLU任务的结果,可见AdaMix 甚至超过了微调整个模型的精度:

做成图就是:

3.1.2.5 总结
AdaMix通过以 MoE(mixture-of-experts)方式利用多个adapters来提高adapter的性能,这意味着每个adapter都是一组layers (experts),并且在每次前向传递中只激活一小组experts。
常规MoE使用路由网络选择和加权多个experts,而AdaMix在每次前向传递中随机选择一个expert,这降低了计算成本但不会降低性能。训练后,适配器权重在expert之间进行平均,这使得推理更加高效。
为了稳定训练,作者提出了consistency regularization方法,它通过最小化两个different sets of experts selected model的前向传递之间的对称化KL来实现。虽然提高了稳定性,但是这种方法增加了计算需求和内存消耗,因为它需要在两个具有不同expert是的模型前向传递中保留隐藏状态和梯度。所以,尽管AdaMix在相同的推理成本下实现了比常规适配器更好的性能,但在训练过程中可能使用更多的内存。
3.1.3 AdapterFusion&AdapterDrop
- AdapterFusion(EACL 2021 )
Adapter Tuning的优势在于只需添加少量新参数即可有效学习一个任务,这些适配器的参数在一定程度上表示了解决该任务所需的知识。受到启发,作者思考是否可以将来自多个任务的知识结合起来。为此,作者提出了AdapterFusion,这是一种新的两阶段学习算法,可以利用来自多个任务的知识,在大多数情况下性能优于全模型微调和Adapter Tuning。
- AdapterDrop(EMNLP 2021 )
作者通过对Adapter的计算效率进行分析,发现与全量微调相比,Adapter在训练时快60%,但是在推理时慢4%-6%。基于此,作者提出了AdapterDrop方法缓解该问题,其主要方法有:
- 在不影响任务性能的情况下,对Adapter动态高效的移除,提高模型在反向传播(训练)和正向传播(推理)时的效率。例如,将前五个Transformer层中的Adapter丢弃,推理速度提高了 39%,性能基本保持不变。
- 对 AdapterFusion中的Adapter进行剪枝。实验证明,移除 AdapterFusion 中的大多数Adapter至只保留2个,实现了与具有八个Adapter的完整 AdapterFusion 模型相当的结果,且推理速度提高了 68%。
更多详情请参考《大模型参数高效微调技术原理综述(四)》。
3.2 Soft Prompts
3.2.1 PET(Pattern-Exploiting Training,2020.1)
预训练语言模型(比如BERT),含有很全面的语言知识,并没有针对特定的下游任务,所以直接迁移学习的时候,可能模型不够明白你到底要解决什么问题,要提取哪部分知识,最后效果也就不够好。
标准范式pre-train, fine-tune转变为新范式pre-train, prompt, and predict之后,不再是通过目标工程使语言模型(LMs)适应下游任务,而是在文本提示(prompt)的帮助下,重新制定下游任务,使其看起来更像原始LMs训练期间解决的任务。 所以说,Prompt的核心思想,就是通过人工提示,把预训练模型中特定的知识挖掘出来,从而做到不错的零样本效果,而配合少量标注样本,可以进一步提升效果(提升零样本/小样本学习的效果)。
PET借助由自然语言构成的模版(英文常称Pattern或Prompt),将下游任务也转化为一个完形填空任务,这样就可以用BERT的MLM模型来进行预测了。PET有非常好的零样本、小样本乃至半监督学习效果(MLM 模型的训练可以不需要监督数据,因此理论上这能够实现零样本学习)。

当然,这种方案也不是只有MLM模型可行,如下图所示,用GPT这样的单向语言模型(LM)其实也很简单。不过由于语言模型是从左往右解码的,因此预测部分只能放在句末了(但还可以往补充前缀说明,只不过预测部分放在最后)。

然而,人工构建模版并不是那么容,而且离散文本输入的鲁棒性是很差的,不同prompt模版效果差很多。最后,这种离散模板表示也无法全局优化:

为了克服这些困难,提出了soft prompts/continuous prompts的概念。简单来说,就是用固定的token代替prompt,拼接上文本输入,当成特殊的embedding输入,来实现自动化构建模板。将寻找最佳提示(hard prompt)的离散优化问题转化为连续优化问题,减小了prompt挖掘、选择的成本。
3.2.2 Prefix-Tuning(Google 2021.1)
论文:《Prefix-Tuning: Optimizing Continuous Prompts for Generation》
3.2.2.1 简介
Prefix-Tuning即基于提示词前缀优化的微调方法,其原理是在输入token之前构造一段任务相关的virtual tokens(虚拟令牌)作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。
如下图所示,任务输入是一个线性化的表格(例如,“name: Starbucks | type: coffee shop”),输出是一个文本描述(例如,“Starbucks serves coffee.”)。图中左下红色部分是前缀表示的一系列连续的特定任务向量,也参入注意力计算,类似虚拟的tokens。
Fine-tuning会更新所有Transformer参数,所以对每个任务都要保存一份微调后的模型权重。而Prefix Tuning仅更新前缀部分的参数,这样不同任务只需要保存不同的前缀,微调成本更小。

3.2.2.2 算法
Prefix Tuning优化了前缀的所有层,比需要匹配实际单词嵌入的离散提示更具有表达力。Prefix的优化效果将向上传播到所有Transformer激活层,并向右传播到所有后续的标记,实验也显示Prefix效果优于infix(中缀)。此外,这种方法比干预所有激活层(第7.2节)更简单,避免了长距离依赖,并包含了更多可调参数(表达能力discrete prompting< embedding-only ablation < prefix-tuning)。
针对不同的模型结构,需要构造不同的Prefix:
- 自回归模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如GPT3的上下文学习)。 - 编码器-解码器模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
为了防止直接更新Prefix的参数导致训练不稳定和性能下降的情况,将Prefix部分通过前馈网络 P θ = F F N ( P ^ θ ) P_θ = FFN(\widehat{P}_{\theta }) Pθ=FFN(P
θ)进行映射。在训练过程中,优化 P ^ θ \widehat{P}_{\theta } P
θ和FFN的参数。训练结束后,推理时只需要 P θ P_θ Pθ,而可以舍弃FFN。

如上图所示, P i d x P_{idx} Pidx表示前缀索引序列,长度为 ∣ P i d x ∣ |P_{idx}| ∣Pidx∣。然后初始化一个可训练的矩阵 P θ P_θ Pθ,其维度为 ∣ P i d x ∣ × d i m ( h i ) |P_{idx}|×dim(h_i) ∣Pidx∣×dim(hi),用于存储前缀参数。所以当 i ∈ P i d x i ∈ P_{idx} i∈Pidx时,来自前缀部分的 h i h_i hi由可训练矩阵 P θ P_θ Pθ算出,其它的 h i h_i hi由Transformer计算得出,用公式表示就是:

其中, ϕ \phi ϕ表示自回归模型LM的参数,因为是自回归,只能看到当前位置i之前的信息,所以有 h < i h_{<i} h<i,表示 i i i之前的隐向量 h h h。伪代码表示如下:
def transformer_block_for_prefix_tuning(x):
soft_prompt = FFN(soft_prompt)
x = concat([soft_prompt, x], dim=seq)
return transformer_block(x)
该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
3.2.2.3 实验&总结
- 消融实验证实,只在embedding层加入Prefix效果不够好,因此,在每层都加了prompt的参数,改动较大。
- 在数据稀缺的情况下,前缀的初始化方式对性能有很大的影响。
-
随机初始化:前缀向量可以随机初始化为固定维度的向量。这种方法适用于一些简单的任务或数据较少的情况。
-
预训练:前缀向量可以通过预训练的语言模型进行初始化。例如,可以使用预训练的BERT或GPT模型,将其输出的某些层的隐藏状态作为前缀向量。
-
任务特定训练:前缀向量可以通过在特定任务上进行训练来获得。可以使用任务相关的数据对前缀进行有监督或自监督学习,以获得更具任务相关性的前缀向量。
-
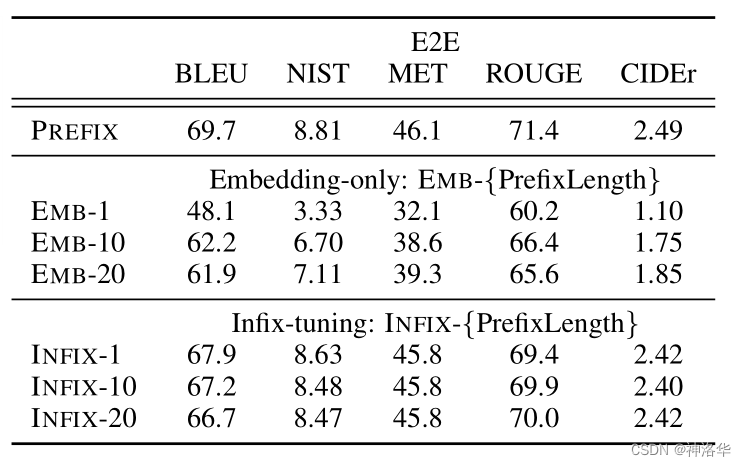 |
 |
|---|---|
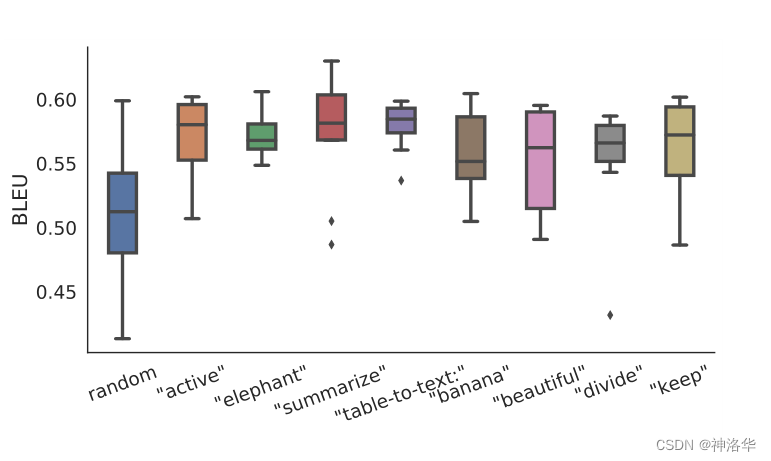
| 表4: prefix-tuning优于Embedding-only ablation和Infix-tuning | 图5:在数据稀缺的情况下,使用真实单词的激活值初始化前缀明显优于随机初始化。 |
从图5可见:
- 随机初始化会导致性能较低且变化较大,将前缀初始化为真实单词的激活值可以显著提高生成效果
- 使用与任务相关的单词(例如“summarization”和“table-to-text”)进行初始化的性能略优于与任务无关的单词(例如“elephant”和“divide”)
总结:在transformer的每一层都添加Prefix表示的soft prompt,为了保持训练稳定,输入前将其用FFN层进行映射。训练时只更新Prefix部分的参数。
3.2.3 Prompt Tuning(2021.4)
论文《The Power of Scale for Parameter-Efficient Prompt Tuning》
Prompt Tuning可以看做是Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。伪代码如下:
def soft_prompted_model(input_ids):
x = Embed(input_ids)
x = concat([soft_prompt, x], dim=seq)
return model(x)
下图展示了传统的微调和Prompt Tuning的区别:
- model tuning:每个下游任务都要进行一次定制的微调,然后保持不同的预训练模型副本,推理时必须以单独的批次进行
- Prompt Tuning:只需要为每个任务存储一个小的特定于task prompt,可以使用原始预训练模型进行混合任务推理

对于T5 XXL模型,每个调优模型的副本需要110亿个参数。Prompt Tuning每个任务只需要20,480个参数,假设提示长度为5个token,则减少了五个数量级。
同时,Prompt Tuning 还提出了 Prompt Ensembling,也就是在一个批次(Batch)里同时训练同一个任务的不同 prompt(即采用多种不同方式询问同一个问题),这样相当于训练了不同模型,比模型集成的成本小多了。
作者对prompt长度和预模型大小都做了消融实验。

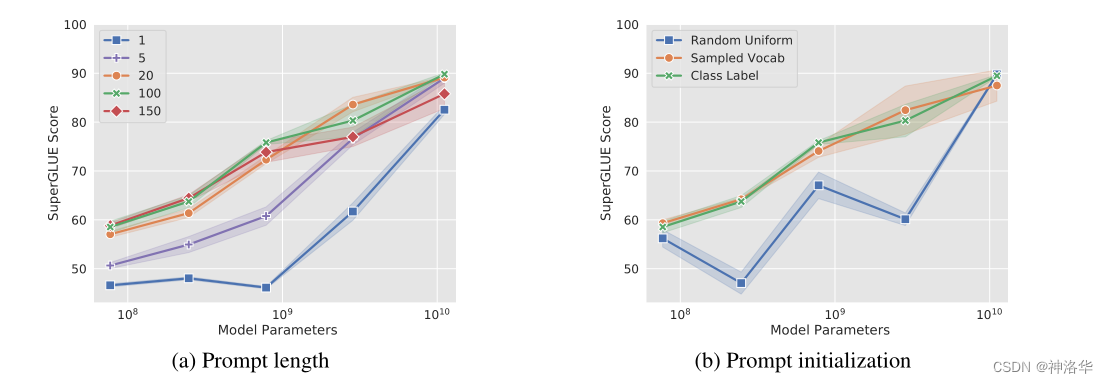
- Prompt长度:长度增加到20以上,通常能够显著提升性能
- prompt的初始化方式,除了随机初始化,另外两种都可以(直接使用任务的类别标签,或者采样词汇)
- 模型规模够大(>10B),Prompt长度和初始化方式都无所谓
3.2.4 P-tuning(清华2022.2)
3.2.4.1 原理
《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
直观来看,模版就是由自然语言构成的前缀/后缀,通过这些模版我们使得下游任务跟预训练任务一致,更充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。然而,并不关心模版长什么样,是否由自然语言组成的,只关心模型最终的效果。于是,P-tuning考虑了如下形式的模版:

这里的[u1]~[u6],代表BERT词表里边的[unused1]~[unused6],也就是用未知token来构成模板。然后,我们用标注数据来求出这个模板。(未知token数目是一个超参数,放在前面还是后面也可以调整。)
3.2.4.2 算法
-
模板的优化策略。
- 标注数据比较少:此时,我们固定整个模型的权重,只优化
[unused1]~[unused6]这几个token的Embedding。因为要学习的参数很少,因此哪怕标注样本很少,也能把模版学出来,不容易过拟合,而且训练很快。 - 标注数据很充足:此时只优化
[unused1]~[unused6]会导致欠拟合。因此,我们可以放开所有权重微调,原论文在SuperGLUE上的实验就是这样做的。但这样跟直接加个全连接微调有什么区别?作者的话说是这样做效果更好,可能还是因为跟预训练任务更一致了吧。
- 标注数据比较少:此时,我们固定整个模型的权重,只优化
-
目标token的选定
在上面的例子中,目标token如“体育”是人为选定的,那么它们可不可以也用[unused*]的token代替呢?答案是可以,但也分两种情况考虑:- 在标注数据比较少的时候,人工来选定适当的目标token效果往往更好些
- 在标注数据很充足的情况下,目标token用[unused*]效果更好些,因为这时候模型的优化空间更大一些。
-
接入LSTM
如果随机初始化virtual token,容易优化到局部最优值,而这些virtual token理论是应该有相关关联的(自然语言的相关性)。因此,作者通过一个LSTM+MLP去编码这些virtual token以后,再输入到模型。效果显示这样做模型收敛更快、效果更优。 -
优化:目标词预测→句子预测
苏剑林认为,LSTM是为了帮助模版的几个token(某种程度上)更贴近自然语言,但这并不一定要用LSTM生成,而且就算用LSTM生成也不一定达到这一点。更自然的方法是在训练下游任务的时候,不仅仅预测下游任务的目标token(如例子中的“新闻”),还应该同时做其他token的预测。
具体来说,如果是MLM模型,那么也随机mask掉其他的一些token来预测;如果是LM模型,则预测完整的序列,而不单单是目标词。因为模型都是经过自然语言预训练的,增加训练目标后重构的序列也会更贴近自然语言的效果。作者(苏剑林)测试发现,效果确实有所提升。
3.2.4.3 实验结果
-
SuperGLUE上的实验结果显示,无论是在BERT还是GPT上,
P-tuning的效果都优于Fine-tuning,且GPT的性能还能超过了BERT。

P-tuning在SuperGLUE上的表现,MP表示人工提示 。 -
P-tuning在各个体量的语言模型下的效果

3.2.4.4 对比Adapter/Prefix Tuning
- 对比Adapter:P-tuning实际上也是一种类似Adapter的做法,同样是固定原模型的权重,然后插入一些新的可优化参数,只不过这时候新参数是作为模板插入在Embedding层。
- 对比Prefix Tuning:P-Tuning加入的可微virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token插入的位置是可选的,不一定是前缀。
3.2.4.5 为什么P-tuning优于Fine-tuning
P-tuning和Fine-tuning都是微调所有权重,为什么P-tuning优于Fine-tuning?
这是因为,不管是PET还是P-tuning,它们其实都更接近预训练任务,而加个全连接层的做法,其实还没那么接近预训练任务,所以某种程度上来说,P-tuning有效更加“显然”,反而是加个全连接层微调为什么会有效才是值得疑问的。
在论文《A Mathematical Exploration of Why Language Models Help Solve Downstream Tasks》中,作者的回答是:
- 预训练模型是某种语言模型任务;
- 下游任务可以表示为该种语言模型的某个特殊情形;
- 当输出空间有限的时候,它又近似于加一个全连接层;
- 所以加一个全连接层微调是有效的。
所以说PET、P-tuning等才是更自然的使用预训练模型的方式,加全连接直接finetune的做法其实只是它们的推论罢了。也就是说,PET、P-tuning才是返璞归真、回归本质的方案,所以它们更有效。
3.2.5 P-tuning v2(清华2021.10)
《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》、 thudm/p-tuning-v2
3.2.5.1 背景
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
-
缺乏通用性。
- 缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
- 缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
-
缺少深度提示优化。
在Prompt Tuning和P-tuning中,prompt只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,prompt的位置的embedding是由之前的transformer层计算出来的,所以:- 由于序列长度的限制,可调参数的数量是有限的。
- 输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了P-tuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
3.2.5.2 算法
P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数:从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%,同时也足够参数高效。
- 深层结构中的Prompt能给模型预测带来更直接的影响。

P-tuning v2可以看做是优化后的Prefix Tuning:
-
移除重参数化的编码器:以前的方法利用重参数化功能来提高训练速度和鲁棒性(如:Prefix Tuning中的MLP、P-Tuning中的LSTM))。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型;同时对于某些NLU任务,使用MLP会降低性能
-
不同任务采用不同的提示长度:提示长度在P-Tuning v2中起着关键作用,不同的NLU任务会在不同的提示长度下达到其最佳性能。通常,简单的分类任务(情感分析等)偏好较短的提示(小于20个令牌);困难的序列标注任务(阅读理解等)则偏好较长的提示(大约100个令牌)

图4:使用RoBERTa-large进行的提示长度和重新参数化的消融研究。在特定的NLU任务和数据集中,结论可能会有很大不同。(MQA:多项选择问答) -
引入多任务学习:先在多任务的Prompt上进行预训练,然后再适配下游任务。多任务可以提供更好的初始化来进一步提升性能
-
回归传统的分类标签范式:标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,可以用完形填空的方式预测标签。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的。它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。

3.2.5.3 实验
- SuperGLUE
对于简单的NLU任务,如SST-2(单句分类),Prompt Tuning和P-Tuning在较小的规模下没有显示出明显的劣势。但是当涉及到复杂的挑战时,如自然语言推理(RTE)和多选题回答(BoolQ)时,它们的性能会非常差。相反,P-Tuning v2在较小规模的所有任务中都与微调的性能相匹配。

表2:在SuperGLUE开发集上的结果。FT表示Fine-tuning,PT和PT-2表示P-Tuning和P-Tuning v2。图中粗体是最佳,下划线表示第二佳 - 序列标注任务
GLUE和SuperGLUE的大多数任务都是相对简单的NLU问题。为了评估P-Tuning v2在一些困难的NLU挑战中的能力,作者选择了三个典型的序列标注任务(名称实体识别、抽取式问答(QA)和语义角色标签SRL),共八个数据集。我们观察到P-Tuning v2在所有任务上都能与Fine-tuning相媲美。
