
本文示例使用Jupyter作为编译器,零基础入门文件读取
首先确定你需要读取的文件的路径,如果小白对此感到吃力,可以选择直接将你想要读取的文件放入指定的路径中,以Jupyter为例,把将要读取的文件放入Jupyter的根目录(工作目录中),找不到这个文件夹在哪的朋友可以看我的另外一篇文章,专门介绍了怎么去找Jupyter的根目录。
我这里随便找了个交通道路数据文件放在了Jupyter的根目录下
读取文件excel文件(后缀名为.xlsx)
import pandas as pd
file_path = "traffic_data.xlsx" #文件地址
tr_data = pd.read_excel(file_path) #读取excel表
tr_data.head(10) #显示前十行数据运行效果: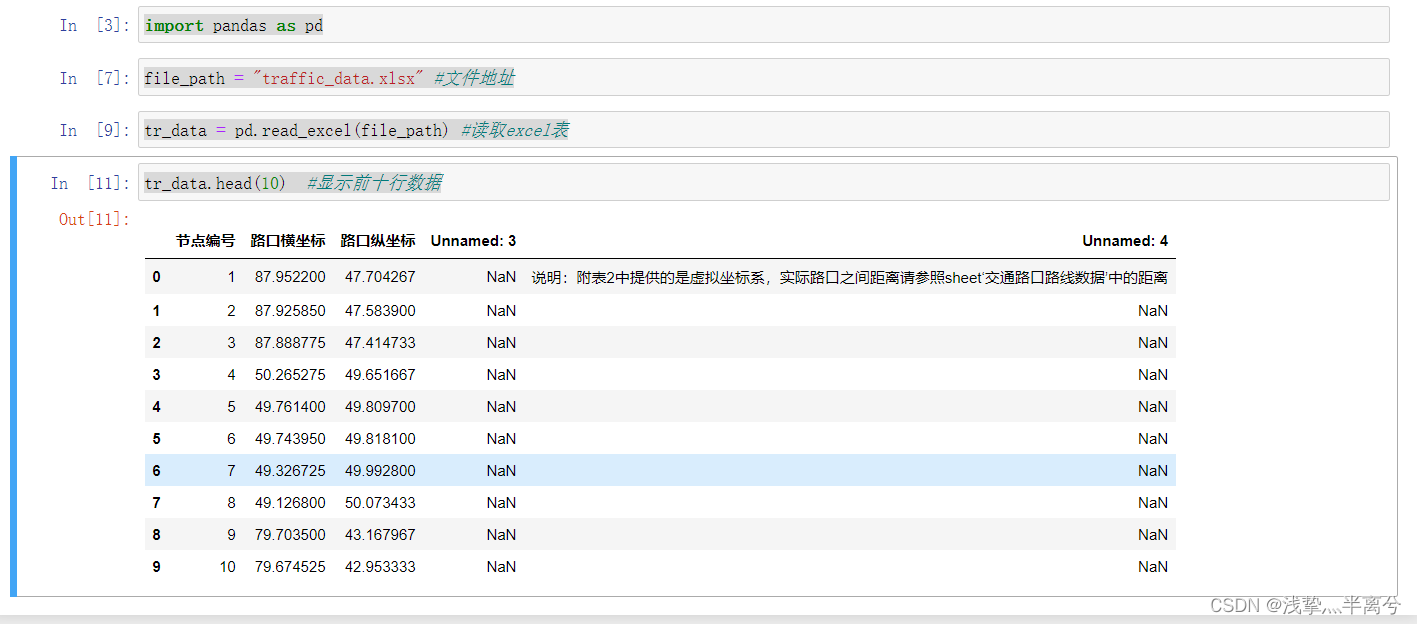
其他格式文件的读取方式同上,不再过多赘述。