
笔记整理:王润哲,东南大学硕士,研究方向为多元关系抽取
链接:https://aclanthology.org/2022.emnlp-main.448.pdf
动机
实体关系是知识图谱中不可或缺的一层重要信息,它们描述了实体之间的语义关系,这种连接使得知识图谱能够表达更为丰富的知识信息。过去学者们围绕实习关系及其抽取做出了许多工作,但是这些工作大都需要预先定义关系类型,而这样的人为定义常常会导致抽取到的实体关系覆盖范围较小,并不能够充分描述实体间的不同关系。同时作者认为基于传统关系建模方式构建的图谱能够提供的信息量是受限的,这些实体关系虽然精简但是会提升人们理解关系具体语义的难度。
为此本文提出了一种名为DEER的描述性知识图谱,用以更好地解释实体关系。与传统关系建模方法不同,DEER将实体之间的关系表示为开放文本关系描述,并不需要预先指定一组关系类型,这种建模方式更加灵活开放,并且能使得图谱包含更大的信息量。同时,针对这种新型的实体关系表示方式,本文提出了一种自监督学习的方法来抽取关系描述,利用一种基于transformer的关系描述合成模型即可不用人为标注而生成未被覆盖的实体的新关系描述。
贡献
(1)提出了一种描述性知识图谱(DEER),用于解释实体之间的关系
(2)提出了一种自监督的实体关系描述抽取方法,帮助构建DEER
(3)提出了对关系描述抽取效果的标准评估模型,帮助规范关系描述的生成
方法
关系描述抽取
关系描述抽取主要可以分成两个部分,第一个部分是对描述进行预处理和筛选,这部分的目的是获取到存在关系的实体对,并根据实体对获取其候选关系描述。为了提高关系的准确性,这里作者选择以Wikipedia这样的高质量语料库作为原始语料,后续的处理主要利用了多层次的规则以及一些现有工具完成,
第二部分是核心的打分环节,这里由于选用了Wikipedia这样一个本身就较为准确的语料,所以后续抽取关系描述时更加关注这些关系的明确性(explicitness)和重要性(significance)。这里为了更精简且准确地描述关系,作者选择采用实体间最短的依赖路径来作为核心路径(corePath)用以表示关系,同时会去掉一些不影响人们去阅读理解的部分使得表述减少冗余。描述实体关系和其他文本之间联系的次要路径(subPath)也会被收集起来,它也会以类似于核心路径的方式去描述其他一些关系模式。接下来就会对这些描述关系的路径进行明确性以及重要性的评估,明确性评估是依赖不同核心路径出现的频率计算得到的,公式如下:
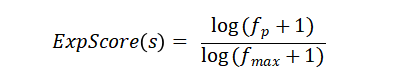
其中 和 分别代表当前核心路径的关系模式以及出现最频繁的核心路径关系模式各自的频率。对于关系重要性的评估则主要依赖次要路径的频率,计算公式如下:
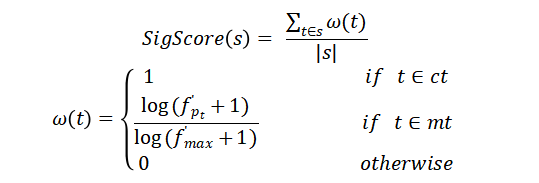
其中ct代表核心路径中的token,mt代表相关次要路径中的token, 和 则分别表示当前次要路径的关系模式以及出现最频繁的次要路径关系模式各自的频率。最终的得分函数基于先前算出的明确性分数以及重要性分数,计算公式如下所示:
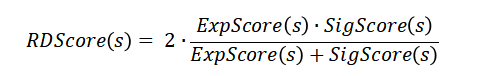
构建过程中会对每一对实体对计算其所有候选关系描述的分数,并取得分最高的作为最终的关系描述保留。
关系描述生成
这部分方法是对第一部分的补充,因为在实际构建过程中,会遇到某些相关的实体对,他们之间存在的关系在语料库中并没有对应的描述,换句话说可能不存在同时包含这对相关实体的句子,或者即使存在这样的句子也无法提取出相应的关系描述,因此这部分方法是为了生成这样相关实体对之间的关系描述。这个生成任务被定义为给定一对实体,在现有DEER的前提下生成句子描述实体间的关系,生成的关系描述的概率可以表示为:
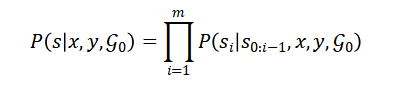
其中(x,y)代表给定的实体对, 代表初始的DEER,s即为生成的关系描述,m为这个描述的长度。
这里作者提出了一种关系描述的合成方式RelationSyn(Relation Description Synthesizing)来帮助合并 用于生成,框架如图1所示:
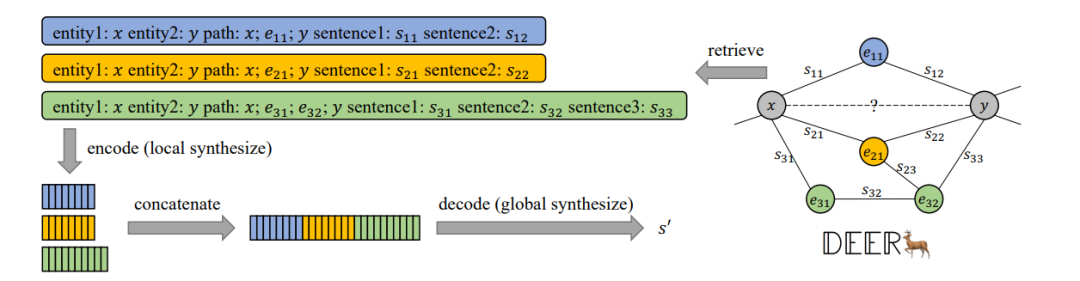
图1 RelationSyn框架图
这里可以看出RelationSyn主要分为两个部分,首先会检索相关的关系描述,然后再将它们合成最终的关系描述。由于一对实体之间可能存在多条可能的路径,所以作者设计了一个路径分数来评估不同推理路径的质量,计算公式如下所示:
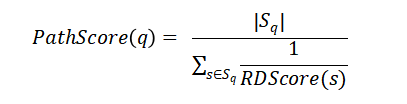
公式中q代表一条推理路径, 代表推理路径中的关系描述集合。同时作者提到,推理难度会随着推理路径长度的增加而提高,这也是一个需要考虑的因素。最终在检索路径时会先按照路径长度排序,路径比较短的优先级较高,路径评分则反映了路径的明确性和重要性,因此会在此基础上给予路径评分较高的以更高的优先级。
合成部分又可以分成编码和解码,作者又把它们称为Local synthesize和Global synthesize。大致的流程是先利用T5的编码器将路径转化为潜在向量,相同实体对的不同路径的潜在向量将会被拼接在一起,然后经过T5的解码器获取到最终的关系描述。
实验
实验和结果评估根据方法分成了两部分进行,对于抽取的关系描述采用了人工评估的方式,分数的数值范围为1-5。这里作者分别采用了明确性得分ExpScore,重要性得分SigScore,以及综合得分RDScore作为关系描述的筛选标准,同时加入了随机采样作为一种基础模式,对随机抽出的100个样本对比四种不同方式得到的关系描述获得的人工评分,验证了评估机制的有效性,四种不同模式的得分表1所示:
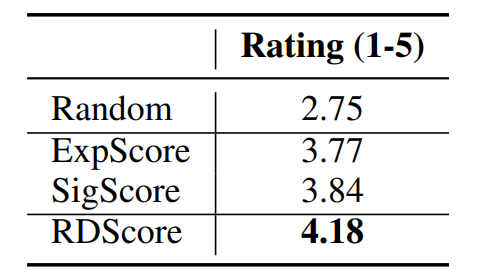
表1 关系描述抽取评分表
关系描述生成部分的实验依然是基于Wikipedia上的数据进行的,作者进行实验的方式为对已经存在关系描述的实体对,隐藏已有描述,并利用现存的推理路径复原原先存在的关系描述,这样便可以和本身不存在关系描述的实体对统一进行生成。模型设置方面,由于在本文之前只有一篇Open Relation Modeling的文章较为相关,所以作者主要对这篇文章中提出的模型以及本文提出模型的集中变体进行对比实验。采用的自动评估指标为BLEU、ROUGE-L、METEOR和BERTScore,结果如表2所示:
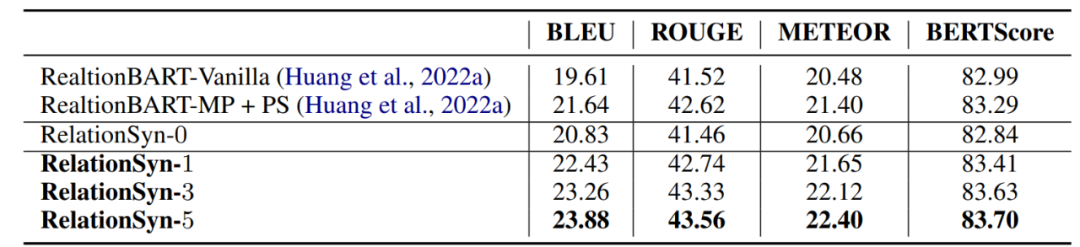
表2 关系描述生成的自动评估表
这里RelationSyn-m代表每一对实体最多检索的推理路径数目。同时作者也对文本描述的生成结果进行了人工评估,结果如表3所示:
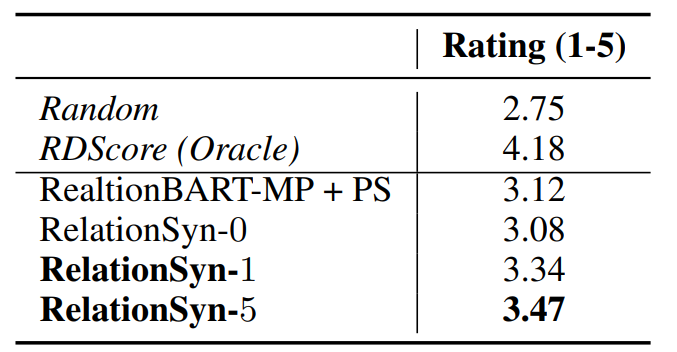
表3 关系描述生成的人工评估表
从实验结果可以看出本文提出的方法在对每个实体对仅仅检索一条推理路径时就已经超过了先前的工作,并且检索的推理路径越多,生成的结果越好,但是从表3可以看出生成的关系描述评分难以超越直接抽取出的关系描述,这可能是因为对本身不并不存在的描述进行生成难度较高。
总结
本文介绍了一种描述性知识图谱(DEER),用于解释实体之间的关系。DEER能够提供明确、重要且正确的关系描述,这在很大程度上超越了其他相关工作,例如Open Relation Modeling。通过使用DEER,研究人员可以从知识图谱中提取大量有用的信息,以帮助更好地理解实体之间的关系。此外,DEER还提供了一个处理关系描述的标准评估模型,以帮助研究人员在生成关系描述时做出更准确的决策。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。