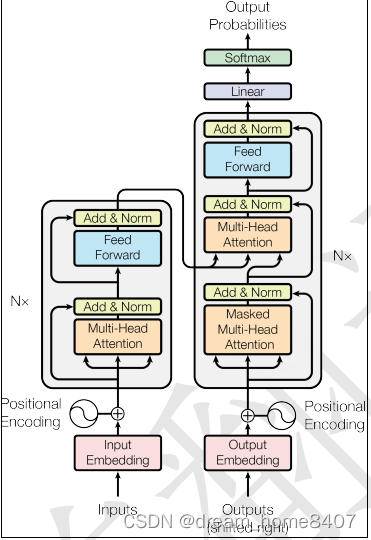
1.框架
Transformer和seq2seq一样由解码器和编码器组成,用多头注意力替换编码器和解码器架构中最常用的循环层
1.1 编码器:编码器有一堆N=6的相同层组成,每一层有两个子层,第一个子层包含多头注意力机制,第二个子层是前馈神经网络,每两个子层采用残差链接,然后进行归一化,为了保证残差链接维度一致,模型所有子层和嵌入层维度爆出在512,
1.2 解码器:解码器同样由N=6相同的层组成,除了和编码器有两个相同的子层以外,解码器第三个子层是带有掩码的注意力机制,Mask mutil-Head Attention ,做解码是一个自回归,需要确保当前时刻t的位置不会关注t以后的数据。
1.3 Linear + softmax:
全连接层和softmax函数,目的是将解码器的输出转换为预测的下一个token出现的概率,
2.整理运行流程
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
第二步:将得到的单词表示向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵,每一个 Encoder block 输出的矩阵维度与输入完全一致。
第三步:将 Encoder 输出的编码信息矩阵传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,
3.模块详细介绍
3.1 Embedding和Positional Embedding
Embedding是将计算机无法处理的单词或者汉字,转化成为计算机可以识别的向量,单词的Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
而Attention机制并没有考虑先后顺序信息,但前后顺序信息对语义影响很大,因此需要通过Positional Embedding这种方式把前后位置信息加在输入的Embedding上。
实现方式使用不同频率的sin和cos函数
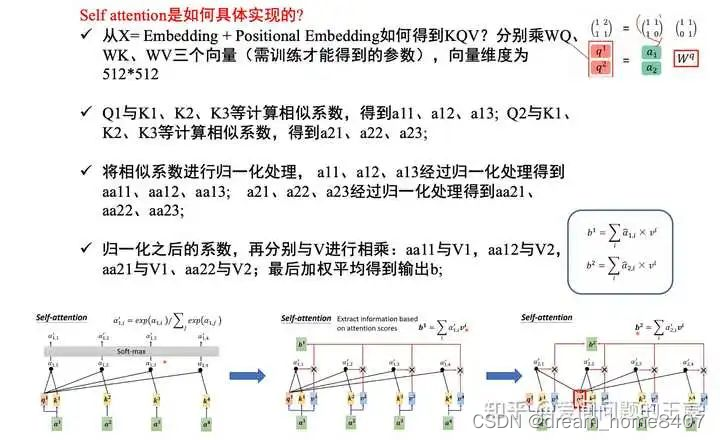
attention:对于序列数据而言,attention的本质就是通过权重矩阵计算找到输入中不同token之间的相互关系,函数是计算是由查询词q和键k做内积,然后除以根号输入向量的维度dk,并用softmax函数计算后乘以权重V,
(做内积的目的是计算q和k两个向量的相似度,两个向量越接近相似度越高,一个query中有n个q v 对,最后输出是n个结果,最后softmax会得到n个和为1的权重,乘以v得到最后的输出)
(和点积计算不同的是,除以根号dk,对于较小的dk,两中机制表现类似,dk较大时,点积计算的量级会增大很多,但是除以这个值的计算量就很小)
self-attention
Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
是什么:self attention是每一个Q与每一个K依次计算注意力系数,经softmax后最后乘V得到最后的输出结果,
Multi-Head Attention
Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。 h=8 时会得到 8 个输出矩阵Z。得到 8 个输出矩阵 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z,
Mask操作是如何具体实现的呢?
Q1只跟K1计算,Q2只跟K1、K2计算,而对于K3、K4等,在softmax之前给一个非常大的负数,由此经过softmax之后变为0

ADD
可以防止网络退化,常用于解决多层网络难训练的问题。
什么是Norm?
Norm就是layer normalization。
核心作用:为了训练更加稳定,和batch normalization有相同的作用,都是为了使输入的样本均值为零,方差为1。
为什么不使用batch normalization,使用的是layer normalization呢?因为一个时序数据,句子输入长度有长有短,如果使用batch normalization,则很容易造成因样本长短不一造成“训练不稳定”。BN是对同一个batch内的所有数据的同一个特征数据进行操作;而LN是对同一个样本进行操作。
什么是FFN?
FFN就是feed forward networks。
为什么有了Self attention层,还要有FFN?Attention已经有了想要的序列信息特征,MLP的作用是把信息投影到特定的空间里,再做一次非线性映射,和Self attention交替使用。
结构上:包括两层MLP,第一层的维度为5122048,第二层的维度为2048512,且第二层MLP没有使用激活函数