目录
摘要 5
序言 6
第一章 研究意义 7
1.1 研究意义 7
1.2 国内外研究现状 7
1.2.1 国内研究现状 7
1.2.2 国外研究现状 8
第二章 研究过程 9
2.1 图片识别 9
2.2 调用百度API 10
2.3 卷积神经网络 11
2.3.1 三维体积的神经元 12
2.3.2 卷积神经网络分层 12
2.4 研究过程 13
第三章 成果展示 13
3.1 效果展示 13
3.2部分核心代码展示 15
第六章 总结 16
摘要
图像识别技术已经应用于我们生活的方方面面,带给人们极大便利。物品识别的技术可以帮助人们迅速识别想知道的物品,在日常生活中,人们经常会遇到不认识的物品,或者对应品牌,物品识别技术将可以发挥重要作用;物品识别在很大程度上方便了日常生活,例如百度与淘宝可以直接拍照寻找相似词条或者产品。以上这些同时反映了我国科技水平稳步提升。
图像识别是人工智能的一个重要领域,图像识别的方法有很多,针对不同的具体方面的问题应合理采用不同的方法。图像识别的基础来自于人的图像识别能力,每个图像都有它的特征,对图像进行边界特征的提取并且设置窗口采用迭代计算像素点,具有较好的识别度和很高的实用性。
本文介绍了一种基于深度学习的AI智能识物的方法,基于深度学习的目标识别算法研究具有重大的意义,深度学习的目标识别算法对于未来能够使用目标检测和图像识别的手段运用于物联网,智能设备,生物制药等多领域有非常大的作用。
关键词:深度学习 图像识别 人工智能 特征
序言
当前是信息时代,信息的获得,加工,处理以及应用都有了飞跃提升,人们认识到世界的重要知识来源就是图像信息,在很多场合,图像所传送的信息比其他形式的信息更丰富,真切和具体。尤其是近年来,以图像,图像,视频等大容量为特征的图像数据处理广泛应用于医学,交通,自动化工业等领域。
深度学习是机器学习中的一个新的研究领域,通过深度学习的方法构建深度网络来抽取特征是目前目标和行为识别中得到关注的研究方向,引起更多计算机视觉领域研究者对深度学习进行探索和讨论,并推动了目标和行为识别的研究,推动了深度学习及其在目标和行为识别中的新进展。基于这个发展趋势,我们小组选择了基于深度学习的图像识别的研究。
第一章 研究意义
1.1 研究意义
在人类图像识别系统中,对复杂图像的识别往往要通过不同层次的信息加工才能实现。对于熟悉的图形,由于掌握了它的主要特征,就会把它当作一个单元来识别,而不再注意它的细节了。这种由孤立的单元材料组成的整体单位叫做组块,每一个组块是同时被感知的。在文字材料的识别中,人们不仅可以把一个汉字的笔划或偏旁等单元组成一个组块,而且能把经常在一起出现的字或词组成组块单位来加以识别。
在计算机视觉识别系统中,图像内容通常用图像特征进行描述。事实上,基于计算机视觉的图像检索也可以分为类似文本搜索引擎的三个步骤:提取特征、建索引build以及查询。
1.2 国内外研究现状
1.2.1 国内研究现状
在国内物品识别技术比较成熟,也有很多图像识别技术的软件,但是由于微信小程序发展没有很久,很少人去搭载物品识别技术去方便人们的生活。
一般工业使用中,采用工业相机拍摄图片,然后利用软件根据图片灰阶差做处理后识别出有用信息,图像识别软件国外代表的有康耐视等,国内代表的有图智能等。
图像识别的发展经历了三个阶段:文字识别、数字图像处理与识别、物体识别。文字识别的研究是从 1950年开始的,一般是识别字母、数字和符号,从印刷文字识别到手写文字识别, 应用非常广泛。
数字图像处理和识别的研究开始于1965年。数字图像与模拟图像相比具有存储,传输方便可压缩、传输过程中不易失真、处理方便等巨大优势,这些都为图像识别技术的发展提供了强大的动力。物体的识别主要指的是对三维世界的客体及环境的感知和认识,属于高级的计算机视觉范畴。它是以数字图像处理与识别为基础的结合人工智能、系统学等学科的研究方向,其研究成果被广泛应用在各种工业及探测机器人上。现代图像识别技术的一个不足就是自适应性能差,一旦目标图像被较强的噪声污染或是目标图像有较大残缺往往就得不出理想的结果。
图像识别问题的数学本质属于模式空间到类别空间的映射问题。目前,在图像识别的发展中,主要有三种识别方法:统计模式识别、结构模式识别、模糊模式识别。图像分割是图像处理中的一项关键技术,自20世纪70年代,其研究已经有几十年的历史,一直都受到人们的高度重视,至今借助于各种理论提出了数以千计的分割算法,而且这方面的研究仍然在积极地进行着。
现有的图像分割的方法有许多种,有阈值分割方法,边缘检测方法,区域提取方法,结合特定理论工具的分割方法等。从图像的类型来分有:灰度图像分割、彩色图像分割和纹理图像分割等。早在1965年就有人提出了检测边缘算子,使得边缘检测产生了不少经典算法。但在近二十年间,随着基于直方图和小波变换的图像分割方法的研究计算技术、VLSI技术的迅速发展,有关图像处理方面的研究取得了很大的进展。图像分割方法结合了一些特定理论、 方法和工具,如基于数学形态学的图像分割、基于小波变换的分割、基于遗传算法的分割等。
1.2.2 国外研究现状
目前国外有一些结合物品识别技术的软件app,app需要注册等操作,有些麻烦,具有很大的空缺,值得我们去研究。
第二章研究过程
2.1 图片识别
图像识别是人工智能的一个重要领域。为了编制模拟人类图像识别活动的计算机程序,人们提出了不同的图像识别模型。例如模板匹配模型。这种模型认为,识别某个图像,必须在过去的经验中有这个图像的记忆模式,又叫模板。当前的刺激如果能与大脑中的模板相匹配,这个图像也就被识别了。例如有一个字母A,如果在脑中有个A模板,字母A的大小、方位、形状都与这个A模板完全一致,字母A就被识别了。这个模型简单明了,也容易得到实际应用。但这种模型强调图像必须与脑中的模板完全符合才能加以识别,而事实上人不仅能识别与脑中的模板完全一致的图像,也能识别与模板不完全一致的图像。例如,人们不仅能识别某一个具体的字母A,也能识别印刷体的、手写体的、方向不正、大小不同的各种字母A。同时,人能识别的图像是大量的,如果所识别的每一个图像在脑中都有一个相应的模板,也是不可能的。
为了解决模板匹配模型存在的问题,格式塔心理学家又提出了一个原型匹配模型。这种模型认为,在长时记忆中存储的并不是所要识别的无数个模板,而是图像的某些“相似性”。从图像中抽象出来的“相似性”就可作为原型,拿它来检验所要识别的图像。如果能找到一个相似的原型,这个图像也就被识别了。这种模型从神经上和记忆探寻的过程上来看,都比模板匹配模型更适宜,而且还能说明对一些不规则的,但某些方面与原型相似的图像的识别。但是,这种模型没有说明人是怎样对相似的刺激进行辨别和加工的,它也难以在计算机程序中得到实现。因此又有人提出了一个更复杂的模型,即“泛魔”识别模型。
2.2 调用百度API
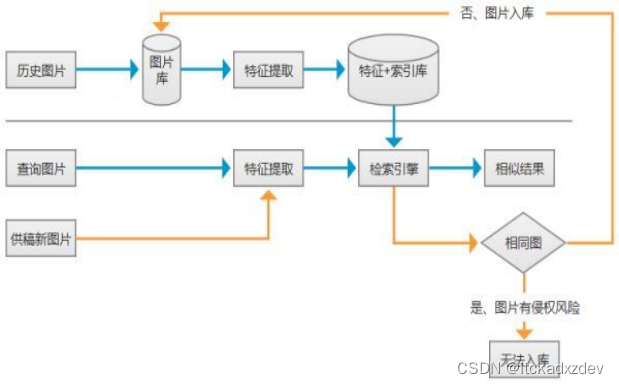
我们利用百度所提供的api服务实现图像的储存与处理,利用卷积神经网络分离,我们所上传图片的特征以及特点并归类为高度、宽度、深度三种参数,利用该参数组构成每张图片的特有标识并加以归类。

当我们再次输入图片进行识别时,首先从已经保存的特征库中搜寻该图片的识别结果,不管有没有结果,都依旧将这次所要识别的图片加以提取参数以及保存,在经过多次识别以后数据库中的特征参数会越来越多,以起到提高获得结果的概率和提高识别正确度。
2.3 卷积神经网络
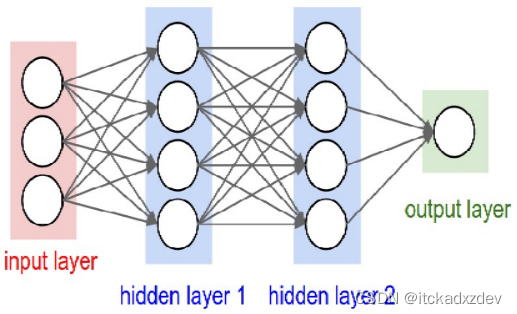
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
卷积神经网络与普通神经网络非常相似,它们都由具有可学习的权重和偏置常量(biases)的神经元组成。每个神经元都接收一些输入,并做一些点积计算,输出是每个分类的分数,普通神经网络里的一些计算技巧到这里依旧适用。
2.3.1 三维体积的神经元
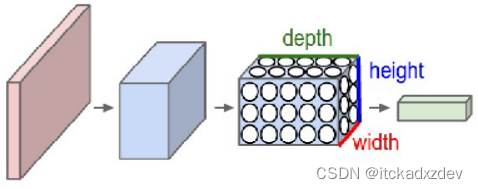
具有三维体积的神经元(3D volumes of neurons) 的卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width, height, depth(注意这个depth不是神经网络的深度,而是用来描述神经元的) 。比如输入的图片大小是 32 × 32 × 3 (rgb),那么输入神经元就也具有 32×32×3 的维度。下面是图解:
2.3.2 卷积神经网络分层
卷积神经网络通常包含以下几种层:
卷积层(Convolutional layer),卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
线性整流层(Rectified Linear Units layer, ReLU layer),这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU)f(x)=max(0,x)f(x)=max(0,x)。
池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
2.4 研究过程
第三章成果展示
3.1 效果展示




3.2部分核心代码展示

第四章 总结
有效的物品识别,可以方便人们更加方便的使用这个工具去识别自己想要了解的事物。手机打开微信小程序即可马上体验识图。
通过对项目的选题到研究,和团队攻克艰难,学习了大量人工智能算法,以及深度学习等技术,以及学习了微信小程序的制作去搭载这个物品识别的程序,可视化极强,可以实现用户交互。
这次的人工智能大作业是在其它五位成员共同努力下完成的。从项目选题到项目完成,团队之间进行紧密合作,头脑风暴,有了团队合作,互帮互助,团队才不会在设计的过程中迷失方向,失去前进动力。我们秉承着严肃的科学态度,严谨的治学精神和精益求精的工作作风,这些都是我们所需要学习的,感谢老师给予了我们这样一个学习机会。
参考文献:
[1]阮秋琦.数字图像处理[M].电子工业出版社,2010
[2]廉师友.人工智能技术导论[M].西安电子科技大学出版社,2007
[3]蔡自兴.人工智能及其应用[M].清华大学出版社, 2009
[4]高济.人工智能高级技术导论[M].高等教育出版社,2009
[5]李凡长.机器学习理论及应用[M].中国科技大学出版社, 2009
[6]韩力群.人工神经网络理论、设计及应用[M].化学工业出版社, 2007
[7]张洪刚.图像处理与识别[M].北京邮电大学出版社, 2006
[8]沈庭芝.数字图像处理及模式识别[M].北京理工大学出版社, 2002
[9]王新成.高级图像处理技术[M].中国科学技术出版社, 2001