Kafka集群搭建及生产者消费者案例
本文搭建的集群是采3台机器,分别是server01,server02,server03。linux系统是centos6.7。
kafka需要配合zookeeper使用,在安装kafka之前,需要先安装zookeeper集群,关于安装zookeeper集群,可以参考:Zookeeper集群环境搭建
一、Kafka集群搭建
1.1 下载kafka安装包
进入kafka的官方网站的下载页面,进行下载,下载页面链接如下:
本文安装的版本是:kafka_2.12-1.1.0.tgz
1.2 上传linux机器,解压,重命名
1.2.1 上传到server01机器的/hadoop目录
scp kafka_2.12-1.1.0.tgz hadoop@server01:/hadoop1.2.2 解压:
tar -zxvf kafka_2.12-1.1.0.tgz1.2.3 重命名为kafka
mv kafka_2.12-1.1.0 kafka1.3 配置kafka的配置文件
进入kafka/config目录,编辑server.properties文件,如图:
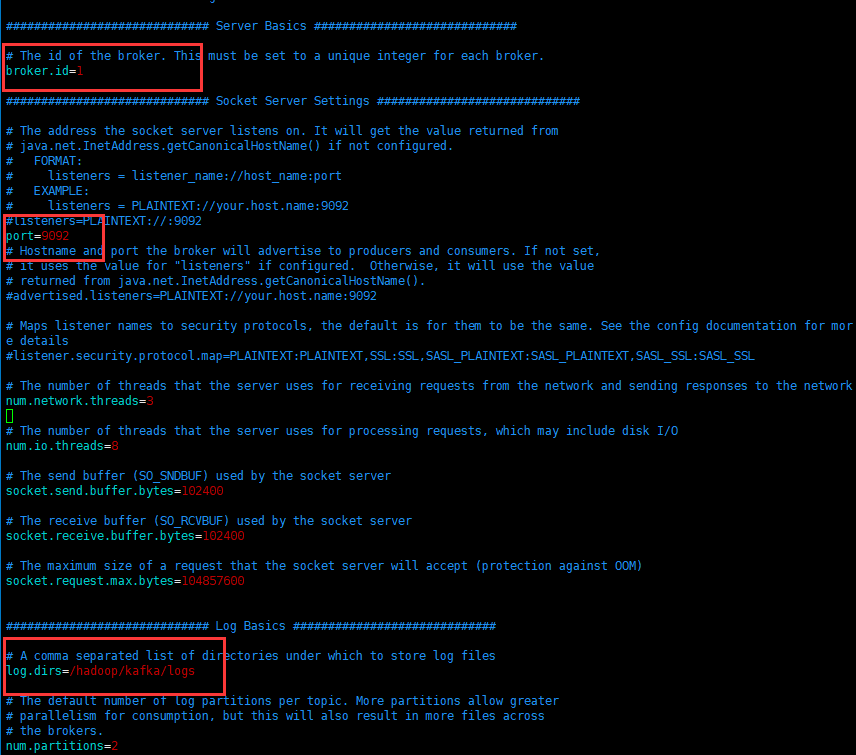
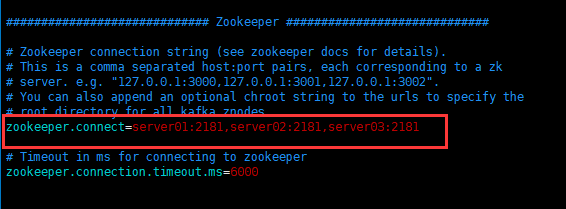
使用红色框出的是需要自己修改的,其余的默认就好
1.4 将kafka目录,分发到server02,server03机器上
scp -r /hadoop/kafka hadoop@server02:/hadoop
scp -r /hadoop/kafka hadoop@server03:/hadoop修改kafka/config/server.properties文件中的broker.id(重要)
如下所示:


1.5 设置环境变量
给每一台机器,配置环境变量
在/etc/profile文件末尾,写入如下环境变量
export KAFKA_HOME=/hadoop/kafka
export PATH=$PATH:$KAFKA_HOME/bin使环境变量生效
source /etc/profile1.6 启动kafka集群
在每一台机器上,启动kafka
# kafka目录,指定server.properties配置文件启动,-daemon:在后台启动
./bin/kafka-server-start.sh -daemon ./config/server.properties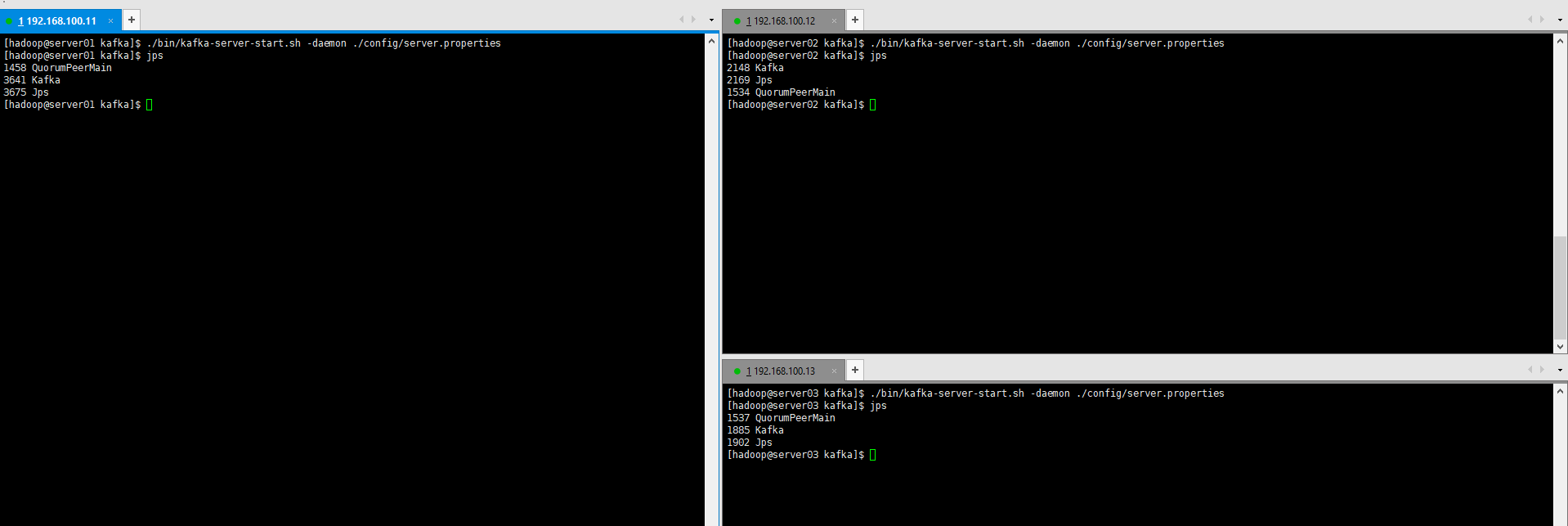
我们使用jps命令可以看到,3台机器的kafka都起来了。
注意一个问题:如果集群的broker.id重复,kafka起来后会挂掉
Kafka的常用命令介绍
- 启动
# 显示启动
./bin/kafka-server-start.sh ./config/server.properties
# 在后台启动
./bin/kafka-server-start.sh -daemon ./config/server.properties- 创建topic
# --create:表示创建
# --zookeeper 后面的参数是zk的集群节点
# --replication-factor 3 :表示复本数
# --partitions 3:表示分区数
# --topic test:表示topic的主题名称
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test- 查看topic
./bin/kafka-topics.sh --list --zookeeper server01:2181- 删除topic
删除topic,需要在server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
./bin/kafka-topics.sh --delete --zookeeper server01:2181 --topic test- 执行生产者命令
./bin/kafka-console-producer.sh --broker-list server01:9092 --topic test执行该命令,在命令窗口可以输入消息(生产消息)
- 执行消费者命令
# --from-beginning:表示从生产的开始获取数据
./bin/kafka-console-consumer.sh --zookeeper server01:2181 --from-beginning --topic test- 查看topic更详细的信息
./bin/kafka-topics.sh --topic test --describe --zookeeper server01:2181生产者和消费者案例
shell 实现
- 启动
zookeeper集群和kafka集群
- 启动
在安装的时候已经讲过
- 创建topic主题
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test_shell
- 在server01机器上执行生产者的命令
./bin/kafka-console-producer.sh --broker-list server01:9092 --topic test_shell- 在server02机器上执行消费者的命令
./bin/kafka-console-consumer.sh --zookeeper server01:2181 --from-beginning --topic test_shell- 在server01生产者命令窗口,输入一些消息按enter,效果如图:

- java api实现:
pom.xml配置kafka依赖:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
</dependency>
</dependencies>Producer生产者代码
public class KafkaProducer {
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
// 设置配置信息
p.put("serializer.class", "kafka.serializer.StringEncoder");// 指定序列化数据的对象,不然会导致序列化和传递的数据类型不一致
p.put("metadata.broker.list", "server01:9092");// 指定kafka broker对应的主机,格式为 host:port,host:port,...
ProducerConfig config = new ProducerConfig(p);
Producer<String, String> producer = new Producer<String, String>(config);
int count = 0;
while (true) {
// test_java:表示主题
KeyedMessage<String, String> message = new KeyedMessage<String, String>("test_java", "message_" + count);
// 发送消息
producer.send(message);
count++;
Thread.sleep(5000);
}
}
}Consumer消费者代码
public class KafkaConsumer {
public static void main(String[] args) {
Properties p = new Properties();
p.put("group.id", "testGroup");// 设置group.id,必须要设置,不然报错
p.put("zookeeper.connect", "server01:2181,server02:2181,server02:2181");//zk集群设置
p.put("auto.offset.reset", "smallest");//从头开始消费,如果是largeest:表示从最后开始消费
p.put("auto.commit.interval.ms", "1000");// consumer向zookeeper提交offset的频率,单位是秒
// 在“range”和“roundrobin”策略之间选择一种作为分配partitions给consumer 数据流的策略
p.put("partition.assignment.strategy", "roundrobin");
// 将属性添加到ConsumerConfig配置中
ConsumerConfig conf = new ConsumerConfig(p);
// 创建连接
ConsumerConnector connector = Consumer.createJavaConsumerConnector(conf);
Map<String, Integer> map = new HashMap<String, Integer>();
// 设置主题,并设置partitions分区
map.put("test_java", 2);
// 创建信息流,返回一个map,map里面装载是topic对应的流信息
Map<String, List<KafkaStream<byte[], byte[]>>> streams = connector.createMessageStreams(map);
// 通过主题topic获取留信息
final List<KafkaStream<byte[], byte[]>> kafkaStreams = streams.get("test_java");
// 通过线程池获取流信息的数据
ExecutorService service = Executors.newFixedThreadPool(4);
for (int i = 0; i < streams.size(); i++) {
final int index = i;
service.execute(new Runnable() {
public void run() {
//获取信息数据,包含topic,partition,message等信息
KafkaStream<byte[], byte[]> messageAndMetadatas = kafkaStreams.get(index);
for (MessageAndMetadata<byte[], byte[]> data : messageAndMetadatas) {
String topic = data.topic();
int partition = data.partition();
String message = new String(data.message());
// 信息输出至控制台
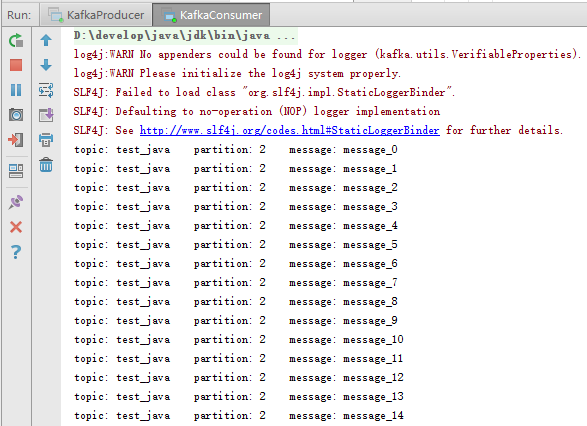
System.out.println("topic: " + topic + " partition: " + partition + " message: " + message);
}
}
});
}
}
}
创建topic主题:
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test_java执行结果: