Java编写网络爬虫
网络爬虫
网络爬虫(WEB crawler),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
1. 爬虫入门程序
导入依赖(下面列的程序用的是这个依赖,是版本5,我是从Maven中直接copy最新版的,没想那么多,但4点多的用的人多点,而且网上资料也多点,所以还是推荐大家用4点多的吧,但是下面用的是5的,下面代码部分也没啥差别就获取状态码的地方4本是getStatusLine().getStatusCode()然后5的话就是直接getCode(),还有就是5在设置请求参数的时候好像没有设置socket超时选项,4有,也有可能是我没找到):
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.2.1</version>
</dependency>
虽然下面程序用的是5,但还是推荐大家用4吧,人用的多,有问题的话网上也好查找错。
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.14</version>
</dependency>
public class CrawlerFirst {
public static void main(String[] args) throws IOException, ParseException {
// 1. 打开浏览器,创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 2. 输入网址,发起get请求创建HttpGet对象
HttpGet httpGet = new HttpGet("http://www.itcast.cn");
// 3. 按回车,发起请求,返回响应,使用HttpClient对象发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
// 4. 解析响应,获取数据
System.out.println(response.getCode());// 状态码
if(response.getCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"utf-8");// 得告诉编码为utf-8,不然html代码中文部分会乱码
System.out.println(content);// 这输出结果是那个页面的html字符串
}
}
}
网络爬虫
1. 网络爬虫的介绍
在大数据时代,信息的采集是一项非常重要的工作,而互联网的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为小编所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。
网络爬虫(Web Crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干个初始网页的URL开始,获取初始化网页上的URL,在抓取网页的过程中,不断从当前页面上抽取心的URL放入队列,直到满足系统的一定停止条件。
2. 为什么学习网络爬虫
- 可以实现搜索引擎
- 我们学会了爬虫编写之后,就可以利用爬虫自动地采集互联网中的信息,采集回来后进行相应的存储或处理,在需要搜索某些信息的时候,只需要在采集回来的信息中进行搜索,即实现了私人的搜索引擎。
- 大数据时代,可以让我们获取更多的数据源
- 在进行大数据分析或者进行数据挖掘的时候,需要有数据源进行分析。我们可以从某些提供数据统计的网站获得,也可以从某些文献或内容资料中获得,但是这些获得数据的方式,有时很难满足我们对数据的需求,而手动从互联网中去寻找这些数据,则耗费的精力过大。此时就可以利用爬虫技术,自动地从互联网中获取我们感兴趣的数据内容,并将这些数据内容爬取回来,作为我们的数据源,再进行更深层次的数据分析,并获得更有价值的信息。
- 可以更好地进行搜索引擎优化(SEO)
- 有利于就业。
- 从就业来说,爬虫工程师方向是不错的选择之一,因为目前爬虫工程师的需求越来越大,而能够胜任这方面的岗位人员较少,所以属于一个比较紧缺的职业方向,并且随着大数据时代和人工智能的来临,爬虫技术的应用将越来越广泛,在未来会拥有很好的发展空间。
HttpClient
网络爬虫就是用程序帮助我们访问网络上的资源,我们一直以来都是使用 HTTP 协议访问互联网的网页,网络爬虫需要编写程序,在这里使用同样的HTTP协议访问网页。
这里我们使用java的HTTP协议客户端 HttpClient 这个技术,来实现抓取网页数据。HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
HttpClient 功能介绍:
- 实现了所有HTTP方法
- 支持自动转向
- 支持https协议
- 支持代理服务器
实现步骤:
- 打开浏览器==》创建HttpClient对象,通过HttpClients.createDefault()可以得到
- 根据对应的请求方式创建HttpUriRequestBase子类对象,即HttpGet、HttpPost、HttpPut等等,构造其实例的时候将 url 参数进去,这个url既可以是字符串,也可以是URL对象.
- 发送请求==》使用httpClient对象去执行上面对应的请求。执行后会返回一个response对象。
- 使用response对象解析响应获取数据。
- 关闭资源
1. Get请求
public class HttpGetTest {
public static void main(String[] args) {
CloseableHttpResponse response = null;
// 1. 打开浏览器,创建httpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 2. 创建httpGet对象,设置url访问地址
HttpGet httpGet = new HttpGet("https://www.51cto.com/");
// 3. 使用httpClient发送请求,获取response
try {
response = httpClient.execute(httpGet);
// 4. 解析响应
if (response.getCode()==200) {
String content = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(content.length());
}
} catch (IOException e) {
throw new RuntimeException(e);
} catch (ParseException e) {
throw new RuntimeException(e);
}finally {
if(response!=null){
try {
response.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(httpClient!=null){
try {
httpClient.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
2. 带参数的GET请求
- 先创建httpClient实例
- 然后去得到uri对象,这个uri对象是通过URIBuilder对象构建的,创建URIBuilder对象
- 添加参数(不同的HttpClient依赖它设置参数的方法可能不同,低一点的版本是setParameter,高点的就如下所写),添加参数返回的是URIBuilder对象,所以可以链式地添加参数。
- 将uri对象(URIBuilder.build())传给对应的请求对象,访问uri访问地址。
- 执行对应的请求,获取相应结果集
- 处理数据
- 关闭资源
public class HttpGetWithParam {
public static void main(String[] args) throws IOException, ParseException, URISyntaxException {
// 1. 创建HttpClient实例
CloseableHttpClient httpClient = HttpClients.createDefault();
// 2. 根据相应的请求构造相应的Uri对象
// 先创建 URLBuilder
URIBuilder uriBuilder = new URIBuilder("https://so.51cto.com/");
// 设置参数
uriBuilder.addParameter("keywords","java爬虫").addParameter("sort","time");
// 创建httpGet对象,访问url访问地址
HttpGet httpGet = new HttpGet(uriBuilder.build());
// 3. 实现对应url对象,使用httpClient;然后即可获取到response
CloseableHttpResponse response = httpClient.execute(httpGet);
// 4. 拿到response对象即可获取数据
if (response.getCode()==200) {
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity, "utf-8"));
}
response.close();
httpClient.close();
}
}
3. Post请求
与 Get 请求的差异,只是将uri对象的设置那步,本是HttpGet改为HttpPost即可。
public class HttpPostTest {
public static void main(String[] args) throws IOException, ParseException {
// 1. 创建httpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 2. 创建HttpPost对象,设置uri访问地址
HttpPost httpPost = new HttpPost("https://www.51cto.com/");
// 3. 执行uri对象,然后获取response对象
CloseableHttpResponse response = httpClient.execute(httpPost);
// 4. 处理响应数据
if (response.getCode()==200) {
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity, "utf-8"));
}
// 5.关闭资源
httpClient.close();
response.close();
}
}
4. 带参数的 Post 请求
uri 地址中没有参数,参数 keys = java 放到表单中进行提交。
带参数的 Post 请求不同于带参数的 Get 请求直接把 uri 查询信息放 uri 上即可,我们需要将其参数内容传入到请求体中。
- 首先需要声明一个List即可,其声明的参数类型是
NameValuePair,我们往集合中添加 NameValuePair 的实现类BasicNameValuePair对象 - 然后再将其转化成
HttpEntity,下面是用的UrlEncodedFormEntity 实例(HttpEntity 的实现类),因为其构造方法中public UrlEncodedFormEntity(Iterable<? extends NameValuePair> parameters, Charset charset)是允许传入集合参数的,其他实现类像StringEntity是没这个的。- 这里需注意一个点:第二个参数是传入
Charset实例对象,而不是对应的编码字符串,人低版本都是重载后帮我们把传进去的字符串自动去转成实例对象,现在版本高了得我们自己转,真的是无语住了。使用 Charset.forName(“对应编码”) 即可。
- 这里需注意一个点:第二个参数是传入
- 然后我们将实体对象设置到httpPost uri对象中即可。
- 最后就是一致的操作,执行uri,获取结果,对结果处理,关闭资源…
public class HttpPostWithParam {
public static void main(String[] args) throws IOException, ParseException {
CloseableHttpClient httpClient = HttpClients.createDefault();
// 声明List集合,封装表单中的参数
List<NameValuePair> paramList = new ArrayList<NameValuePair>();
paramList.add(new BasicNameValuePair("keys","java"));
// paramList.add(new BasicNameValuePair("sort", "time"));
// 创建表单的 Entity 实体对象
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(paramList,Charset.forName("utf-8"));
// 设置表单的 Entity 实体对象到Post请求中
HttpPost httpPost = new HttpPost("https://www.itcast.cn/");
httpPost.setEntity(formEntity);
CloseableHttpResponse response = httpClient.execute(httpPost);
if (response.getCode()==200) {
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity, "utf-8"));
}
httpClient.close();
response.close();
}
}
5. 连接池
我们知道 HttpClient 实例对象相当于我们的一个浏览器,以上我们每次发个请求都得创建一个 HttpClient 对象,会有频繁创建和销毁的问题==》就相当于打开浏览器访问个页面后又关掉,又打开浏览器,访问完又关掉。
public class HttpClientPoolTest {
public static void main(String[] args) {
// 1. 创建连接池管理器
PoolingHttpClientConnectionManager httpClientPool = new PoolingHttpClientConnectionManager();
// 设置连接数
httpClientPool.setMaxTotal(100);
// 设置每个主机的最大连接数
httpClientPool.setDefaultMaxPerRoute(10);
// 2. 使用连接池管理器发起请求
doGet(httpClientPool);
doGet(httpClientPool);
doGet(httpClientPool);
httpClientPool.close();
}
private static void doGet(PoolingHttpClientConnectionManager httpClientPool) {
// 不是每次创建新的httpClient,而是从连接池中获取httpClient对象
// 下面这段代码的意义:先是从HttpClients工具类中通过custom方法获取到HttpClientBuilder对象
// 然后通过给HttpClientBuilder中的PoolingHttpClientConnectionManager连接管理对象赋值
// 最后build一个httpClient对象出来(即使你不这样去set连接池,你通过HttpClientBuild对象去build一个HttpClient实例也会去创建一个)
try {
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(httpClientPool).build();
HttpGet httpGet = new HttpGet("https://www.51cto.com/");
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getCode() == 200) {
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity, "utf-8"));
}
response.close();
// httpClient.close(); httpClient由于是交给了连接池管理,所以这里就不用关闭了,换句话说关连接池就行
}catch(Exception e){
e.printStackTrace();
}
}
}
以下是再次调用 doGet 后 httpClient 实例对象的地址,都不相同=》说明每次创建对象都是由连接池所分配的。
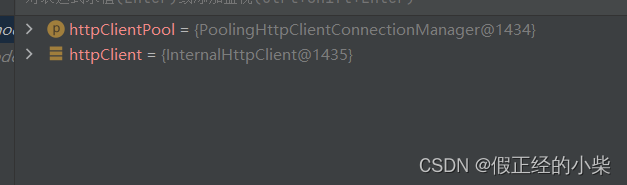
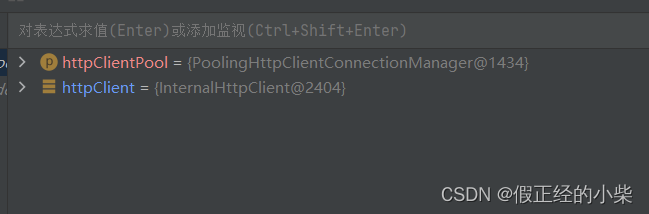
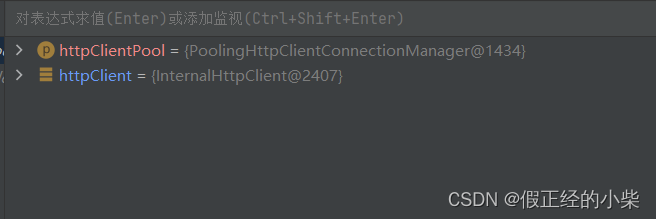
注意:有人不明白为什么要设置最大连接数后,还要再设置一个每个主机的最大连接数。其实原因很简单:设置了这个连接池后,是为了我们以后不必要在每个类中进行重复创建和销毁,那样会浪费空间,httpClient 实例对象的创建和销毁都交给连接池去管理。同时,当我们在进行网页信息爬取时会有多个不同主机 (“Host: www.csdn.net[\r][\n]”),像搜狐、新浪、腾讯…个人理解这样保证了爬取的准确和全面,就好比买菜。以自己拥有的钱数,分成若干等份,去不同的菜点购取质量好的菜。
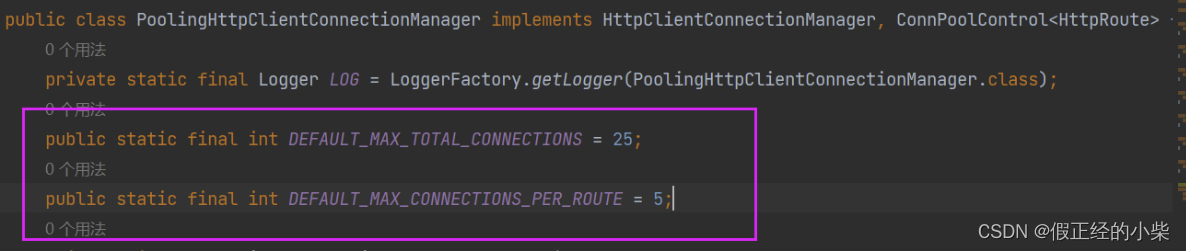
如果不设置总连接数和每台主机的最大连接数的话,以下参数是默认值(版本5才有默认值,4没有,要自己设):
6. 请求参数
有时候因为网络,或者目标服务器的原因,请求需要更长的时间才能完成,我们需要自定义相关时间。
public class HttpConfigTest {
public static void main(String[] args) throws IOException, ParseException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("https://www.51cto.com/");
// 配置请求信息
RequestConfig requestConfig = RequestConfig.custom()
.setConnectTimeout(Timeout.ofMilliseconds(1000L))// 创建连接的最长时间,毫秒
.setConnectionRequestTimeout(Timeout.ofMilliseconds(500L)).build();// 设置获取连接的最长时间,毫秒
// 给请求设置请求信息
httpGet.setConfig(requestConfig);
CloseableHttpResponse response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
System.out.println(EntityUtils.toString(entity, "utf-8"));
response.close();
httpClient.close();
}
}
Jsoup
我们使用 HttpClient 抓取到页面数据之后,还需要对页面进行解析。可以使用字符串处理工具解析页面,也可以使用正则表达式,但是这些方法都会带来很大的开发成本,所以我们需要使用一款专门解析 html 页面的技术-》jsoup。
1. jsoup 介绍
jsoup 是一款 Java 的HTML 解析器,全称是 Java HTML Parser,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可以通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
jsoup 的主要功能:
- 从一个 URL,文本或字符串中解析 HTML;
- 使用 DOM 或 CSS 选择器来
查找、取出数据; - 可
操作HTML 元素、属性、文本,和爬虫木得关系;
加入 jsoup 的依赖:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
其他工具类依赖(common-io=》处理文件需要、common-lang3=》需使用StringUtils处理字符串):
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
2.1 功能1.1-解析url
@Test
public void testUrl() throws Exception{
// 解析 url 地址,第一个参数是 URL对象,第二个参数是访问时候的超时时间
Document doc = Jsoup.parse(new URL("https://www.51cto.com/"), 10000);
// 使用标签选择器,获取title标签中的内容
String title = doc.getElementsByTag("title").first().text();
// 打印
System.out.println(title);// 技术成就梦想51CTO-中国领先的IT技术网站
}
注意:虽然使用 Jsoup 可以替代 HttpClient 直接发起请求抓取数据,但是往往不会这样用,因为实际开发过程中,需要使用到多线程,连接池,代理等等方式,而 jsoup 对这些的支持并不是很好,所以我们一般把 jsoup 仅仅作为 Html 解析工具使用。
2.2 功能1.2-解析字符串
使用 org.apache.commons.io.FileUtils 工具类去将html文件解析成字符串,然后用 jsoup 解析字符串。
@Test
public void testString() throws Exception {
// 使用工具类获取文件,获取字符串
String index = FileUtils.readFileToString(new File("C:\\Users\\myz03\\Desktop\\index.html"), "utf-8");
// 解析字符串
Document doc = Jsoup.parse(index);
// 使用标签选择器,获取td标签中的内容
Elements tds = doc.getElementsByTag("td");
tds.forEach(td->{
System.out.println(td.text());
});
}
2.3 功能1.3-解析文件
和上面解析字符串的效果一样。
@Test
public void testFile() throws Exception{
// 解析文件
Document doc = Jsoup.parse(new File("C:\\Users\\myz03\\Desktop\\index.html"));
// 使用标签选择器,获取td标签中的内容
Elements tds = doc.getElementsByTag("td");
tds.forEach(td->{
System.out.println(td.text());
});
}
3.1 功能2.1-使用 dom 方式遍历文档
元素获取:
- 根据 id 查询元素 getElementById;
- 根据标签获取元素 getElementByTag;
- 根据 class 获取元素 getElementByClass;
- 根据属性获取元素 getElementByAttribute;
@Test
public void testDom() throws Exception{
/*
1. 根据 id 查询元素 getElementById;
2. 根据标签获取元素 getElementByTag;
3. 根据 class 获取元素 getElementByClass;
4. 根据属性获取元素 getElementByAttribute;
*/
// 解析文件,获取Document对象
Document doc = Jsoup.parse(new File("C:\\Users\\myz03\\Desktop\\index.html"));
// 获取元素,根据id
Element div1Element = doc.getElementById("div1");
System.out.println(div1Element.text());
System.out.println("=====================");
// 获取元素,根据tag
Elements tds = doc.getElementsByTag("td");
tds.forEach(td->{
System.out.println(td.text());
});
System.out.println("===================");
// 获取元素,根据class
Elements a1s = doc.getElementsByClass("a1");
a1s.forEach(a1-> System.out.println(a1.text()));
System.out.println("======================");
// 获取元素,根据属性
Elements colspans = doc.getElementsByAttribute("colspan");
colspans.forEach(colspan-> System.out.println(colspan.text()));
}
从元素中获取数据
- 从元素中获取id;
- 从元素中获取 className;
- 从元素中获取属性的值 attr;
- 从元素中获取所有属性 attributes;
- 从元素中获取文本内容 text;
@Test
public void testData() throws Exception{
Document doc = Jsoup.parse(new File("C:\\Users\\myz03\\Desktop\\index.html"),"utf-8");
// 根据 id 获取元素
Element div1 = doc.getElementById("div1");
StringJoiner content = new StringJoiner("、");
// 1. 从元素中获取id;
content.add(div1.id());
// 2. 从元素中获取 className;
content.add(div1.className());
// 3. 从元素中获取属性的值 attr;
content.add(div1.attr("id"));
// 4. 从元素中获取所有属性 attributes;
Attributes attributes = div1.attributes();
attributes.forEach(attribute -> content.add(attribute.getKey() + ":" + attribute.getValue()));
// 5. 从元素中获取文本内容 text;
content.add(div1.text());
System.out.println(content.toString());
}
3.2 功能2.2-Selector 选择器概述
tagname:通过标签查找元素,比如:span
#id:通过 ID 查找元素,比如:# div1
.class:通过 class 名称来查找元素,比如:.a1
[attribute]:利用属性查找元素,比如:[target]
[attr=value]:利用属性值来查找元素,比如:[target=_blank]
@Test
public void testSelector() throws Exception {
Document doc = Jsoup.parse(new File("C:\\Users\\myz03\\Desktop\\index.html"), "utf-8");
// 通过标签查找元素
Elements ths = doc.select("th");
ths.forEach(th-> System.out.println(th.text()));
System.out.println("=============");
// 通过ID来查找元素,#id
Element div1s = doc.select("#div1").first();
System.out.println(div1s.text());
System.out.println("=============");
// 通过class名称来查找元素,.class
Elements a1s = doc.select(".a1");
a1s.forEach(a1-> System.out.println(a1.text()));
System.out.println("================");
// 通过attribute来查找元素,[attribute]
Elements colspans = doc.select("[colspan]");
colspans.forEach(colspan-> System.out.println(colspan.text()));
System.out.println("====================");
// 通过attribute=value来查找元素,[attribute=value]
Elements rowspans = doc.select("[rowspan=3]");
rowspans.forEach(rowspan-> System.out.println(rowspan.text()));
}
3.3 功能2.2plus-Selector 选择器的组合使用
- el#id:元素+ID,比如:div#div1
- el.class:元素+class,比如:a.a1
- el[attr]:元素+属性名,比如:td[colspan]
- 任意组合:比如:td[colspan].xxx
- ancestor child:查找某个元素下子元素,比如:div strong
- parent > child:查找某个父元素下的直接子元素:tr > td > a
- parent > *:查找某个父元素下的所有直接子元素
@Test
public void testSelectorPlus() throws Exception{
Document doc = Jsoup.parse(new File("C:\\Users\\myz03\\Desktop\\index.html"), "utf-8");
// el#id:元素+ID
Elements div1s = doc.select("div#div1");
div1s.forEach(div1-> System.out.println(div1.text()));
System.out.println("============");
// el.class:元素+class
Elements a1s = doc.select("a.a1");
a1s.forEach(a1-> System.out.println(a1.text()));
System.out.println("=============");
// el[attr]:元素+属性名
Element colspan = doc.select("td[colspan]").first();
System.out.println(colspan.text());
System.out.println("===============");
// 任意组合
Elements tdA1s = doc.select("td[colspan].xxx");
tdA1s.forEach(tdA1-> System.out.println(tdA1.text()));
System.out.println("=================");
// ancestor child:查找某个元素下子元素
Elements divStrongs = doc.select("div strong");
System.out.println(divStrongs.first().text());
System.out.println("===============");
// parent > child:查找某个父元素下的直接子元素
Elements selects = doc.select("tr > th");
selects.forEach(select-> System.out.println(select.text()));
System.out.println("==========");
// parent > *:查找某个父元素下的所有直接子元素
Elements mytrs = doc.select(".mytr > *");
mytrs.forEach(mytr-> System.out.println(mytr.text()));
}
入门案例
由于有一定的代码量,所以我放到了Gitee远程库中,赶兴趣可以去clone。
Java-Crawler