SpringBoot集成WebMagic实现爬虫出现的问题集(一)
一、SpringBoot集成WebMagic框架日志异常问题及解决方案
引入 WebMagic 需要两个依赖,一个是WebMagic核心依赖webmagic-core,一个是WebMagic拓展依赖webmagic-extension,一般使用拓展依赖去拓展一个日志实现。而 SpringBoot默认的日志框架是logback,然而webmagic-core依赖中还内部依赖着reload4j日志,会引起冲突。
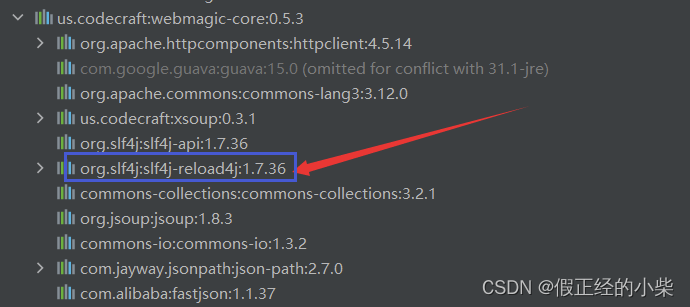
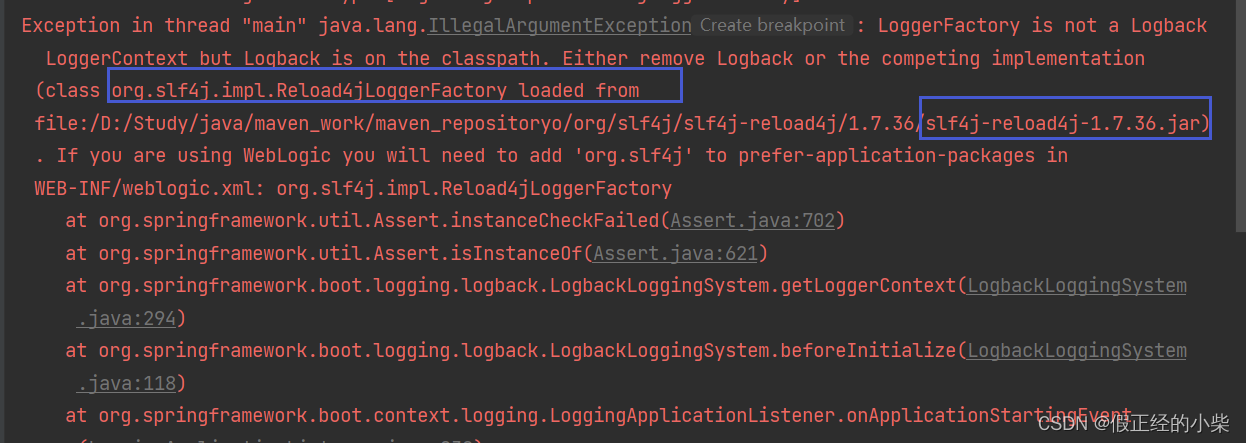
为了避免这个异常,可以删除这个reload4j日志内部依赖。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.5.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-reload4j</artifactId>
</exclusion>
</exclusions>
</dependency>
二、使用 Firefox 驱动(geckodriver)
由于 ChromeDriver 驱动要和其浏览器版本匹配,然而 Chrome 又有自动更新机制,所以容易造成版本不匹配问题,那解决方法自然是关闭 Chrome 的自动更新机制。但试了好多种方法都还是会自动更新,那自己选择驱动更新效果更好的 geckodriver 了。
下面是我现阶段的 Firefox 版本:
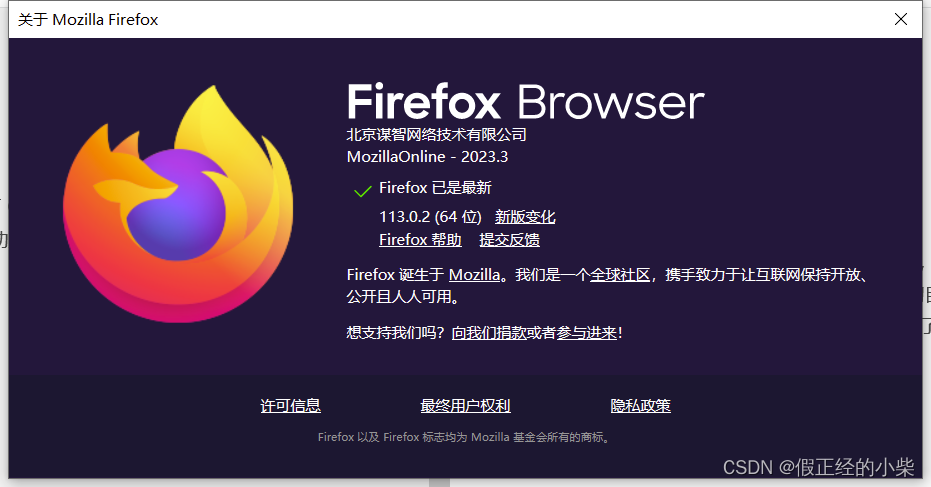
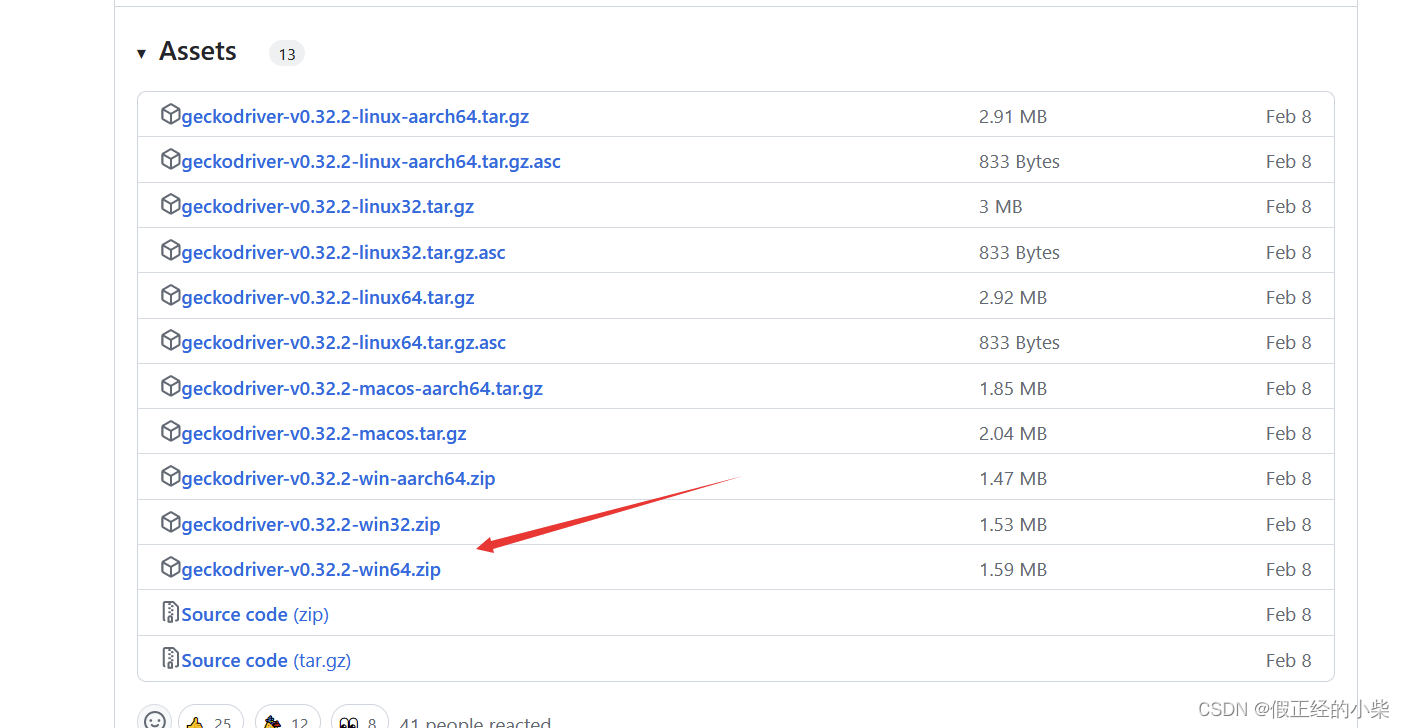
对应的驱动是0.32.2版本的(下载网址:https://github.com/mozilla/geckodriver/releases):
三、设置WebMagic中site中的User-Agent(避免反爬虫)
在进行爬虫的时候总是能遇到反爬虫的机制,有的时候是限制次数,有的时候就强行让你登录恶心你等等,那它在写反爬虫的时候,可能是根据你的user-agent身份来判断你是不是爬虫者的,那如果是这种情况的话,我们可以设置user-agent来进行反反爬虫。以下是设置的代码:
Site.me()
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
根据上面所述,也可以知道:即使使用了自定义的User-Agent,也不能保证100%避免被反爬虫机制识别,因此还需要结合其他反爬虫技术来提高爬虫的稳定性和可靠性。
扫描二维码关注公众号,回复:
15491606 查看本文章
