目录标题
1、数据与数据分析
数据分析是指用适当的统计分析方法对收集来的数据进行分析,将它们加以汇总和理解并消化,以求最大化地开发数据的功能,发挥数据的作用。
数据分析的目的是把隐藏在数据背后的信息集中和提炼出来,总结出所研究对象的内在规律,帮助管理者进行有效的判断和决策
数据分析作用:原因分析、现状分析、预测分析
2、数据分析基本步骤
步骤:明确目的和思路、数据收集、数据处理、数据分析、数据展现、报告撰写
- 把跟数据分析相关的营销、管理等理论统称为数据分析方法论。比如用户行为理论、PEST 分析法、5W2H 分析法等等。
- 数据收集:数据库、互联网、市场调查、公开出版物
- 数据处理主要包括数据清洗、数据转化、数据提取、数据计算等处理方法。
- 数据挖掘侧重解决四类数据分析问题:分类、聚类、关联和预测
- 数据展现:通过表格和图形的方式来呈现
- 数据分析报告:其实是对整个数据分析过程的一个总结与呈现
数据分析报告需要有明确的结论
好的分析报告一定要有建议或解决方案
3、大数据时代
大数据的特点:
Volume:数据量大,包括采集、存储和计算的量都非常大;
Variety:种类和来源多样化。包括结构化、半结构化和非结构化数据;
Value:数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵;
Velocity:数据增长速度快,处理速度也快,时效性要求高;
Veracity:数据的准确性和可信赖度,即数据的质量。
4、分布式技术
分布式系统是指:一个硬件或软件,其组件会分布在不同的计算机上,彼此之间仅仅通过网络消息传递进行通信和协调的系统。
简单来说就是一群独立计算机集合起来共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。
分布式(distributed):是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
集群(cluster):是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务
5、 Apache ZooKeeper
5.1 ZooKeeper 概述
学习一个软件:学习其定位、用来干什么、怎么用、特性和优缺点
Apache是一个软件基金会,大数据组件大多都是它孵化出来的
Zookeeper 是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题。类似十字路口的红绿灯
协调:如何控制大家有序的做某事
Zookeeper 本质:分布式的小文件存储系统
5.2 ZooKeeper 特性
-
全局数据一致:集群中每个服务器保存一份相同的数据副本,client 无论连接到哪个服务器,展示的数据都是一致的
事务性操作:增、删、改
非事务性操作:查
针对非事务性操作,因为不涉及数据修改,所以不需要维护一致性;
针对事务性操作,事务性请求都转发到leader,leader把所有的事物性请求进行编号,根据编号依次执行 -
可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
-
顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面
-
数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态
-
实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
5.3 ZooKeeper 集群角色
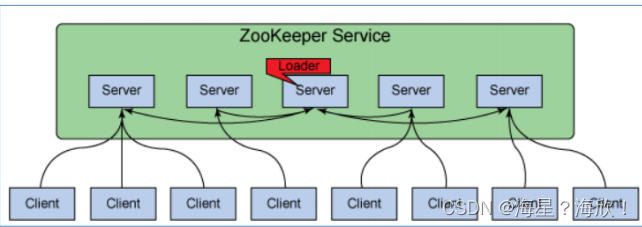
Leader:
Zookeeper 集群工作的核心
事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务器的调度者
Follower:
处理客户端非事务(读操作)请求,转发事务请求给 Leader;
参与集群 Leader 选举投票。
此外,针对访问量比较大的 zookeeper 集群,还可新增观察者角色。
为了扩大集群的读写能力,同时又不增加选举复杂度,增加了观察者角色
Observer:
观察者角色,观察 Zookeeper 集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给 Leader服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力
5.4 ZooKeeper 集群搭建
Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装。通常由 2n+1台 servers 组成。
因为要投票,所以 ZooKeeper 集群的数量一般为奇数
5.5 ZooKeeper 数据模型
一个标准的文件系统特征:
- 从/根目录开始
- 分为文件、文件夹
- 路径唯一
zookeeper文件系统特征:
- 从结构上看,也是类似于标准文件系统的目录树结构
- 里面没有文件、文件夹之分,所有节点统称为znode
- znode兼备文件夹、文件的特点
即可以像文件夹一样可以创建子目录,又像文件一样可以保存数据 - 路径也是从/根目录开始,唯一
客户端去操作zk集群分为几步?
- 客户端连接集群 建立会话
- 根据需求对zk目录树进行增删改查
- 客户端断开连接 会话结束
znode的类型:
- 永久节点:客户端创建znode后,将会一直存在,除非手动强制删除
- 临时节点:客户端创建znode后,只要断开连接,会话结束,znode就被删除。临时节点不允许拥有子节点
Znode 还有一个序列化的特性,如果创建的时候指定的话,该 Znode 的名字后面会自动追加一个不断增加的序列号。序列号对于此节点的父节点来说是唯一的,这样便会记录每个子节点创建的先后顺序。
这样便会存在四种类型的 Znode 节点,分别对应:
PERSISTENT:永久节点
EPHEMERAL:临时节点
PERSISTENT_SEQUENTIAL:永久节点、序列化
EPHEMERAL_SEQUENTIAL:临时节点、序列化