Zookeeper架构
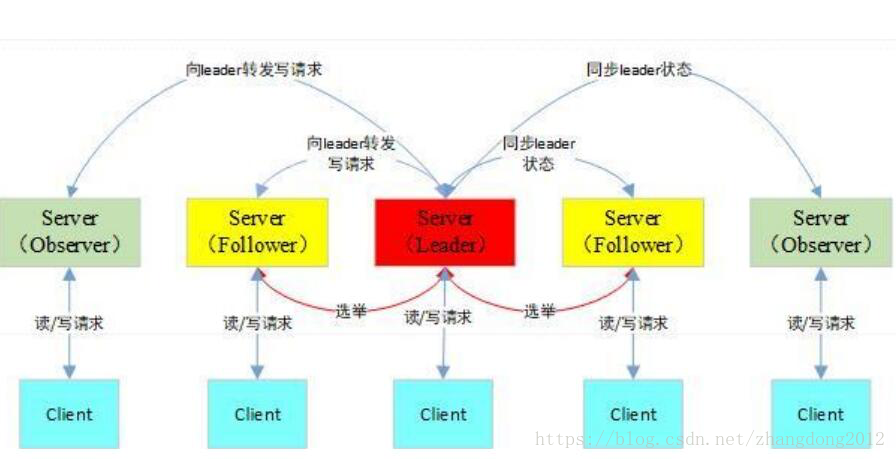
zookeeper采用典型的分布式主从架构,主节点称为leader,从节点称为follower/observer,Leader负责处理事务性请求,follower/observer从leader同步数据,follower/observer负责非事务性请求。
Zookeeper节点类型及职责
- leader:更新系统状态,处理事务请求,负责发起投票和决议
- follower:处理客户端非事务请求,将事务转发给leader,同步leader状态,选主过程中参与投票
- observer:处理非事务请求,同步leader数据(observer的主要作用是增加集群对非事务性请求对处理能力)
- client:请求发起方
Zookeeper写入流程
zookeeper采用zab原子广播协议算法来处理事务类请求,leader负责处理事务请求,follower会将事务请求转发到leader。
- 客户端向服务器发起事务请求,如果请求被发到follower,follower会把请求转发到leader
- leader生成一个全局唯一到事务id,将事务id(zxid)和事务请求组合起来加入到事务请求队列
- leader从队列中获取请求后扩散到follower
- 仲裁数的follower接收到follower请求后返回给leader一个ack确认信息
- leader再次向follower发送commit消息,仲裁数到follower提交成功后认为次事务请求完成
zookeeper的leader选举
明确leader选举前,需要先了解几个概念。
节点状态
- LOOKING:选择leader状态,处于该状态表示正在进行leader选举
- LEADING:leader状态,表示当前节点为leader
- FOLLOWING:follower状态,表示当前服务器为follower
- OBSERVER:观察者状态,表示当前服务器为observer
事务id
用zxid表示,由leader生成,全局唯一且单调递增
leader选举的种类
分为两种,一种是全新启动时期的leader选举,另一种是运行时leader宕机时的leader选举。
全新启动期的leader选举

- 所有服务器处理LOOKING状态,每个服务器向其他服务器广播投票消息(myid,zxid)
- 每个服务器接收到其他服务器的投票信息后,先比较zxid,再比较myid,选择较大的作为新的选举票,再向集群其他节点广播
- 当某个服务器被选举的数量达到仲裁数量时,这个节点就被选举为leader
- 各个节点修改自身状态,从LOOKING转变为LEADING和FOLLOWING
运行时期的leader选举
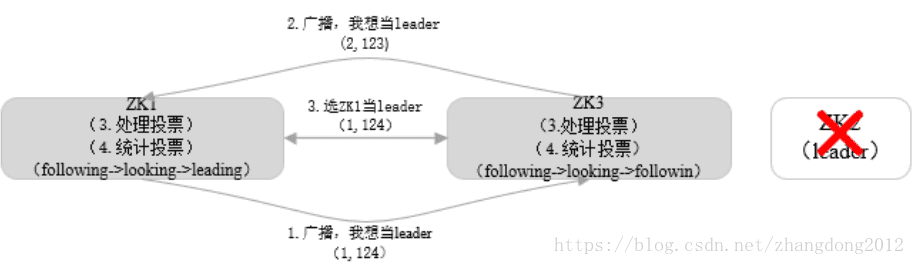
- 所有存活节点将状态该为LOOKING
- 每个节点向其他节点广播投票消息(myid,zxid)
- 处理投票,并再次广播投票消息
- 当有一个节点被仲裁数量当节点选为leader时,选举结束
- 各个节点修改自己当状态(LEADING/FOLLOWING)
Zookeeper的数据模型
- zookeeper以节点数的形式组织数据,每个节点被称为ZNode
- ZNode是zookeeper的最小存储单元
- 在ZNode上可以保存数据,同时也可以挂载子节点
Zookeeper的节点类型
节点类型可分为四种
1. 持久节点
2. 持久顺序节点
3. 临时节点
4. 临时顺序节点