注1:本文系“简要介绍”系列之一,仅从概念上对深度学习中的自注意力机制进行非常简要的介绍,不适合用于深入和详细的了解。
注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助
深度学习中的自注意力机制:原理与挑战
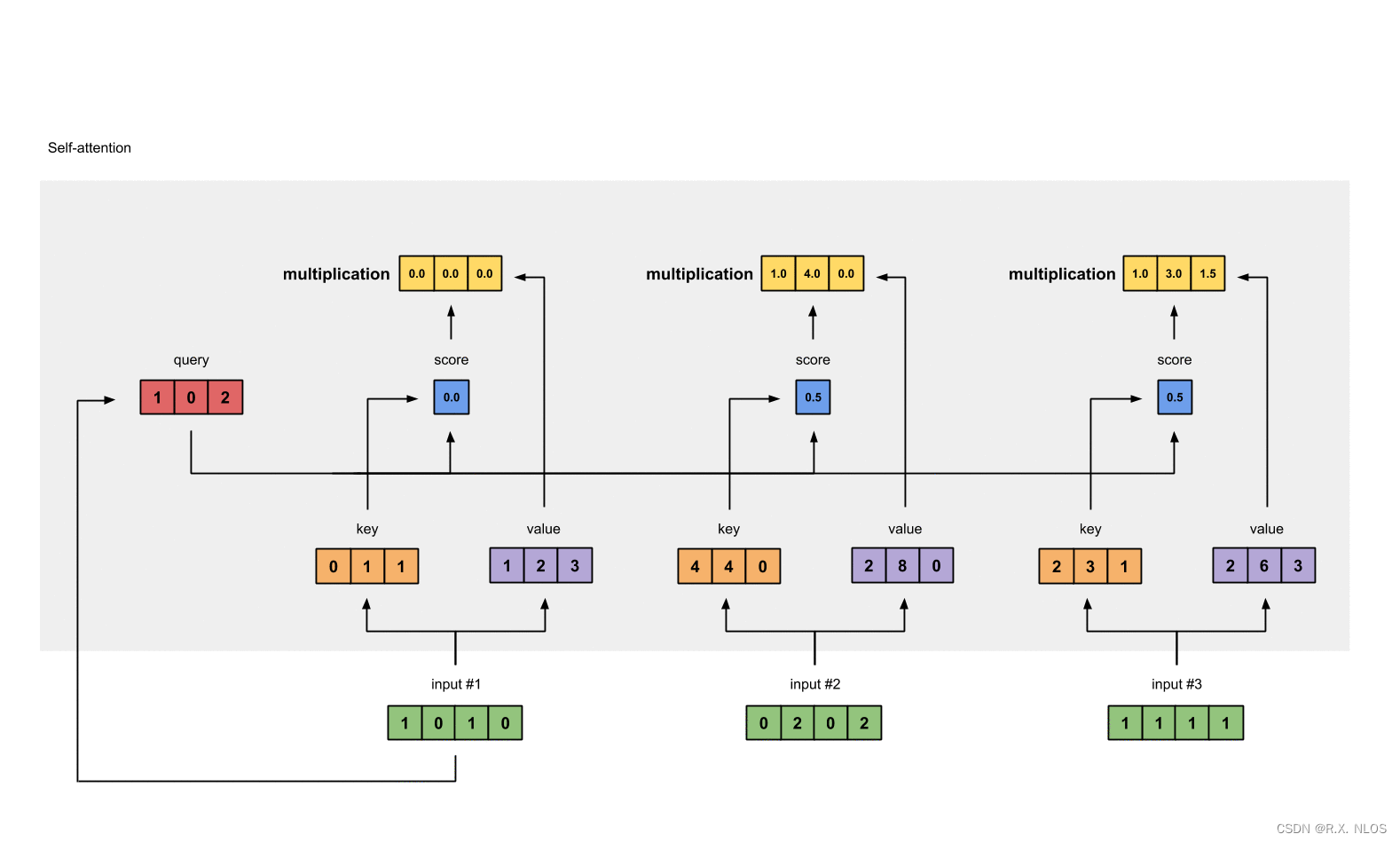
Illustrated: Self-Attention, A step-by-step guide to self-attention with illustrations and code
1 背景介绍
在过去的几年里,深度学习已经取得了巨大的成功。其中一个关键概念是自注意力机制(Self-Attention Mechanism),它在各种任务中都取得了显著的性能提升,如自然语言处理、计算机视觉和语音识别等。
2 原理介绍与推导
2.1 自注意力机制
自注意力机制的核心思想是通过关注输入序列中的不同部分以生成上下文感知的表示。这是通过计算输入序列中每个元素与其他元素之间的相似度分数来实现的。
假设我们有一个输入序列 X = { x 1 , x 2 , … , x n } \mathbf{X} = \{\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_n\} X={ x1,x2,…,xn},其中每个 x i ∈ R d \mathbf{x}_i \in \mathbb{R}^d xi∈Rd。自注意力机制试图学习一个能够捕获序列内部依赖关系的函数。
2.2 计算注意力分数
为了计算注意力分数,我们首先需要定义一个相似度度量。常见的方法是使用点积或加权欧式距离。在本文中,我们将使用点积作为示例。我们通过以下方式计算注意力分数:
score ( x i , x j ) = x i ⋅ x j \text{score}(\mathbf{x}_i, \mathbf{x}_j) = \mathbf{x}_i \cdot \mathbf{x}_j score(xi,xj)=xi⋅xj
2.3 计算注意力权重
计算得到注意力分数后,我们需要将其转换为权重。这是通过使用softmax函数来实现的:
α i j = exp ( score ( x i , x j ) ) ∑ k = 1 n exp ( score ( x i , x k ) ) \alpha_{ij} = \frac{\exp(\text{score}(\mathbf{x}_i, \mathbf{x}_j))}{\sum_{k=1}^n \exp(\text{score}(\mathbf{x}_i, \mathbf{x}_k))} αij=∑k=1nexp(score(xi,xk))exp(score(xi,xj))
2.4 计算上下文感知表示
最后,我们将注意力权重与输入序列的元素相结合,以获得上下文感知表示:
z i = ∑ j = 1 n α i j x j \mathbf{z}_i = \sum_{j=1}^n \alpha_{ij} \mathbf{x}_j zi=j=1∑nαijxj
3 研究现状
自注意力机制已经在许多成功的深度学习模型中得到应用,如Transformer和BERT等。这些模型在各种任务上都取得了显著的性能提升。
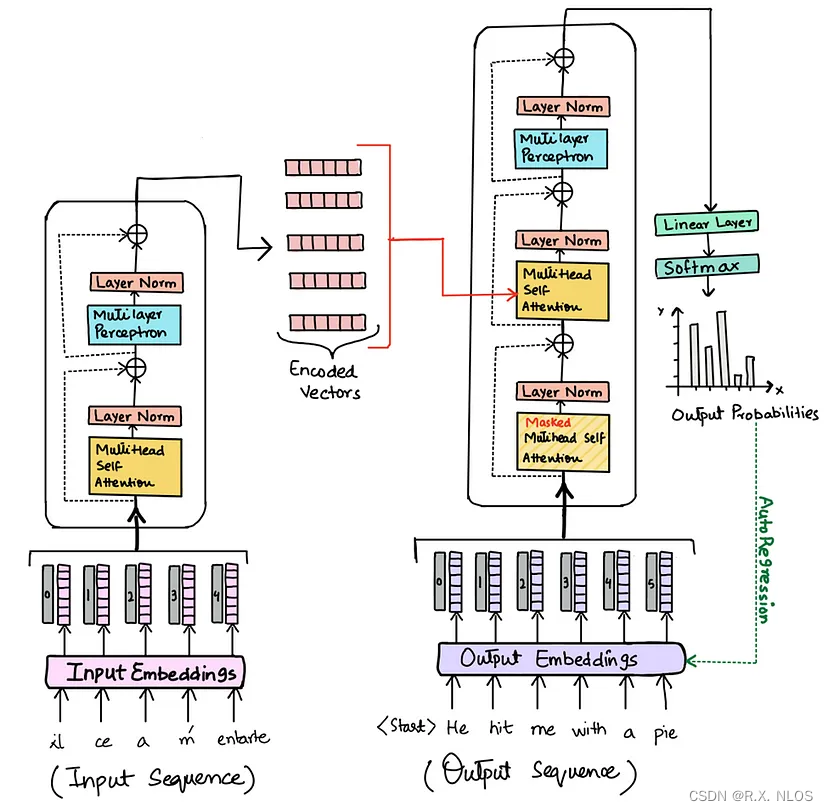
Transformer Architecture, Transformer: The Self-Attention Mechanism
3.1 Transformer
Transformer是一种基于自注意力机制的序列到序列模型。它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,完全依赖于自注意力机制来捕捉序列的依赖关系。Transformer 在机器翻译等任务中取得了显著的性能提升。
3.2 BERT
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer的预训练语言模型。它使用双向自注意力来捕捉上下文信息,并在许多自然语言处理任务中取得了领先的性能。
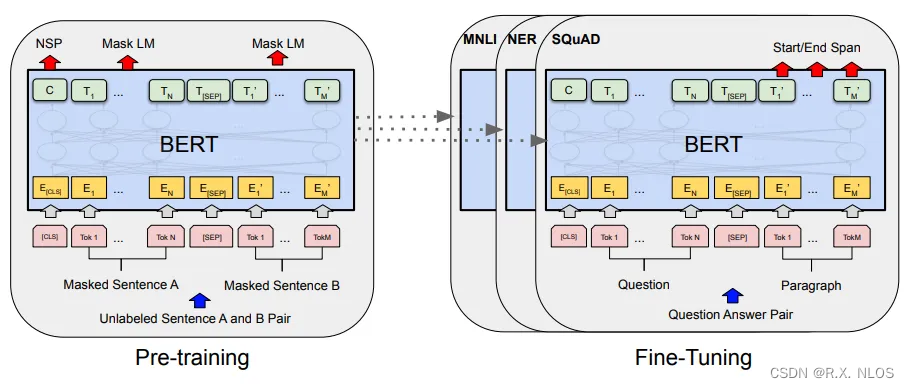
A schematic depiction of the BERT model and its training process , Language Understanding with BERT
4 挑战
尽管自注意力机制在很多任务中都取得了显著的性能提升,但它仍然面临着一些挑战:
- 计算复杂性:自注意力机制的计算复杂性随着序列长度的增加而呈二次增长。这使得处理长序列变得非常困难。
- 内存需求:由于自注意力机制需要存储所有元素之间的注意力权重,因此其内存需求也随着序列长度的增加而呈二次增长。
- 长距离依赖问题:尽管自注意力机制被认为可以捕捉长距离依赖,但在实践中仍然存在一些挑战,如梯度消失/爆炸问题等。
5 未来展望
为了解决上述挑战,研究人员提出了许多改进方法,如稀疏注意力、低秩注意力和滑动窗口注意力等。这些方法试图在保持自注意力机制性能优势的同时,降低计算复杂性和内存需求。
此外,研究人员还在探索将自注意力机制与其他类型的注意力机制(如局部注意力)相结合的方法,以充分利用它们各自的优点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oef7QvVu-1687083349577)(https://miro.medium.com/max/700/1*G8u5Q2szHril3knzDYPF9w.jpeg)]](https://img-blog.csdnimg.cn/a65e7770349747cfb355c654b69392e4.png)