在使用DPDK时,我们一般会用mbuf作为buffer,从mempool中分配。其实我们还可以直接用mempool的block作为buffer,或者memzone的block作为buffer,以及用rte_malloc的heap区作为buffer。但mbuf可以发送到以太网,其他方式分配的buffer,没有mbuf header,不能发送到网络。
基于mbuf的buffer
mbuf本身有最大64kB的buffer size限制。因为struct rte_mbuf中的字段uint16_t data_len;最大能表示64kB。https://elixir.bootlin.com/dpdk/latest/source/lib/mbuf/rte_mbuf_core.h#L656
使用mbuf有几种方式:普通alloc和快速alloc,其中快速alloc的性能更好,更推荐。
普通alloc
使用的步骤
-
创建mbuf的mempool,用rte_pktmbuf_pool_create_by_ops()分配mempool,同时指定pool的enq/deq方式。
-
rte_mbuf_raw_alloc()分配mbuf,用rte_mbuf_raw_free()释放mbuf。注意这2个API适合在每个mbuf里加些字段,不适合直接使用,因为mbuf header里的很多字段,都还没有初始化。
-
通过rte_pktmbuf_reset()初始化mbuf的header内容,就可以使用了。payload地址需要通过函数rte_pktmbuf_mtod()来偏移。
如无需初始化时标记每个buffer,那么直接调用rte_pktmbuf_alloc()也可以,步骤2,3合并为一步。
快速alloc
使用的步骤
-
分配mempool,通过rte_mempool_create_empty()创建空mempool,然后调用rte_mempool_set_ops_byname()配置enq/deq方式,rte_mempool_populate_default()在memzone中实际分配内存。
-
从mempool获得buffer,rte_mempool_get_bulk(rte_mempool,(void **)events, num);
-
通过rte_pktmbuf_reset(rte_mbuf)初始化mbuf header,为null或0等,就可使用mbuf了。如果跳过这一步,可能会导致mbuf使用时,出现莫名其妙的问题。
-
如果需要,还可以append一部分tailroom的空间,存需要的内容,rte_pktmbuf_append(mbuf, size)。
基于mempool的buffer
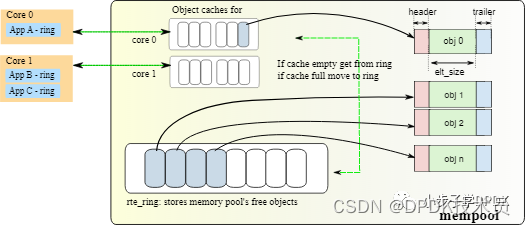
用mempool或memzone没有最大buffer大小为64kB的这个限制。而且因为不需要mbuf的header,可以节约一些内存,不需要填充mbuf的header内容,速度也会更快。
使用的步骤
-
创建一个空的mempool
-
通过API rte_mempool_create_empty()创建。
-
配置mempool的enq/deq方式,rte_mempool_set_ops_byname(),比如配置ring_mp_mc/ring_mt_rts/lf_stack。
-
在memzone分配内存。rte_mempool_populate_default()
-
-
分配buffer
通过rte_mempool_get/rte_mempool_get_bulk()的API即可。分配出的obj指针,直接就指向payload地址,不需要像mbuf一样偏移后,才能得到payload地址。bulk可以一次性拿到n个buffer,拿不到就返回0。不像burst可能返回小于n的buffer个数。但dpdk目前只支持bulk的方式取buffer。
-
释放buffer
通过rte_mempool_put/rte_mempool_put_bulk()。
注意,分配mempool的参数如下:
mp = rte_mempool_create_empty(name, n, block_sz, cache_sz, 0, SOCKET_ID_ANY, RTE_MEMPOOL_F_NO_IOVA_CONTIG);名称是参数name,总的buffer个数是n,每个buffer大小是block_sz,cache_sz是分配的cache大小。RTE_MEMPOOL_F_NO_IOVA_CONTIG表示可以基于非连续内存的分配,在IOVA=PA的环境下尤其有用,IOVA=PA表示硬件看到的实际物理地址是需要连续的。如果出现没有连续的物理内存,会导致没法分配buffer。
基于memzone的buffer

分配的步骤
-
先看这个名称的memzone是否被使用了,rte_memzone_lookup(name)。
-
如果名称没被使用,可以reserve。mz = rte_memzone_reserve_aligned(name, size, SOCKET_ID_ANY, 0, 64);
注意返回的地址是mz->addr,而不是直接用mz。
释放的步骤
-
先看这个名称的memzone是否被使用了,rte_memzone_lookup(name);
-
释放这个memzone,rte_memzone_free(mz);
查找的步骤
rte_memzone_lookup(name);
基于DPDK heap的buffer
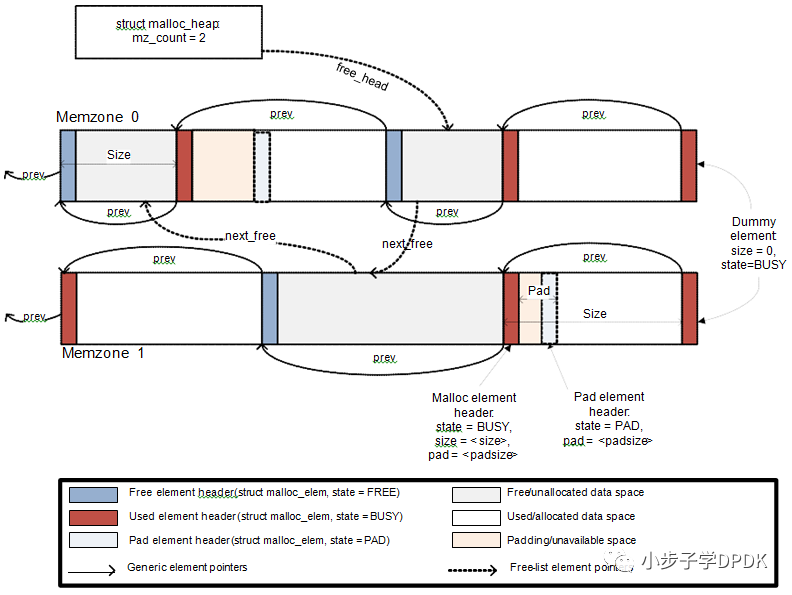
和linux的malloc/free类似。而且也可以使用非连续的内存。用的是memzone之外的内存。
分配的方式是:
*ptr = rte_zmalloc(NULL, size, 64);
释放的方式是:
rte_free(ptr);
原文链接:https://mp.weixin.qq.com/s/duqEGmu-fUWzoxRi0SnA_Q
学习更多dpdk视频
DPDK 学习资料、教学视频和学习路线图 :https://space.bilibili.com/1600631218
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 学习地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 君羊909332607备注(XMG) 获取