注1:本文系“简要介绍”系列之一,仅从概念上对交叉熵损失进行非常简要的介绍,不适合用于深入和详细的了解。
注2:"简要介绍"系列的所有创作均使用了AIGC工具辅助
交叉熵损失:原理、研究现状与未来展望
1 背景介绍
在机器学习和深度学习的领域中,损失函数是评估模型表现的关键工具。损失函数的优化使得我们能够改进模型的预测能力。其中,交叉熵损失 (Cross Entropy Loss) 是一种广泛应用于分类问题的损失函数。
2 原理介绍与推导
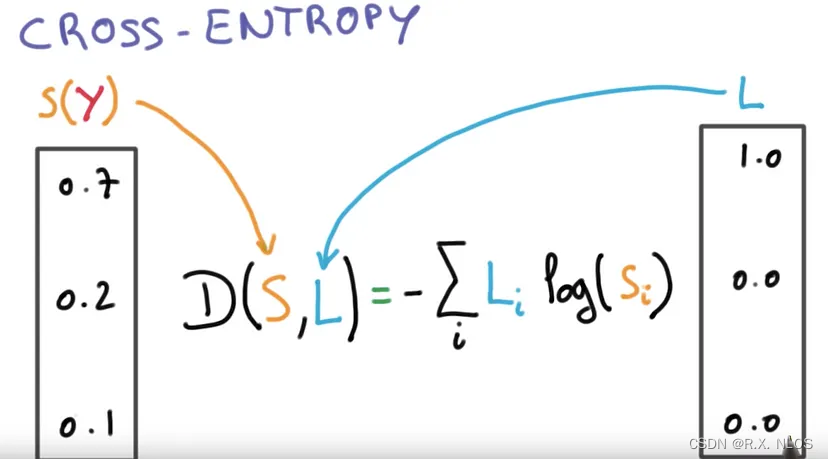
交叉熵损失 是衡量两个概率分布之间差异的度量方法。在分类问题中,交叉熵损失用于衡量模型预测的概率分布与真实标签的概率分布之间的差异。
给定一个训练样本 ( x , y ) (x, y) (x,y),其中 x x x 是输入特征, y y y 是真实标签。假设模型预测的概率分布为 P ( y ∣ x ) P(y|x) P(y∣x),而真实标签的概率分布为 Q ( y ∣ x ) Q(y|x) Q(y∣x)。交叉熵损失定义为:
H ( P , Q ) = − ∑ y P ( y ∣ x ) log Q ( y ∣ x ) H(P, Q) = - \sum_{y} P(y|x) \log Q(y|x) H(P,Q)=−y∑P(y∣x)logQ(y∣x)
在分类问题中,真实标签的概率分布是一个 one-hot 编码,即对于正确的类别,概率为1,其他类别概率为0。因此,交叉熵损失可以简化为:
H ( P , Q ) = − log Q ( y t r u e ∣ x ) H(P, Q) = - \log Q(y_{true}|x) H(P,Q)=−logQ(ytrue∣x)
其中 y t r u e y_{true} ytrue 是正确的类别。在实际应用中,我们通常使用平均交叉熵损失来评估模型在整个训练集上的性能。
3 研究现状
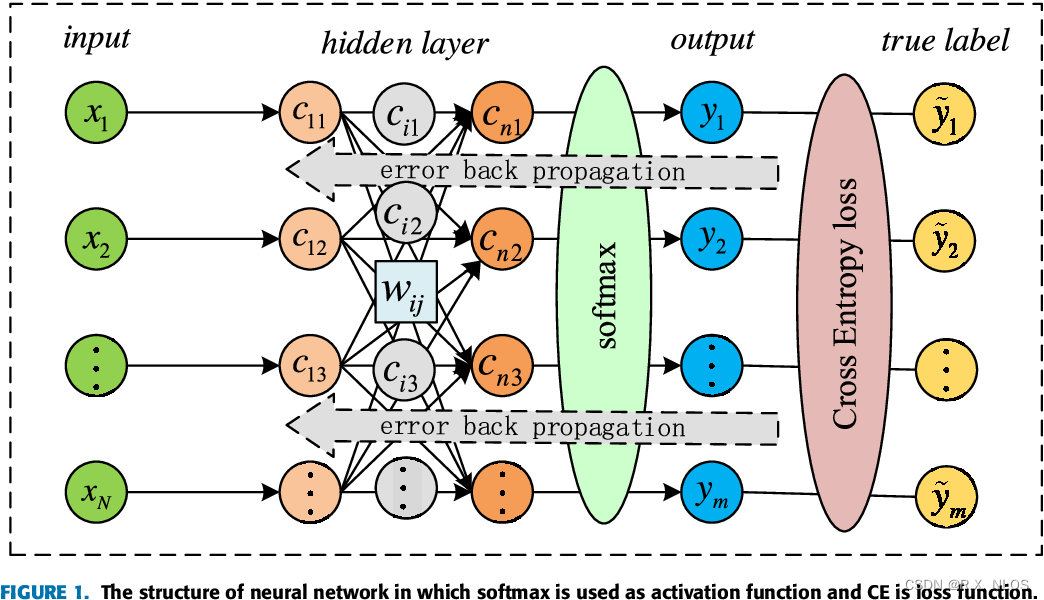
交叉熵损失 在各种分类问题中得到了广泛的应用,包括图像分类、文本分类和语音识别等。它与 Softmax 激活函数 结合使用,以计算交叉熵损失。
MPCE: A Maximum Probability Based Cross Entropy Loss Function for Neural Network Classification
随着深度学习的发展,交叉熵损失已被引入到许多先进的模型和架构中。例如,在 Transformer 和 BERT 等自然语言处理模型中,交叉熵损失被用来优化模型参数以获得更好的性能。
此外,研究人员还在探索 改进交叉熵损失 的方法,以提高模型的泛化能力和稳定性。这些改进方法包括:
- Label smoothing: 通过平滑真实标签的概率分布,以减轻过拟合现象。
- Focal loss: 通过调整损失函数的权重,使模型更关注难以分类的样本。
- Knowledge distillation: 利用教师模型的知识提高学生模型的性能。
4 挑战
尽管 交叉熵损失 在许多应用中取得了成功,但仍存在一些挑战:
- 类别不平衡问题: 当训练数据中的类别分布不均匀时,交叉熵损失可能导致模型对某些类别的预测效果较差。针对这一问题,可以使用加权交叉熵损失、过采样和欠采样等方法进行改进。
- 损失函数局部最小值: 在优化过程中,模型可能陷入局部最小值,导致训练过程停滞。为了解决这一问题,可以采用动量优化、学习率退火和其他先进的优化算法。
- 对抗样本攻击: 交叉熵损失对对抗样本攻击可能较为敏感,导致模型性能下降。为了增强模型的鲁棒性,可以使用对抗训练、特征融合和其他防御策略。
5 未来展望
未来,交叉熵损失 可能会在以下方面取得进一步发展:
- 损失函数设计: 探索新的损失函数形式,以应对更复杂和多样化的分类任务。
- 多任务学习: 研究交叉熵损失在多任务学习场景下的应用,以提高模型的泛化能力和效率。
- 融合先验知识: 将先验知识融入损失函数,以引导模型学习更符合实际需求的特征表示。
总之,交叉熵损失 在机器学习和深度学习领域具有广泛的应用前景。通过研究和改进交