一、背景概述
深度学习模型在图像分类、语义分割、对象检测等计算机视觉任务中的成功归功于利用了用于训练网络的大量标记数据——一种称为监督学习的方法。尽管在这个信息技术时代有大量的非结构化数据可用,但注释数据很难获得。
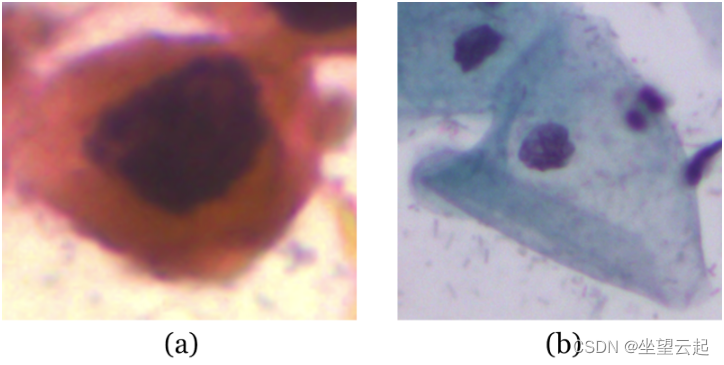
由于这个原因,计算机视觉机器学习项目中数据标记将占用大部分时间,并且也是一项人工代价昂贵的工作。此外,在医疗保健等领域,只有专家医生才能对数据进行分类 - 例如,看看以下两张宫颈细胞学图像,哪一个是癌变的?大多数未经训练的医疗专业人员不会知道答案,在这种情况下,数据标记更加困难。充其量,我们只有标注少数样本,但是这还不足以训练监督学习模型。
此外,随着时间的推移,会不断获得更新鲜的数据,例如当来自新发现的鸟类物种的数据。在大型数据集上训练深度神经网络会消耗大量计算能力(例如,ResNet-200 在 8 个 GPU 上进行训练需要大约三周时间)。因此,在大多数情况下,必须重新训练模型以适应新可用的数据是不可行的。
这就是“Few-Shot Learning”概念的用武之地。
二、什么是少镜头学习?
小样本学习 (FSL) 是一种机器学习框架,它使预训练模型能够对新类别的数据(预训练模型在训练期间未见过的数据)进行泛化,每个类仅使用几个标记样本。它属于元学习的范式(元学习意味着学习学习ÿ