Few-Shot and Many-Shot Fusion Learning in Mobile Visual Food Recognition
公众号:EDPJ
目录
2.2 使用两步知识蒸馏(knowledge distillation)的many-shot learning(softmax loss、KL loss)
2.4 Fusion Learning(融合学习)(Total Loss)
0. 摘要
近几年,移动端食品识别(Mobile visual food recognition)正在成为食物记录和饮食监测(food logging and dietary monitoring)领域重要的应用。现存的食物识别方法使用传统的多样本学习(many-shot learning)训练一个大的骨干网络(backbone network),这需要大量的训练数据。然而,某些食物类别样本是有限的,这导致传统的many-shot的训练方法不能使用。此外,现有的解决方案使用最新的大的完整网络(large full network)来提升食物识别的性能,而没有更多的关注减小网络的大小和计算量。因此,它们不适合在移动设备上使用。本文中,通过使用few-shot和many-shot融合学习(fusion learning)的方法,来解决移动端食物识别遇到的这些问题。本方法使用一个紧凑型(compact)网络,它可以从现有的数据集类别中学习,也可以从只有少量样本的新类别中学习。本文构建了一个新的数据集,用于评估本方法的性能。
0.1 关键词和名词解释
- few-shot(少样本):对于已经预训练(pre-train)好的model,只看过少量的labelled data(support set),就能完成task(query set)。
- N-way K-shot:few-shot learning的设置。Support set共有N个类别,每个类别有K个labelled data。
- many-shot:其实就是使用大量labelled data的supervised learning。
- Fusion(融合):这里说的融合是指把训练好的few-shot和many-shot的分类器参数合并,从而达到对两个数据集中的数据均可识别的效果。而不是之前在PersEmoN: 用于分析表象性格(Apparent Personality)、情绪(Emotion)及其关系的深度网络一文中提到的feature fusion。
- Knowledge distillation:这是网络压缩(network compression)的范畴,为的是满足于某些设备(如移动终端)低存储、低功耗的需求。具体操作:先训练一个大的网络(teacher network),再训练一个小的网络(student network),然后让它模仿大网络的输出。
- Softmax参数T(温度,Temperature):当一组数据中的某些值的数量级远大于其他值时,会导致其他值经softmax的输出都接近于0。而使用一个与这个大值的数量级相当的T,则可以解决这个问题,如公式(1)所示。至于获得soft label,那都是附加的收益。
1. 简介
现有的一些APP(例如:MyFitnessPal和Noom Coach)可以帮助用户保持健康的饮食。然而,它们需要用户手动的记录饮食,这是费时且无聊的。与手动输入数据不同,一些研究通过用智能手机的相机获取失误图像来记录数据。因此,通过图像识别,可以为用户提供更快的反馈。
近几年,大量的CNN架构被用于食物识别。
- Pouladzadeh提出了基于CNN特征提取的食物识别系统,它通过区域挖掘(region mining)识别图像中的多个食物。
- Hassannejad改进了谷歌的感知模块(inception module)来评估它在不同食物数据集上的性能。
- Aguilar开发了一个融合(fusion)分类器,它使用两个不同的CNN进行食物识别。
现存的食物识别系统使用大的完整网络(例如:VGGNet,ResNet,Inception)来获得令人满意的性能。然而,这些网络需要大量的训练数据。然而,对某些食物类别来说,可获得的数据是有限的。因此,这些类别不能用于上述网络的训练。此外,现存的网络需要高存储、大计算量和高能耗,因此不能用于移动端。
Few-shot learning,使用少量的训练数据训练model。基于少量labelled data就能完成图像的生成或者分类。它可以有效地解决样本不足的识别问题。近些年,一些研究者开始致力于研发新的few-shot learning的架构。.
- Sung提出了一个关系网络(relation network,RN),它通过一个embedding模块提取query和training images的特征,然后这个特征将会与每一个类别特征的均值进行对比。
- Gidaris提出了一个新的基于attention(attention-based)的few-shot learning,他重新设计了一个CNN的分类器。
2. Few-shot和many-shot融合的学习
2.1 数据集NTU-IndianFood107
作者构建了一个印度美食(Indian cuisine)数据集,包含两个要素:
- 一个基础的many-shot的数据集,该数据集是从搜索引擎上获取的。它包含83个食物类别,每个类别有大约600张图像。
- 一个食物日记(Food Diary)形式的few-shot数据集。食物日记从一个印度的食物点评网站上获取,其中的图像是用户在餐馆拍摄的照片。构建这样的数据集是为了模拟用户提供只包含少量图像的新类别的场景,有助于few-shot learning。
使用few-shot和many-shot融合的方法是为了既能用few-shot完成对新类别的识别,又能对many-shot数据的类别识别。
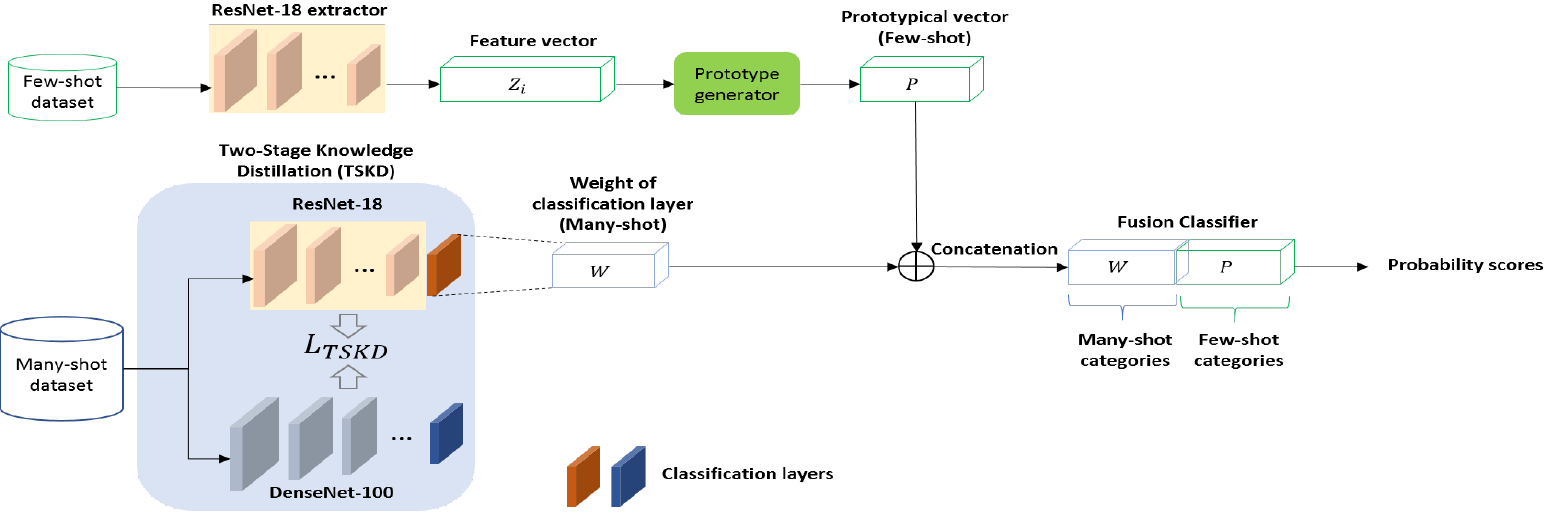
上图是本文使用的架构。它包括:
- 一个knowledge distilled ResNet-18模块,作为many-shot识别的model。在使用many-shot数据集训练之后,提取其中分类器的weight。
- 使用ResNet-18作为特征提取器的few-shot模块。基于少量的训练数据为每一个few-shot类别生成一个模范(prototypical)向量。
通过串联两个分类器的weight实现few-shot和many-shot的融合。
2.2 使用两步知识蒸馏(knowledge distillation)的many-shot learning(softmax loss、KL loss)
和完整的CNN相比,本文使用的紧凑型网络只有少量的层数和参数。Knowledge distillation的目的是从一个较大的教师网络(teacher network)迁移信息,从而提升紧凑网络
(实际上就是一个student network)的性能。首先,用一个古典的softmax loss训练
来获取高分类精度。对
训练,使其输出接近
的输出。Hinton提出更改softmax中的参数(温度,Temperature,T),从而从
中生成软目标标签(soft target labels),这些软目标标签用于训练
生成相似的输出。Softmax为每一个输入图像
生成概率分布
,表示如下:
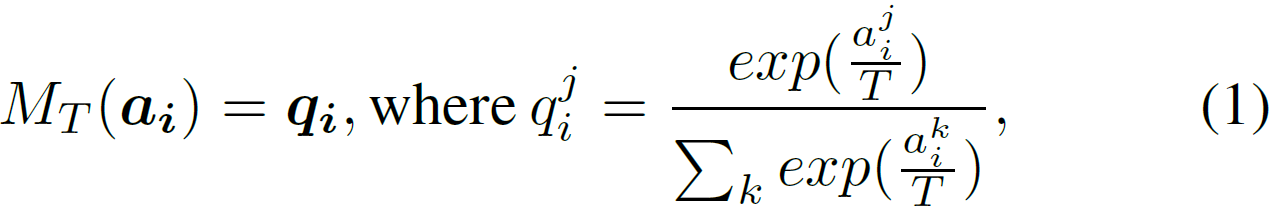
其中,T是温度。表示由
生成的图像 i 的预softmax(pre-softmax)概率(logits),它的维度是数据集中类别的数目。对于传统的softmax分类器,T=1。相似的,源于
的概率表示为
。通过增大T的值,可以获得
的软概率分布
。因此,给定图像标签
,
可以进行监督学习。Loss表示为:
的
与
的
的softmax loss和KL散度(Kullback Leibler divergence)loss的结合。KL散度loss定义为:
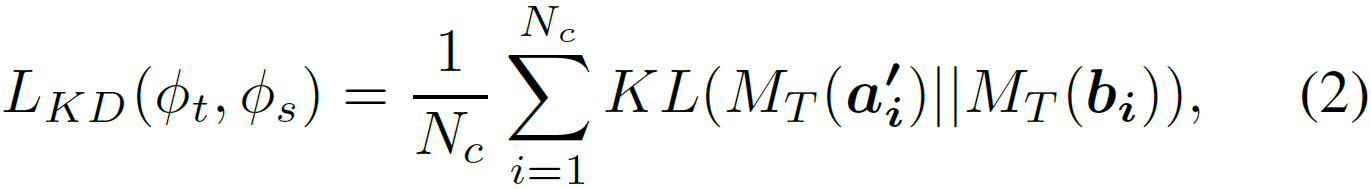
其中, 表示many-shot数据集中训练图像的总数目。使用交叉熵(cross-entropy)的softmax loss表示为:
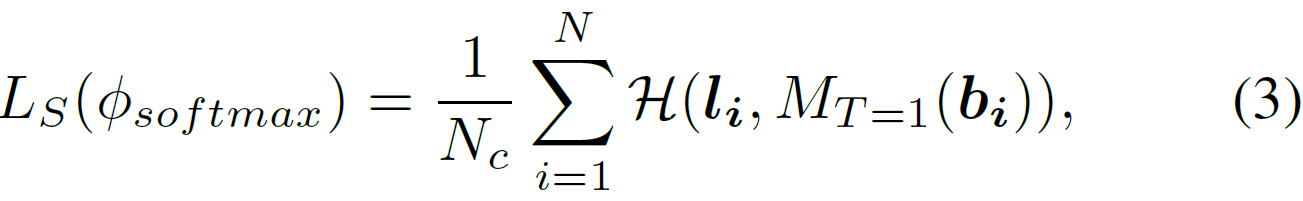
传统的knowledge distillation只使用来自于最后的全连接(FC)层的logits。为了捕获每个输入图像更好的结构细节,还从两个网络的中间层(conv4和dense block3)生成logits,这些中间层可以产生更大的特征图(feature maps)。把新的FC和ReLU层集成到两个网络中相应中层,中层logits可以表示为:的
和
的
。在训练过程中,中层logits和pre-softmax logits都参与了两步知识蒸馏(Two-Stage Knowledge Distillation,TSKD)loss:
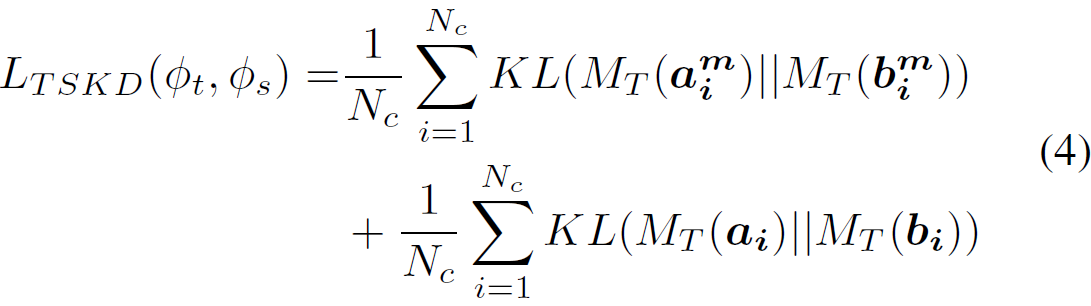
总loss function是softmax loss和TSKD loss的加权和:
![]()
在计算第k个类别的softmax之前,对于每一个many-shot训练图像,
会提取D维特征
,从而计算一个原始的分类分数(raw classification scores)。
![]()
其中,表示第k个类别的分类权重。完整的分类权重矩阵
的维度是
。W用等式(5)的loss function更新。
2.3 Few-shot learning
本研究使用的few-shot识别基于训练图像的特征向量为每一个few-shot类别创造一个原型形心(prototype centroid)。通过计算图像与每个类别原型向量的相似度获取图像的raw classification scores。然而,原型向量的数量级(magnitude)取决于输入图像的特征向量,many-shot和few-shot的classification scores的数量级也不同。因此,难以在many-shot和few-shot的框架间构建可靠统一的识别。Gidaris提出,通过归一化原型向量的数量级,使用cosine similarity而不是标准的点积(dot-product)来计算。

其中,表示L2归一化(L2 normalization)的向量。
是一个可学习的系数,调整cosine similarity的范围使其适合softmax函数。因此,few-shot learning的分类权重不再受图像特征的数量级影响。 此外,通过移除ReLU层,原型向量可以像分类权重向量一样取正值或者负值。
第k类别的每一个训练图像的特征向量表示为:。第k个类别的原型向量表示为:

然而,由于训练图像数量有限,这些基于输入图像特征向量平均的原型向量不能生成那个类别的精确表示(representation)。为了解决这个问题,使用了训练好的many-shot紧凑网络。基于每一个many-shot类别的分类权重更改第k个few-shot类别的原型向量。由于归一化后的
表示其类别的特征向量,因此
还包含视觉相似性。
这里我的理解是,由于归一化,即第k个类别的所有分类权重之和为1。根据公式(7),为了获取更大的raw classification scores,自然要把大的分类权重分配给大的特征向量分量,即特征向量与分类权重有相似的大小排布,所以可以用归一化后的
表示其类别的特征向量。
因此,通过找到一个最相似的many-shot分类权重向量,可以更新一个few-shot类别的原型向量。
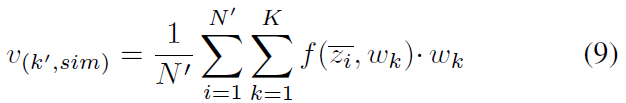
其中,表示cosine similarity。在其后是一个softmax概率分布,用于说明
与分类权重向量
的相似程度,其输出是最相似的分类权重加权和。最终,第k个few-shot类别的原型向量表示为:
![]()
其中,表示哈达玛积(Hamadard product,向量对应元素相乘,乘积放在该元素的位置)。
是维度为D的可训练的加权向量。其值在fusion learning中更新。
2.4 Fusion Learning(融合学习)(Total Loss)
表示全部
个few-shot类别的原型向量,它可与many-shot分类权重
串联。因此,用于统一食物识别的融合分类器的分类权重为:
。
在训练阶段,先在基础数据集上用TSKD训练many-shot模型。下一步,移除了最后的分类层,并且固定网络参数,作为few-shot learning的特征提取器。这一步在持续训练many-shot识别时,还更新。在每一个训练周期(episode),为训练网络,从基础数据集中随机选出N个训练图像,从食物日记的每个类别中随机选取
个训练图像。每一个few-shot类别的原型向量用选择的
个训练图像生成。总融合学习的总loss是交叉熵loss:
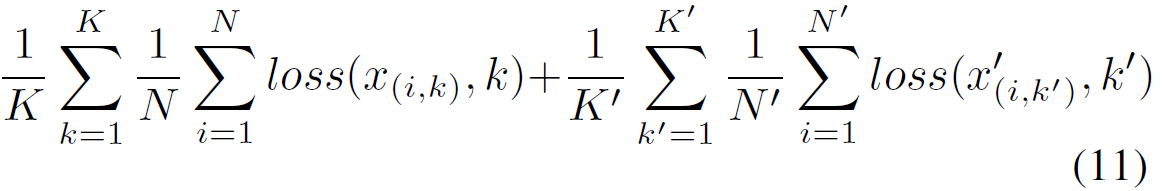
其中,分别表示many-shot和few-shot数据集中的类别数。
表示类别 k 中的图像 i。
训练完成后,基于对分类器精调(fine-tune)。在测试阶段,提取query image的特征向量,并计算其raw classification score。预测结果在最终的softmax之后获得。
3. 实验结果
3.1 Many-shot识别的评估

TOP-1和TOP-5表示现有的many-shot识别性能最好的第一和第五种模型。下面的数据是左边的这些model的性能和TOP相比的实现程度。实验结果表明,相比Dynamic few-shot一文中many-shot的数据,本研究有更好的性能。这是因为,使用TSKD提供了更好的泛化。
3.2 Few-shot识别的评估

实验结果表明,相比Dynamic few-shot一文中few-shot的数据,本研究有更好的性能。这是因为,本研究能够抽取few-shot image精确的特性向量,从而获得更好的分类性能。
3.3 融合识别的评估

实验结果表明,相比Dynamic few-shot一文中融合学习的数据,本研究有更好的性能。这证明了使用融合学习统一few-shot和many-shot训练过程的的有效性。
4. 参考
Zhao, H., Yap, K. H., Kot, A. C., Duan, L., & Cheung, N. M. (2019, May). Few-shot and many-shot fusion learning in mobile visual food recognition. In 2019 IEEE International Symposium on Circuits and Systems (ISCAS) (pp. 1-5). IEEE.
Gidaris, S., & Komodakis, N. (2018). Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4367-4375).
Wang, Y. X., Girshick, R., Hebert, M., & Hariharan, B. (2018). Low-shot learning from imaginary data. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7278-7286).