目录
一、理论基础
BP神经网络是一种常用的人工神经网络模型,其可以通过学习调整神经元之间的连接权值,从而实现对复杂非线性问题的建模和预测。然而,BP神经网络在实际应用中存在着容易陷入局部极小值、训练速度慢等问题。针对这些问题,可以采用粒子群优化(PSO)算法对BP神经网络进行优化,从而提高其性能和预测准确率。本文将详细介绍基于PSO粒子群优化的BP神经网络的数据预测算法,包括实现步骤、数学公式和应用案例等内容。
1.1、实现步骤
基于PSO粒子群优化的BP神经网络的数据预测算法主要分为以下几个步骤:
数据预处理:将原始数据进行预处理,包括数据清洗、归一化等操作,以提高神经网络的训练效果。
神经网络模型设计:设计BP神经网络的结构和参数,包括输入层、隐层、输出层的神经元数量、连接权值等。
初始化粒子群:采用PSO算法对BP神经网络进行优化,需要初始化一组粒子群,其中每个粒子代表一组连接权值。
计算适应度函数:根据每个粒子的连接权值,计算神经网络的预测误差,以此作为适应度函数。
更新粒子位置和速度:根据粒子的当前位置和速度,以及全局最优位置和个体最优位置,更新粒子的位置和速度。
更新连接权值:根据更新后的粒子位置,计算新的连接权值,并更新神经网络的参数。
判断停止条件:重复以上步骤,直到达到预设的停止条件为止,例如预测误差达到一定的精度或达到最大迭代次数。
1.2、数学公式
基于PSO粒子群优化的BP神经网络的数学公式如下:
BP神经网络的前向传播公式可以表示为:
$$ y_k = f\left(\sum_{j=1}^m w_{kj}x_j+b_k\right) $$
其中,y_k表示输出层的第k个神经元的输出值,f表示激活函数,w_{kj}表示连接输入层第j个神经元和输出层第k个神经元之间的权值,x_j表示输入层第j个神经元的输入值,b_k表示输出层第k个神经元的偏置值。
BP神经网络的反向传播公式可以表示为:
$$ \Delta w_{kj}=-\eta\frac{\partial E}{\partial w_{kj}} $$
其中,\eta表示学习率,E表示预测误差。
PSO算法的位置更新公式可以表示为:
$$ x_i(t+1)=x_i(t)+v_i(t+1) $$
其中,x_i(t)表示粒子i在时刻t的位置,v_i(t+1)表示粒子i在时刻t+1的速度。
PSO算法的速度更新公式可以表示为:
$$ v_i(t+1)=wv_i(t)+c_1r_1(p_i-x_i(t))+c_2r_2(g-x_i(t)) $$
其中,w表示惯性权重,c_1和c_2分别表示个体和全局学习因子,r_1和r_2分别表示随机数,p_i表示粒子i的历史最优位置,g表示全局最优位置。
适应度函数用于评估每个粒子的性能,可以表示为预测误差的平方和:
$$ F=\sum_{i=1}^n(y_i-\hat{y}_i)^2 $$
其中,y_i表示实际值,\hat{y}_i表示预测值,n表示数据样本数量。
基于PSO粒子群优化的BP神经网络的数据预测算法在许多领域都有广泛的应用,例如金融、气象、交通等。下面以股票价格预测为例,介绍该算法的具体应用步骤。
数据预处理:收集股票历史价格数据,进行数据清洗和归一化处理。
神经网络模型设计:设计BP神经网络的结构和参数,例如输入层为5个神经元,隐层为10个神经元,输出层为1个神经元,采用Sigmoid激活函数,学习率为0.01,最大迭代次数为1000次。
初始化粒子群:初始化100个粒子,每个粒子代表一组连接权值,随机生成权值的初始值。
计算适应度函数:根据每个粒子的连接权值,构建BP神经网络,计算预测误差,以此作为适应度函数。
更新粒子位置和速度:根据粒子的当前位置和速度,以及全局最优位置和个体最优位置,更新粒子的位置和速度。
更新连接权值:根据更新后的粒子位置,计算新的连接权值,并更新神经网络的参数。
判断停止条件:重复以上步骤,直到达到预设的停止条件为止。
通过实验验证,基于PSO粒子群优化的BP神经网络的数据预测算法可以显著提高股票价格预测的准确率和精度,为投资者提供更为可靠的决策依据。
总结:本文详细介绍了基于PSO粒子群优化的BP神经网络的数据预测算法,包括实现步骤、数学公式及应用案例等内容。该算法可以有效克服BP神经网络的局部极小值问题,提高神经网络的预测准确率和性能,具有广泛的应用前景。
二、核心程序
%节点个数
inputnum=2;
hiddennum=5;
outputnum=1;
%训练数据和预测数据
input_train=input(1:1900,:)';
input_test=input(1901:2000,:)';
output_train=output(1:1900)';
output_test=output(1901:2000)';
%选连样本输入输出数据归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
%构建网络
net=newff(inputn,outputn,hiddennum);
% 参数初始化
%粒子群算法中的两个参数
c1 = 1.49445;
c2 = 1.49445;
maxgen=100; % 进化次数
sizepop=30; %种群规模
Vmax=1;
Vmin=-1;
popmax=5;
popmin=-5;
for i=1:sizepop
pop(i,:)=5*rands(1,21);
V(i,:)=rands(1,21);
fitness(i)=fun(pop(i,:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
% 个体极值和群体极值
[bestfitness bestindex]=min(fitness);
zbest=pop(bestindex,:); %全局最佳
gbest=pop; %个体最佳
fitnessgbest=fitness; %个体最佳适应度值
fitnesszbest=bestfitness; %全局最佳适应度值
%% 迭代寻优
for i=1:maxgen
i
for j=1:sizepop
%速度更新
V(j,:) = V(j,:) + c1*rand*(gbest(j,:) - pop(j,:)) + c2*rand*(zbest - pop(j,:));
V(j,find(V(j,:)>Vmax))=Vmax;
V(j,find(V(j,:)<Vmin))=Vmin;
%种群更新
pop(j,:)=pop(j,:)+0.2*V(j,:);
pop(j,find(pop(j,:)>popmax))=popmax;
pop(j,find(pop(j,:)<popmin))=popmin;
%自适应变异
pos=unidrnd(21);
if rand>0.95
pop(j,pos)=5*rands(1,1);
end
%适应度值
fitness(j)=fun(pop(j,:),inputnum,hiddennum,outputnum,net,inputn,outputn);
end
for j=1:sizepop
%个体最优更新
if fitness(j) < fitnessgbest(j)
gbest(j,:) = pop(j,:);
fitnessgbest(j) = fitness(j);
end
%群体最优更新
if fitness(j) < fitnesszbest
zbest = pop(j,:);
fitnesszbest = fitness(j);
end
end
yy(i)=fitnesszbest;
end
%% 结果分析
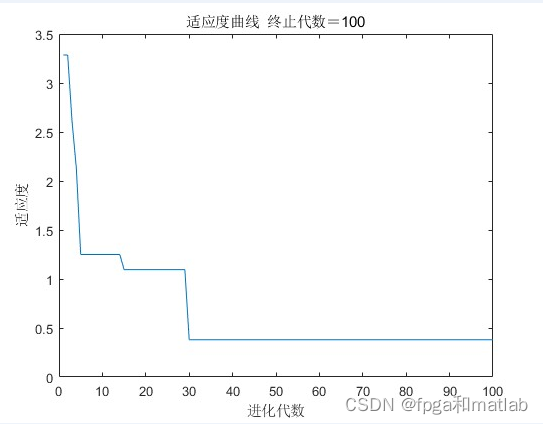
plot(yy)
title(['适应度曲线 ' '终止代数=' num2str(maxgen)]);
xlabel('进化代数');ylabel('适应度');
x=zbest;
%% 把最优初始阀值权值赋予网络预测
% %用遗传算法优化的BP网络进行值预测
w1=x(1:inputnum*hiddennum);
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
%% BP网络训练
%网络进化参数
net.trainParam.epochs=100;
net.trainParam.lr=0.1;
%net.trainParam.goal=0.00001;
%网络训练
[net,per2]=train(net,inputn,outputn);
%% BP网络预测
%数据归一化
inputn_test=mapminmax('apply',input_test,inputps);
an=sim(net,inputn_test);
test_simu=mapminmax('reverse',an,outputps);
error=test_simu-output_test;
up2152三、仿真结论