Web自动化常见的定位方式
为什么要学习定位
1.让程序操作指定元素,就必须先找到此元素
2.程序不像人类用眼睛直接定位到元素
-
webDriver提供了八种定位元素的方式
定位方式总结
1.id、name、class_name、tag_name:根据元素的标签或元素的属性来进行定位
2.link_text、partial_link_text:根据超链接的文本来进行定位(a标签)
3.xpath:为元素路径定位--重点4.cSs: 为css选择器定位(样式定位)

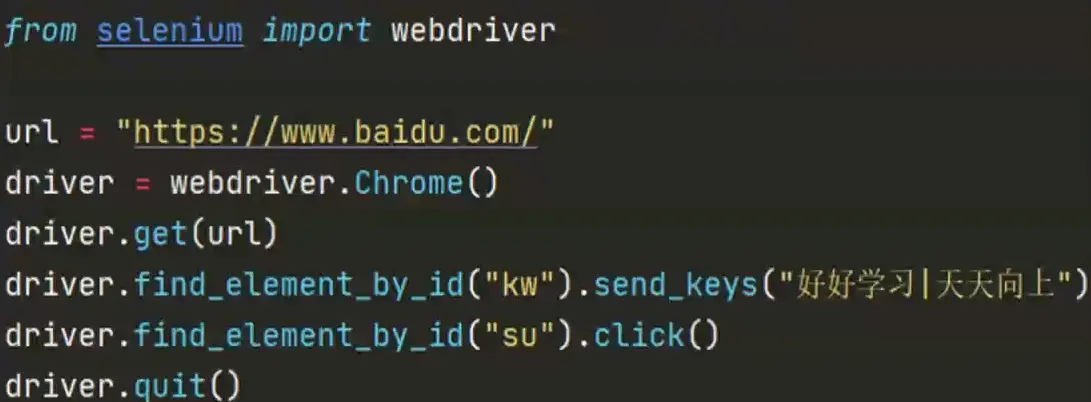
ID定位
说明:HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素;
前提:元素有id属性
id定位方法: find_element_by_id0
需求:打开百度界面(https://www.baidu.com/),通过id定位,输入信息,点击百度的钮
tag _name标签定位
注:由于HTML源码中,经常会出现很多相同的的标签名,所以一般不使用该定位方式
tag _name是通过标签名称来定位的,如a标签

link text定位
说明:link_text定位于前面4个定位有所不同,它专门用来定位超链接文本(<a>文本值</a>)
前提:定位的元素是链接标签(a标签)
link_text定位方法: find_element_by_link_text()
打开百度首页,通过link_text(链接文本)定位到【新闻】按钮,并进行点击操作
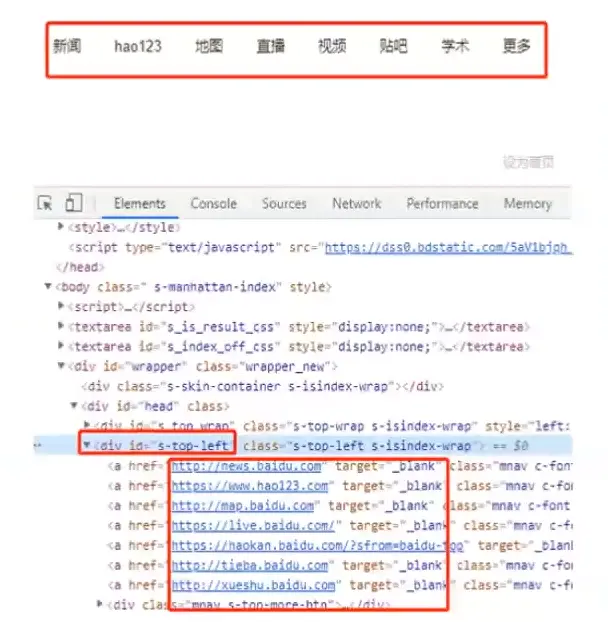
元素组定位
元素组定位方式: find_elements_by_xxx
作用:
1.查找返还定位所有符合条件的元素
⒉.返还的定位元素格式为列表格式
说明:
列表数据格式的读取需要指定下标(下标从0开始)
案例要求:打开百度页面
https://www.baidu.com/,通过元素组定位>定位: "//*[@id='s-top-left']/a"
xpath定位
xpath概述:--位置定位(路径方式)
1.xpath即为xml path的简称,它是一种用来确定XML文档中某部分位置的语言。
2.HTML可以看做是XML的一种实现,所以selenium用户可以使用这种强大的语言在web应用中来定位元素3.xpath为强大的语言,是因为它有非常灵活的定位策略。
定位方法: find_element_by_xpath()
xpath定位策略(方式)
1.路径定位--绝对路径、相对路径
⒉利用元素属性定位
3.层级与属性结合定位
4.属性与逻辑定位结合
路径定位
绝对路径:从最外层元素到指定元素之间所有经过元素层级路径;如/html/body/div/p[2]
提示:
1.相对路径以//开始
⒉.通过浏览器查看元素属性,右击复制xpath快速生成
xpath表达式描述及格式

xpath通过属性定位
xpath通过该元素已有的属性进行定位,如id, name等等

xpath通过text文本定位元素
当前元素没有id.name这些属性,如何定位?
打开商城界面(http:llshopxo.hctestedu.com/index.php?s=/indexluser/logininfo.html),通过
xpath定位邮
箱登录标签
定义元素:ll*[text()="邮箱验证码"]
xpath通过层级定位元素
要找到的元素没有属性,但是它的父级有;
url = "http:llshopxo.hctestedu.com/index.php?s=/index/userllogininfo.html"
示例:lI*[@class='login-top']/a
xpath逻辑运算
解决元素之间相同属性重名问题;
示例: 'll*[text()="注册" and @class="am-btn am-btn-secondary am-btn-xs am-radius"]'
http:/llshopxo.hctestedu.com/index.php?s=/index/userlogininfo.html