xpath 篇。
如果没有元素定位,ui 自动化测试将寸步难行。如果元素定位不精准,自动化测试就很难稳定运行。也许你经常听前辈们讲解如何提高自动化程序运行的稳定性,我得说,一个精准的元素定位表达式,是一切自动化测试程序正常执行的基础。
什么是元素定位呢?无论自动化程序想要操作网页的任何按钮、链接或者输入框,都必须先找到要操作的网页元素,这个过程就是元素定位。
现如今,我们会运用机器学习等智能化手段提高元素定位的精准性,但不是每个公司和测试员有精力研究机器学习。实际上,你只需要编写一个良好的 xpath 表达式,就能做到精准控制想要操作的网页元素。
如何在浏览器中定位元素
定位元素的方式有很多,有基于网页 DOM 的元素定位方式,有基于图像识别的元素定位方式,甚至有基于坐标的定位方式。通常会使用 DOM 解析的方式来获取元素。
首先,打开浏览器,在任意网页中按快捷键 F12 打开开发者工具,在 element 标签中能看到网页的源代码。任何网页元素,不管是连接,按钮还是输入框,都由一个个 HTML 标签组成。 标签包含了标签名、属性、文本、嵌套子标签等组成部分。
定位元素时,就是根据这些组成部分的特征来查找元素。比如想定位一个输入框:
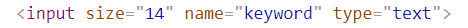
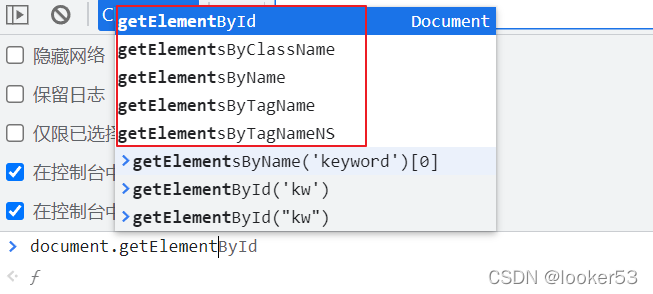
那么可以作为定位依据的特征有标签名 input、size 属性、name 属性、type 属性等等。 在浏览器的控制台中,可以输入document.getElementsByName指令获取到这个元素。

获取方式可以通过 name 属性、id 属性,class 属性等等。
本篇所有示例都使用同一个网址,你可以直接打开进行练习。 网址:https://petstore.octoperf.com
为什么要用 xpath
上面这些方式都是通过单个属性定位定位元素,一旦元素中没有这些属性,方法就失效了。还有就是在一个网页中,使用同一个属性值可能找出来多个元素,不够精准。
xpath 和 css 选择器都能提供更精准的元素定位服务。他们可以组合多个属性和特征,进一步筛选元素的范围,直到找到唯一的那个元素。
在浏览器中如何编写 xpath
在浏览器中调试xpath。
第一种方式是在开发者工具中按 ctrl + f,输入 xpath 表达式后可以通过上下箭头查看效果。
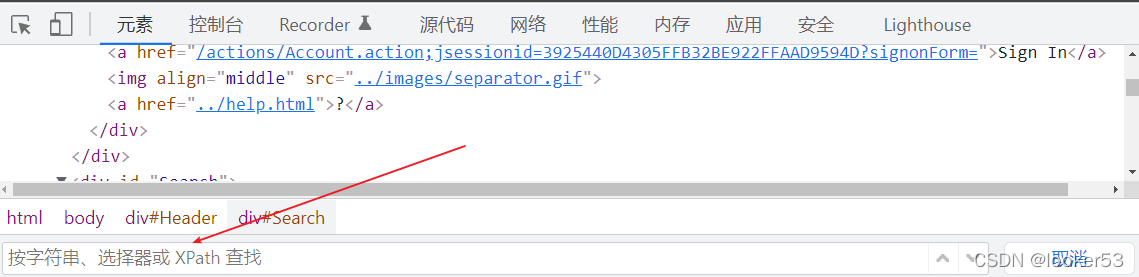
第二种方式在控制台中输入 $x("//div") ,更推荐使用,谷歌浏览器和火狐浏览器都可以。 输入 xpath 表达式后,在控制台中直接显示定位到的元素。在接下来的所有的语法讲解中,都可以通过打开浏览器练习。

核心用法
接下来是使用 xpath 必须掌握的核心知识点,只要掌握好这些知识点,基本上能定义到想要的元素。
//input[@name='accout']
- // 开头表示相对路径, 也可以用 / 开头表示绝对路径,一般用相对路径。
- [] 内表示属性条件
- [@name=‘accout’] 表示获取name属性等于accout 的元素
属性选择器
网页元素的任何属性都可以用来定位元素,常见的 name 属性、id 属性、type 属性、class 属性等等。需要注意的是,如果需要用 text 文本定位,则使用 text() 表示。
//input[@type="submit"]
//a[text()="Sign In"]
组合多个属性
多个属性之间可以相互组合,从而更精准的定位到想要的元素。组合可以使用 and 连接,也可以直接在第一个 [] 后继续加第二个 []
//a[1 and contains(@href, "FISH")]
//a[1][contains(@href, "FISH")]
索引
当通过表达式取出来多个元素时,可以通过索引指定获取第几个。
//div[@id="QuickLinks"]/a[position()=1]
//div[@id="QuickLinks"]/a[position()>3]
//div[@id="QuickLinks"]/a[1]
//div[@id="QuickLinks"]/a[last()]
函数
某些属性的值很长,用等于符号会让表达式看起来很长,因此有时候我们可以使用 contains, starts-with 等函数来精简。
//a[contains(@href, 'FISH')]
通过祖先找后代
//div//input
//div/input
//div/*
通过后代找祖先
//a[.//img[@src="../images/sm_fish.gif"]]
//a[img[@src="../images/sm_fish.gif"]]
//img[@src="../images/sm_fish.gif"]/../..
轴
基本上以上的操作就可以满足95%的使用场景了,还有就是同级元素的查找,尤其是像表格、菜单选项这样的元素经常会用到同级元素。 此时可以使用轴,会更加方便一些。 经常用到的轴有 follow-sibling 和 preceding-sibing。
//div[@id="QuickLinks"]/a[1]/following-sibling::a[1]
直接获取文本
xpath 也支持直接在表达式内获取 text 文本。
//div[@id="MenuContent"]/a[2]/text()'

获取元素的属性
xpath 也支持直接在表达式内获取属性。
$x('//a[text()="Sign In"]/@href')
福利
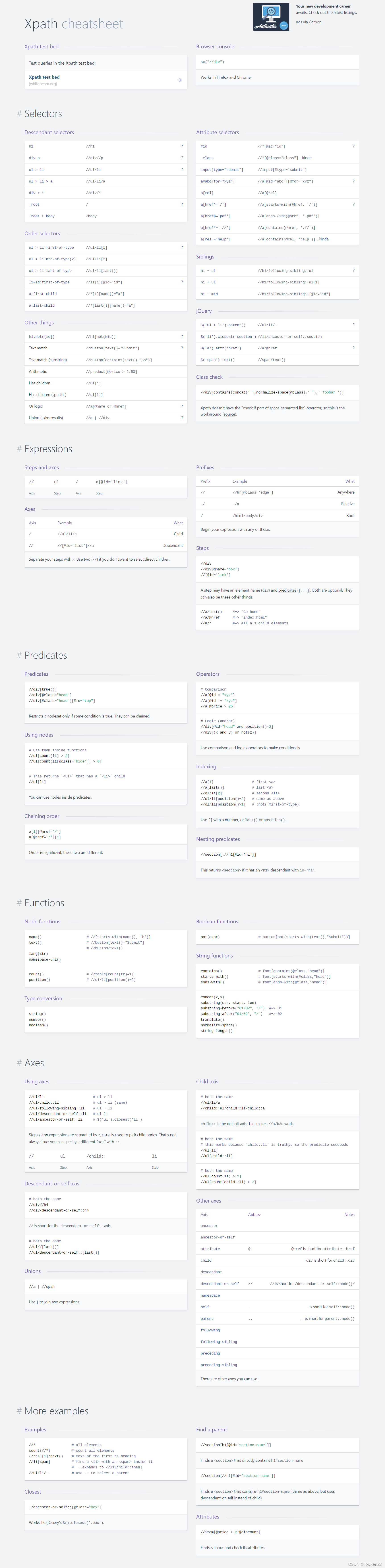
最后,送一张 xpath 常见用法的高清大图,下载保存好,遇到不会的用法直接查一查,非常方便。对本文有任何问题和建议,欢迎私信一起交流。
- 你已经阅读完本文所有内容。
- 相信你一定是个耐心和踏实的人,也是一个可交的朋友。
- 如果你有兴趣,可以复制 『
jiubing1』或者点击下方名片加我为好友,一起学习和进步。
参考
- https://en.wikipedia.org/wiki/XPath
- https://developer.mozilla.org/en-US/docs/Web/XPath
- https://devhints.io/xpath