什么是Xpath:
Path就是路径,xpath也类似,就像 在DOS中 D:\Auto\jack。
Xpath的使用:
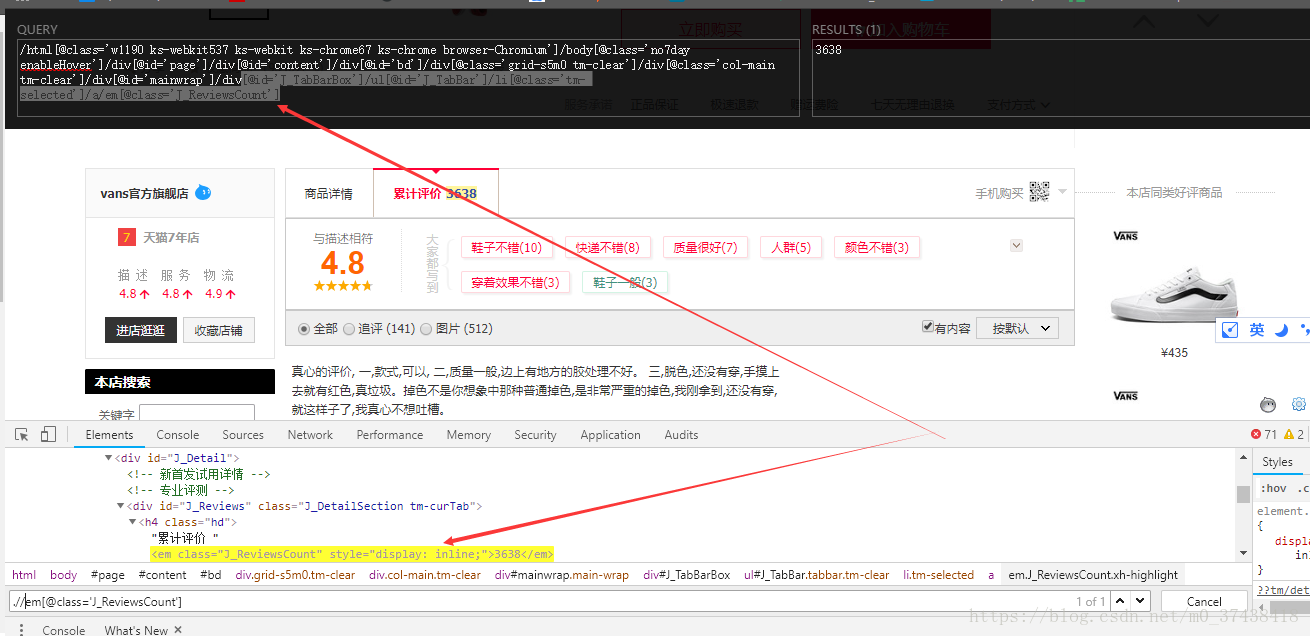
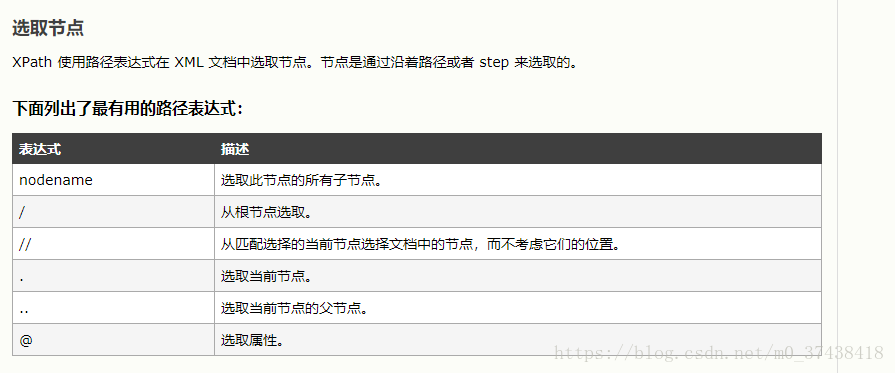




XPath轴(XPath Axes)可定义某个相对于当前节点的节点集:
1、child 选取当前节点的所有子元素
2、parent 选取当前节点的父节点
3、descendant 选取当前节点的所有后代元素(子、孙等)
4、ancestor 选取当前节点的所有先辈(父、祖父等)
5、descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
7、preceding-sibling 选取当前节点之前的所有同级节点
8、following-sibling 选取当前节点之后的所有同级节点
9、preceding 选取文档中当前节点的开始标签之前的所有节点
10、following 选取文档中当前节点的结束标签之后的所有节点
11、self 选取当前节点
12、attribute 选取当前节点的所有属性
13、namespace 选取当前节点的所有命名空间节点

Xpath的使用方法:
例子 1:html/body/div[1]/div[2] (如果不熟悉html的朋友们,需要自行百度html。)
该xpath 表示 : 在 html标签下 -> body标签下 -> 第一个div标签下 -> 第二个div标签
很好理解,继续
例子 2:.//*[@id='content']/div[2]/ul
这样会有人不理解了 .//*[@id='content'] 到底是什么意思呢?
. 代表当前路径
a//b 表示:在a标签下的子孙辈b标签
* 可以是任何标签
[@id='content'] 表示是 id 为 content
所以:这个例子的意思是: id 为 content 的任何子标签下面 -> 第二个 div标签下 -> ul 标签
Xpath基础学习完毕,接下来开始进阶学习
//p[text()='a'] :文本为 a 的p标签
//p[text()='a'] : 文本包含 a 的p标签
//a[@class='a'] :class 为 a的 p标签 (当然咯。既然可以为 @class 就一定能用 @id ,为什么不联想下 @src 和@href呢?)
//p[not(@class='a')] :class 不为 a的 p标签
好了,进阶完毕,如果要使用更高阶的Xpath要先属性以上内容,然后联合 Selenium使用
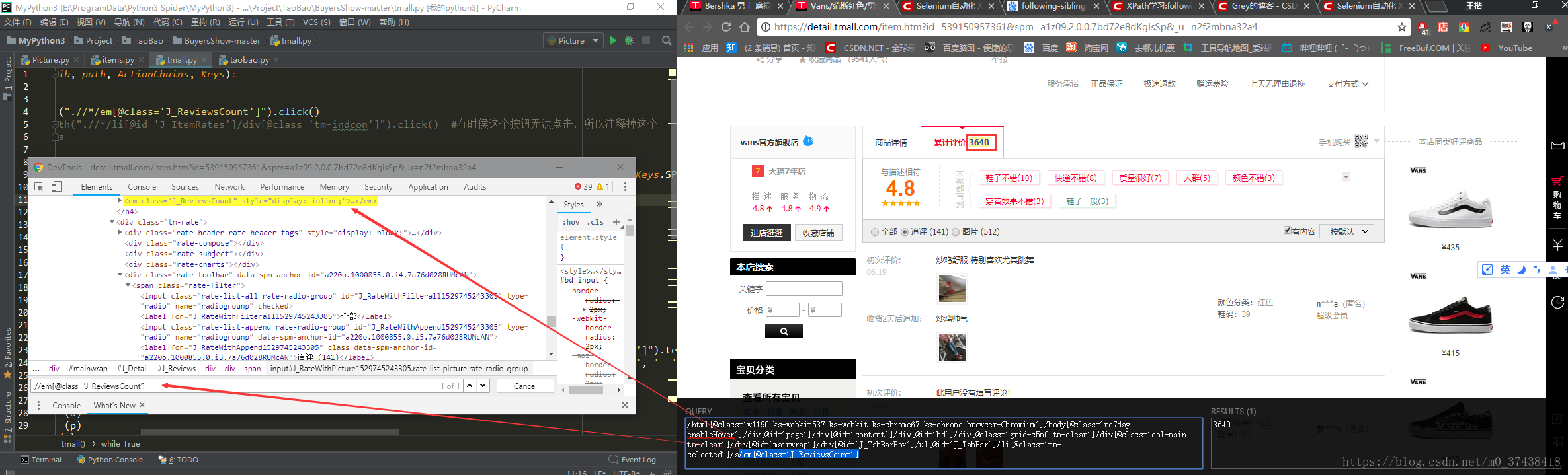
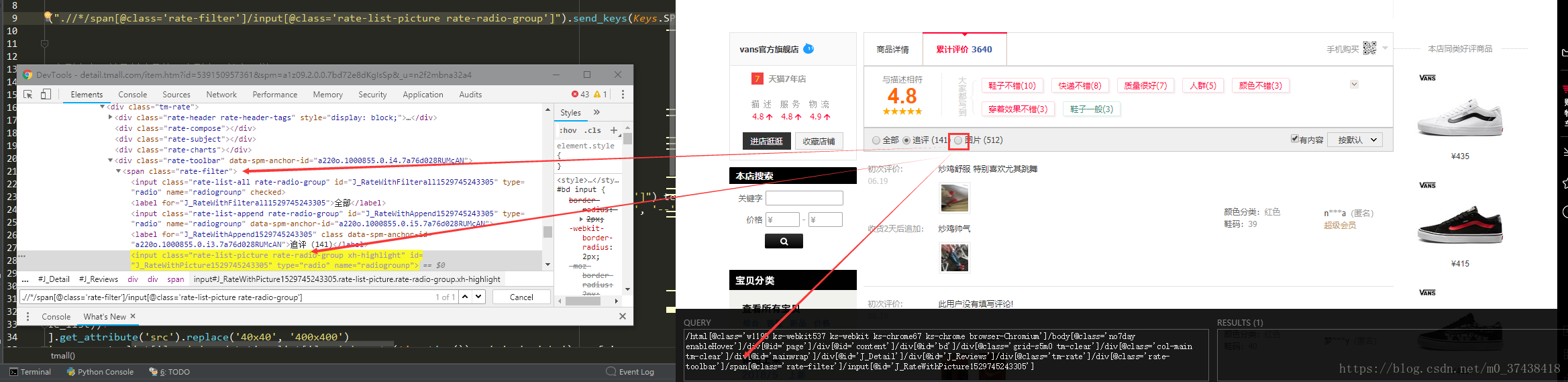
Xpath和其他定位方式的比较:(主要是和CSS定位的对比)
Xpath的最大好处是能向上查找,不过缺点是速度过慢。
参考: https://www.cnblogs.com/zhongmeizhi/p/6296213.html