回归是解决连续数据的预测问题,而分类是为了解决离散数据的预测问题。线性回归是机器学习算法中最简单的算法之一,它是监督学习的一种算法,主要思想是在给定训练集上学习得到一个线性函数,在损失函数的约束下,求解相关系数,最终在测试集上测试模型的回归效果。线性模型的形式如下:
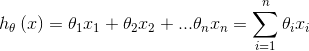
写成向量形式就是
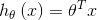
其中x可以看成特征,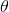
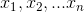
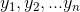
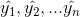
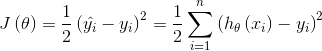
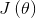
在机器学习中我们采用梯度下降算法求解该方程,将向量表达形式转为矩阵表达形式,则有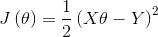
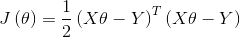
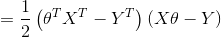
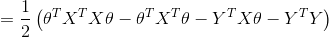
接下来对
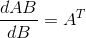
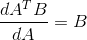
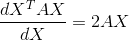
对于(*)式可以假设X为一行一列,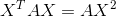
所以有
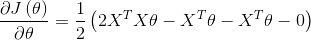
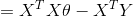
令
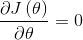
则有
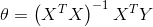
这是在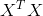
可以根据公式直接求得
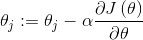






#求逆
from numpy.linalg import inv
#点乘
from numpy import dot
#创建矩阵,与np.array维度不同
from numpy import mat
#y=θx
X=mat([1,2,3]).T
print('X:\n',X)
Y=mat([2,4,6]).reshape(3,1)
print('Y:\n',Y)
#θ=(x'x)^-1 x'y
θ=dot(dot(inv(dot(X.T,X)),X.T),Y)
print('θ:\n',θ)
用python实现梯度下降:


import numpy as np
#求逆
from numpy.linalg import inv
#点乘
from numpy import dot
#创建矩阵,与np.array维度不同
from numpy import mat
#y=θx
#reshape之后向量都变成了矩阵
x=np.array([1,2,3]).reshape(3,1)
y=np.array([2,4,6]).reshape(3,1)
theta=np.array([1.0]).reshape(1,1)
alpha=0.1
for i in range(100):
theta=theta+alpha*np.sum((y-dot(x,theta))*x)/3.0
#theta = theta + alpha * dot(x.T, (y - dot(x,theta))) / 3.0
print(x.T)
print(dot(x, theta))
print(theta)
import pandas as pd
import numpy as np
from numpy.linalg import inv
from numpy import dot
from numpy import mat
data=pd.read_csv('E:\python语言\Python算法练习\Advertising.csv')
print(data)
#从data中读取X1 X2 X3
x=data.iloc[:,1:4]
#偏移,截距项X0
x['X0']=1
#将X排列成X0 X1 X2 X3
X=x.iloc[:,[3,0,1,2]]
print(X)
Y=data.iloc[:,4].values.reshape(10,1)
print(Y)
#利用最小二乘法求theta
theta=dot(dot(inv(dot(X.T,X)),X.T),Y)
print(theta.reshape(4,1))
#利用梯度下降算法求theta
#初始化theta
theta=np.array([1.0,1.0,1.0,1.0]).reshape(4,1)
print(theta.shape)
alpha=0.1
X0=X.iloc[:,0].values.reshape(len(Y),1)
X1=X.iloc[:,1].values.reshape(len(Y),1)
X2=X.iloc[:,2].values.reshape(len(Y),1)
X3=X.iloc[:,3].values.reshape(len(Y),1)
temp=theta
#方式一
for i in range(100):
temp[0]=theta[0]+alpha*dot(X0.T,(Y-dot(X,theta)))/10.0
temp[1] = theta[1] + alpha * dot(X1.T, (Y - dot(X, theta)))/10.0
temp[2] = theta[2] + alpha * dot(X2.T, (Y - dot(X, theta)))/10.0
temp[3] = theta[3] + alpha * dot(X3.T, (Y - dot(X, theta)))/10.0
theta=temp
print(theta)
#方式二
for j in range(100):
temp[0]=temp[0]+alpha*np.sum((Y-dot(X,theta))*X0)/10.0
temp[1] = temp[1] + alpha * np.sum((Y - dot(X, theta)) * X1) / 10.0
temp[2] = temp[2] + alpha * np.sum((Y - dot(X, theta)) * X2) / 10.0
temp[3] = temp[3] + alpha * np.sum((Y - dot(X, theta)) * X3) / 10.0
print(theta)


import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time
def J(X, y, theta):
'''
计算代价函数
'''
inner = np.power((np.dot(X,theta) - y), 2)
return np.sum(inner)/(2*len(y))
def gridientDescent(X, y, theta, alpha, iters):
'''
向量化批量梯度下降
'''
m = len(y)
cost = []
for i in range(iters):
print('iteration {}'.format(i))
#梯度下降
theta = theta -alpha * np.dot(X.T,np.dot(X,theta) - y)/m
#每更新一次,记录一次代价函数的值
cost.append(J(X, y, theta))
#画图,横坐标迭代轮数,纵坐标代价函数的值
plt.plot(range(iters), cost)
plt.show()
return theta, cost[-1]
# start data preparation
# 用pandas库读取csv
data = pd.read_csv('ex1data1.txt', header=None, names=['Population', 'Profit'])
#绘图查看数据分布
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12,8))
plt.show()
# 插入一列x insert(self, loc, column, value, allow_duplicates=False):
data.insert(0, 'Ones', 1)
#初始化变量
cols = data.shape[1] # 列数目
X = data.iloc[:, 0:cols-1] # 两个参数分别为行索引,列索引。所有行,列减掉最后一列
y = data.iloc[:,-1: ] # 所有行,最后一列
#将变量转化为数组,并初始化theta
X = np.array(X)
y = np.array(y)
theta = np.matrix(np.array([[0], [0]]), dtype='float64')
# 查看一下它们的维度
print(X.shape, y.shape, theta.shape)
# end data preparation
# start training
#学习率
alpha = 0.01
#迭代轮数
iters = 10000
theta, cost = gridientDescent(X, y, theta, alpha, iters)
print(theta, cost)
# end training
# start plot
#取100个点作为横坐标
x = np.linspace(data.Population.min(), data.Population.max(), 100)
#计算这100个点的纵坐标
f = theta[0, :] + theta[1, :] * x
f=f.reshape(100,1)
#画散点图
plt.scatter(data.Population, data.Profit, s=5)
#划线
plt.plot(x, f, color='red')
plt.show()
# end plot


