lenet网络作为深度学习卷积网络的开山之作,在学习卷积神经网络的时候首先了解lenet的网络对于今后的学习是有很必要的。话不多说,下面就让我们开始吧。
Lenet网络架构
虽说网上解析的lenet网络的架构的文章很多,但是只有看过了原论文之后才知道网上的解析与论文中实际的网络架构是有很大的差距的。下面就我看的原论文进行一次解析吧。
blog.csdnimg.cn/6fcaa40d32b94dbc8a127571cae219b2.png)
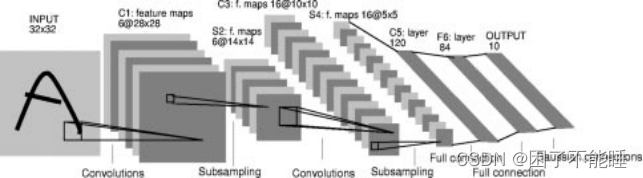
首先要看的就是论文中的lenet网络架构的原图,下面我就介绍一下该网络的详细架构:
这个网络共有七层,在下文中,卷积层被标记为Cx,子采样层标记为Sx,全连接层被标记为Fx,其中x是层索引
数据集
该网络的数据集使用的是mnist数据集,原始的图像大小为2828,在输入之前进行了padding,所以输入到网络之中的图像大小为3232。这样做的原因是希望图像中的数字的边缘信息能够出现在特征图的中央位置。换句话说就是防止边缘信息的丢失。然后就是对输入图像的像素值进行的归一化,论文中它使背景像素值为-0.1,数字的像素值为1.175。这样使输入图像的均值和方差大概分别为0和1。这里想要和大家说的是一个模型性能的好坏不仅仅取决于好的网络模型架构,还要多注意对数据的预处理。
C1层
| 卷积核大小 | 5*5 |
| 步长 | 1 |
| 卷积核个数 | 6 |
| 输出特征图大小 | 28*28 |
在卷积之后是要加上一个可训练的偏置,一般情况在卷积之后都会紧接着跟着激活函数但是在原论文中却没有提及。
S2层
这一层是子采样层,使用的是一个22的卷积核,但是这个卷积核是没有权重参数的,它只是让输入卷积核的四个参数进行相加,然后乘上一个可训练的参数,再加上一个可训练的偏置。然后通过Sigmoid激活函数。输出后的特征图大小为1414,输出通道为6。
可能有很多的文章直接说这是最大或平均池化层,但是这里确实并不是我们现在常说的最大或平均池化层,但是该层的思想和效果应该是和最大或平均池化层相似的。其他的文章在介绍的时候可能会说这里是最大池化层,但根据我对论文的理解这里应该是平均池化层更为合适。
C3层
| 卷积核大小 | 5*5 |
| 步长 | 1 |
| 卷积核个数 | 16 |
| 输出特征图大小 | 10*10 |
| 但是该层的卷积方式与平常的卷积方式不同,它采用的方式是部分连接 |
连接方式如图:
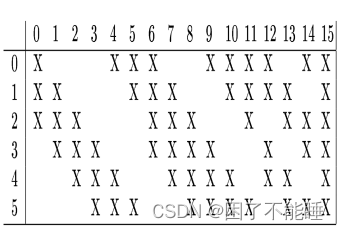
垂直方向的数字代表的是C3层输入的特征图索引,水平方向数字代表的是C3层卷积核的索引。X代表的是每一个卷积核要卷积的特征图。
Lenet这样做的论文中给出了两个解释:首先,卷积核与特征图的非完全连接将连接数保持在合理的范围内(这听起来和分组卷积很类似,本人觉得分组卷积应该是受了lenet的启发,没有看过分组卷积的相关论文以上只是自己的猜测)。更重要的是,它迫使网络中的对称性被打破。因为卷积核得到了不同的特征图,这样就使不同的特征图被迫提取不同的特征。
想来lenet这样的做法应该没有太大的作用,因为如今的网络很少看到这种模式的出现。
S4层
与S2层相同,S4使用的是一个22的卷积核,同样没有权重参数的,让输入卷积核的四个参数进行相加,然后乘上一个可训练的参数,再加上一个可训练的偏置。输出后的特征图大小为55,输出通道为6
在原论文中这一层没有提到激活函数,大概率可能是不需要激活函数吧,但本人认为这里还是加上Sigmoid激活函数比较好。
C5层
| 卷积核大小 | 5*5 |
| 步长 | 1 |
| 卷积核个数 | 120 |
| 输出特征图大小 | 1*1 |
| 很是巧合特征图变为了1*1,这就相当于是将特征图进行了展平操作,但又不象直接的将二维展为一维那般粗暴,这个过程保留了图像中的空间信息。自然的由卷积向全连接进行了过渡。 |
F6层
该全连接层由84个神经元组成,然后通过tanh激活函数。该激活函数如下:
F(a)=Atanh(Sa)
其中a是输入的特征图,A是1.7159,将输出的范围扩大。S论文中说的是一种斜率,但是本人不明白这种斜率代表的含义,如果有知道的小伙伴可以在评论区解释一下吗?
输出层
最后为输出层由10个神经元组成。但是这里的神经元之间的参数都是经过人工设计的1或-1,但随着模型的训练是可以改变的。并且这一层的计算公式为:
y i y_i yi = ∑ 1 j ( x j − w i j ) 2 \sum_1^j(x_j - w_{ij})^2 ∑1j(xj−wij)2
可以看出采用的是均方误差
损失函数
E ( W ) E(W) E(W) = 1/P ∑ 1 P y D p ( Z p , W ) \sum_1^Py_{D_p}(Z^p,W) ∑1PyDp(Zp,W)
这里的 y D p y_{D_p} yDp是输出层的第 D p {D_p} Dp个神经元对应的分类类别, ( Z p , W ) (Z^p,W) (Zp,W)是输出层的输出
上面的损失函数公式不是完整的损失函数公式,完整的损失函数公式后面还添加一种惩罚项,本人没有理解它给的惩罚项公式,这里就不展示了。
上面的输出层给的比较麻烦,大家在实现该网络的时候可以将输出层该为我们熟知的全连接的方式,然后将损失函数改为均方误差就可以了。
代码实现
下面是使用pytorch实现的lenet,其中尽量还原了论文中提及的网络结构,其中包含了迭代次数,学习率的更改等。
但是模型效果却不太好,仅供参考。具体实现的时候可以加入常用的技术,提高模型的性能。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
from torchvision import transforms
import numpy as np
import cv2
import os
import matplotlib.pyplot as plt
#读取数据
class mydata(data.Dataset):
def __init__(self,path):
self.path = path
self.image_root = os.listdir(path)
def __getitem__(self, index):
image = cv2.imread(os.path.join(self.path,self.image_root[index]))
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
num = self.image_root[index].split('_')[0]
label = torch.zeros(10,dtype= torch.float32)
label[int(num)] = 1.0
image = transforms.ToTensor()(image)#将数据转化为tensor格式,并且进行了归一化
image = transforms.Normalize((0.1307,),(0.3081,))(image)#将数据进行标准化
return image,label
def __len__(self):
return len(self.image_root)
#模型的构建
class Lenet_5(nn.Module):
def __init__(self):
super(Lenet_5, self).__init__()
self.c1 = nn.Sequential(nn.Conv2d(1,6,5,padding=2),nn.Sigmoid())
self.s2 = nn.Sequential(
nn.AvgPool2d(2),
nn.Sigmoid()
)
self.c3_1 = [nn.Conv2d(3,1,5),nn.Conv2d(3,1,5),nn.Conv2d(3,1,5),
nn.Conv2d(3,1,5),nn.Conv2d(3,1,5),nn.Conv2d(3,1,5),]
self.c3_2 = [nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),
nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),]
self.c3_3 = [nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),nn.Conv2d(4,1,5),]
self.c3_4 = nn.Conv2d(6,1,5)
self.s4 = nn.Sequential(
nn.AvgPool2d(2),
nn.Sigmoid()
)
self.c5 = nn.Sequential(nn.Conv2d(16,120,5),nn.Sigmoid())
self.f6 = nn.Sequential(
nn.Linear(120,84),
nn.Tanh()
)
self.f7 = nn.Linear(84,10)
def forward(self,x):
x = self.c1(x)
x = self.s2(x)
feature_map = []
for index,kenal in enumerate(self.c3_1):
feature_map.append(kenal(torch.cat([x[:,index].view(x.size()[0],1,14,14),x[:,0 if index == 5 else index+1].view(x.size()[0],1,14,14),
x[:,index-4 if index +2 > 5 else index+2].view(x.size()[0],1,14,14),],dim = 1)))
for index,kenal in enumerate(self.c3_2):
feature_map.append(kenal(torch.cat([x[:,index].view(x.size()[0],1,14,14),x[:,index-2 if index == 5 else index+1].view(x.size()[0],1,14,14),
x[:,index-4 if index+2 > 5 else index+2].view(x.size()[0],1,14,14),
x[:,index-3 if index+3 > 5 else index+3].view(x.size()[0],1,14,14),],dim = 1)))
for index, kenal in enumerate(self.c3_3):
feature_map.append(kenal(torch.cat([x[:,index].view(x.size()[0],1,14,14), x[:,index + 1].view(x.size()[0],1,14,14),
x[:,index + 3].view(x.size()[0],1,14,14),x[:,0 if index+4>5 else index+4].view(x.size()[0],1,14,14), ], dim=1)))
feature_map.append(self.c3_4(x))
x = torch.cat(feature_map,dim = 1)
x = self.s4(x)
x = self.c5(x)
x = x.view(x.size()[0],120)
x = self.f6(x)
x = self.f7(x)
return x
if __name__ == '__main__':
#判断是否有GPU
#device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#绘图函数
plt.figure()
plt.title('test/train/loss')
#加载数据
train_mnist = mydata(r'D:\Deep_Learning\mnist\train')
train_image = data.DataLoader(dataset=train_mnist, batch_size=32, shuffle=True)
test_mnist = mydata(r'D:\Deep_Learning\mnist\mini_test')
test_image = data.DataLoader(dataset=train_mnist, batch_size=32, shuffle=True)
#加载模型
lenet_5 = Lenet_5()
# 定义损失函数
loss_fun = nn.MSELoss()
#SGD随机梯度下降
optimizer = torch.optim.SGD(lenet_5.parameters(),lr=0.0005)
#训练的轮数
epoch = 20
#统计训练和测试次数
train_num = 0
test_num = 0
train_loss = []
test_loss = []
#开始训练
for i in range(epoch):
#根据原论文进行了20次训练,训练期间学习率的调整
if i == 3:
for opt in optimizer.param_groups:
opt['lr'] = 0.0002
if i == 6:
for opt in optimizer.param_groups:
opt['lr'] = 0.0001
if i == 10:
for opt in optimizer.param_groups:
opt['lr'] = 0.00005
# #训练模型
for image,label in train_image:
#梯度归零
optimizer.zero_grad()
#训练模型
x = lenet_5(image)
#损失函数
loss = loss_fun(x,label)
#梯度下降
loss.backward()
optimizer.step()
#统计损失函数值
if train_num%100 == 0:
train_loss.append(loss.item())
print('epoch {} train loss {}'.format(i,loss.item()))
train_num += 1
#测试模型
for image,label in test_image:
with torch.no_grad():
x = lenet_5(image)
loss = loss_fun(x,label)
if test_num%100 == 0:
corr = torch.where(torch.argmax(x,dim=1) == torch.argmax(label,dim=1),1,0)
corr_rate = corr.sum()/(label.size()[0])
print('epoch {} test correct {}'.format(i,corr_rate))
test_loss.append(loss.item())
print('epoch {} test loss {}'.format(i,loss.item()))
test_num += 1
#绘制图像
plt.plot([i for i in range(len(train_loss))],train_loss,color = 'yellow')
plt.plot([i for i in range(len(test_loss))], test_loss, color='red')
plt.show()
plt.close()
总结
只是看别人写的文章了解网络结构总是给人一种模糊的感觉,只有看了原论文才能真正的了解该模型。所以这里我推荐大家去看原论文,对不能理解的地方再来看看文章的解析。好了就这样吧!