作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121072835
目录
前言:LeNet网络详解
(1)LeNet网络详解
(2)Pytorch官网对LeNet的定义
第1章 业务领域分析
1.1 步骤1-1:业务领域分析
(1)业务需求:数据集本身就说明了业务需求
(2)业务分析
本任务的本质是逻辑分类中的多分类,多分类中的10分类问题,即给定一张图形的特征数据(这里是单个图形的三通道像素值),能够判断其属于哪个物体分类。属于分类问题。
有很多现有的卷积神经网络可以解决分类问题,本文使用LeNet来解决这个简单的分类问题。
这里也有两个思路:
- 直接利用框架自带的LeNet网络完成模型的搭建。
- 自己按照LeNet网络的结构,使用Pytorch提供的卷积核自行搭建该网络。
由于LeNet网络比较简单,也为了熟悉Ptorch的nn网络,我们不妨尝试上述两种方法。
对于后续的复杂网络,我们可以直接利用平台提供的库,直接使用已有的网络,而不再手工搭建。
1.2 步骤1-2:业务建模
其实,这里不需要自己在建立数据模型了,可以直接使用LeNet已有的模型,模型参考如下:


1.3 训练模型

1.4 验证模型

1.5 整体架构

1.6 代码实例前置条件
#环境准备
import numpy as np # numpy数组库
import math # 数学运算库
import matplotlib.pyplot as plt # 画图库
import torch # torch基础库
import torch.nn as nn # torch神经网络库
import torch.nn.functional as F # torch神经网络库
from sklearn.datasets import load_boston
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())第2章 前向运算模型定义
2.1 步骤2-1:数据集选择
(1)CFAR10数据集
(2)样本数据与样本标签格式

(3)源代码示例 -- 下载并读入数据
#2-1 准备数据集
train_data = dataset.CIFAR10 (root = "cifar10",
train = True,
transform = transforms.ToTensor(),
download = True)
#2-1 准备数据集
test_data = dataset.CIFAR10 (root = "cifar10",
train = False,
transform = transforms.ToTensor(),
download = True)
print(train_data)
print("size=", len(train_data))
print("")
print(test_data)
print("size=", len(test_data))Files already downloaded and verified
Files already downloaded and verified
Dataset CIFAR10
Number of datapoints: 50000
Root location: cifar10
Split: Train
StandardTransform
Transform: ToTensor()
size= 50000
Dataset CIFAR10
Number of datapoints: 10000
Root location: cifar10
Split: Test
StandardTransform
Transform: ToTensor()
size= 10000
2.2 步骤2-2:数据预处理 - 本案例无需数据预处理
(1)批量数据读取 -- 启动dataloader从数据集中读取Batch数据
# 批量数据读取
train_loader = data_utils.DataLoader(dataset = train_data, #训练数据
batch_size = 64, #每个批次读取的图片数量
shuffle = True) #读取到的数据,是否需要随机打乱顺序
test_loader = data_utils.DataLoader(dataset = test_data, #测试数据集
batch_size = 64,
shuffle = True)
print(train_loader)
print(test_loader)
print(len(train_data), len(train_data)/64)
print(len(test_data), len(test_data)/64)(2)#显示一个batch图片 -- 仅仅用于调试
#显示一个batch图片
print("获取一个batch组图片")
imgs, labels = next(iter(train_loader))
print(imgs.shape)
print(labels.shape)
print(labels.size()[0])
print("\n合并成一张三通道灰度图片")
images = utils.make_grid(imgs)
print(images.shape)
print(labels.shape)
print("\n转换成imshow格式")
images = images.numpy().transpose(1,2,0)
print(images.shape)
print(labels.shape)
print("\n显示样本标签")
#打印图片标签
for i in range(64):
print(labels[i], end=" ")
i += 1
#换行
if i%8 == 0:
print(end='\n')
print("\n显示图片")
plt.imshow(images)
plt.show()获取一个batch组图片 torch.Size([64, 3, 32, 32]) torch.Size([64]) 64 合并成一张三通道灰度图片 torch.Size([3, 274, 274]) torch.Size([64]) 转换成imshow格式 (274, 274, 3) torch.Size([64]) 显示样本标签 tensor(3) tensor(7) tensor(9) tensor(8) tensor(9) tensor(0) tensor(6) tensor(4) tensor(1) tensor(1) tensor(3) tensor(9) tensor(7) tensor(6) tensor(9) tensor(7) tensor(3) tensor(5) tensor(5) tensor(8) tensor(7) tensor(5) tensor(5) tensor(7) tensor(0) tensor(7) tensor(5) tensor(3) tensor(2) tensor(6) tensor(2) tensor(5) tensor(6) tensor(1) tensor(8) tensor(5) tensor(2) tensor(5) tensor(9) tensor(3) tensor(3) tensor(0) tensor(9) tensor(5) tensor(0) tensor(4) tensor(1) tensor(8) tensor(2) tensor(0) tensor(5) tensor(3) tensor(1) tensor(8) tensor(8) tensor(5) tensor(6) tensor(5) tensor(4) tensor(6) tensor(2) tensor(8) tensor(8) tensor(4) 显示图片

2.3 步骤2-3:神经网络建模
(1)模型
LeNet-5 神经网络一共五层,其中卷积层和池化层可以考虑为一个整体,网络的结构为 :
输入 → 卷积 → 池化 → 卷积 → 池化 → 全连接 → 全连接 → 全连接 → 输出。
(2)Pytorch NN Conv2d用法详解
https://blog.csdn.net/HiWangWenBing/article/details/121051650
(3)Pytorch NN MaxPool2d用法详解
https://blog.csdn.net/HiWangWenBing/article/details/121053578
(4)使用Pytorch卷积核构建构建LeNet网络
在 pytorch 中,图像数据集(提供给网络的输入)的存储顺序为:
(batch, channels, height, width),依次为批大小、通道数、高度、宽度。
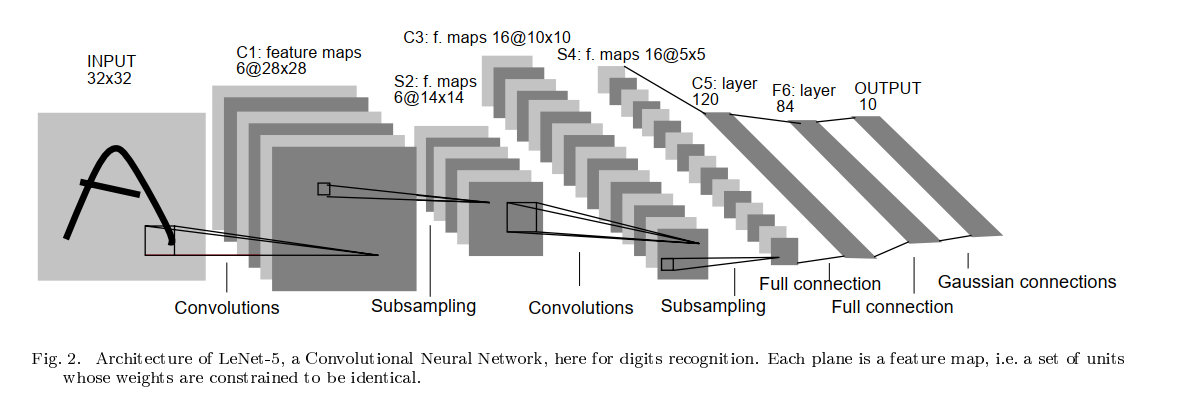
特别提醒:
LeNet-5网络的默认的输入图片的尺寸是32*32, 而Mnist数据集的图片的尺寸是28 * 28。
因此,采用Mnist数据集时,每一层的输出的特征值feature map的尺寸与LeNet-5网络的默认默认的feature map的尺寸是不一样的,需要适当的调整。
具体如何调整,请参考代码的实现:
下面以两种等效的方式定义LeNet神经网络:
- Pytorch官网方式
- 自定义方式
(5)构建LeNet网络结构的代码实例 - 官网
# 来自官网
class LeNet5A(nn.Module):
def __init__(self):
super(LeNet5A, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution kernel
self.conv1 = nn.Conv2d(in_channels = 3, out_channels = 6, kernel_size = 5) # 6 * 28 * 28
self.conv2 = nn.Conv2d(in_channels = 6, out_channels = 16, kernel_size = 5) # 16 * 10 * 10
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(in_features = 16 * 5 * 5, out_features= 120) # 16 * 5 * 5
self.fc2 = nn.Linear(in_features = 120, out_features = 84)
self.fc3 = nn.Linear(in_features = 84, out_features = 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square, you can specify with a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # flatten all dimensions except the batch dimension
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
#x = F.log_softmax(x,dim=1)
return x(6)构建LeNet网络结构的代码实例 - 自定义
class LeNet5B(nn.Module):
def __init__(self):
super(LeNet5B, self).__init__()
self.feature_convnet = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d (in_channels = 3, out_channels = 6, kernel_size= (5, 5), stride = 1)), # 6 * 28 * 28
('relu1', nn.ReLU()),
('pool1', nn.MaxPool2d(kernel_size=(2, 2))), # 6 * 14 * 14
('conv2', nn.Conv2d (in_channels = 6, out_channels = 16, kernel_size=(5, 5))), # 16 * 10 * 10
('relu2', nn.ReLU()),
('pool2', nn.MaxPool2d(kernel_size=(2, 2))), # 16 * 5 * 5
]))
self.class_fc = nn.Sequential(OrderedDict([
('fc1', nn.Linear(in_features = 16 * 5 * 5, out_features = 120)),
('relu3', nn.ReLU()),
('fc2', nn.Linear(in_features = 120, out_features = 84)),
('relu4', nn.ReLU()),
('fc3', nn.Linear(in_features = 84, out_features = 10)),
]))
def forward(self, img):
output = self.feature_convnet(img)
output = output.view(-1, 16 * 5 * 5) #相当于Flatten()
output = self.class_fc(output)
return output2.4 步骤2-4:定义神经网络实例以及输出
net_a = LeNet5A()
print(net_a)LeNet5A( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True) )
net_b = LeNet5B()
print(net_b)LeNet5B(
(feature_convnet): Sequential(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(relu1): ReLU()
(pool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(relu2): ReLU()
(pool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(class_fc): Sequential(
(fc1): Linear(in_features=400, out_features=120, bias=True)
(relu3): ReLU()
(fc2): Linear(in_features=120, out_features=84, bias=True)
(relu4): ReLU()
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
)
# 2-4 定义网络预测输出
# 测试网络是否能够工作
print("定义测试数据")
input = torch.randn(1, 3, 32, 32)
print("")
print("net_a的输出方法1:")
out = net_a(input)
print(out)
print("net_a的输出方法2:")
out = net_a.forward(input)
print(out)
print("")
print("net_b的输出方法1:")
out = net_b(input)
print(out)
print("net_b的输出方法2:")
out = net_b.forward(input)
print(out)定义测试数据
net_a的输出方法1:
tensor([[-0.0969, -0.1226, 0.0581, 0.0373, 0.0028, 0.1278, -0.1044, -0.1068,
-0.0097, 0.0272]], grad_fn=<AddmmBackward>)
net_a的输出方法2:
tensor([[-0.0969, -0.1226, 0.0581, 0.0373, 0.0028, 0.1278, -0.1044, -0.1068,
-0.0097, 0.0272]], grad_fn=<AddmmBackward>)
net_b的输出方法1:
tensor([[-0.0052, 0.0682, -0.1567, 0.0173, 0.0977, -0.0599, 0.0969, -0.0656,
0.0591, -0.1179]], grad_fn=<AddmmBackward>)
net_b的输出方法2:
tensor([[-0.0052, 0.0682, -0.1567, 0.0173, 0.0977, -0.0599, 0.0969, -0.0656,
0.0591, -0.1179]], grad_fn=<AddmmBackward>)
第3章 定义反向计算
3.1 步骤3-1:定义loss
# 3-1 定义loss函数:
loss_fn = nn.CrossEntropyLoss()
print(loss_fn)3.2 步骤3-2:定义优化器
# 3-2 定义优化器
net = net_a
Learning_rate = 0.001 #学习率
# optimizer = SGD: 基本梯度下降法
# parameters:指明要优化的参数列表
# lr:指明学习率
#optimizer = torch.optim.Adam(model.parameters(), lr = Learning_rate)
optimizer = torch.optim.SGD(net.parameters(), lr = Learning_rate, momentum=0.9)
print(optimizer)SGD (
Parameter Group 0
dampening: 0
lr: 0.001
momentum: 0.9
nesterov: False
weight_decay: 0
)
3.3 步骤3-3:模型训练 (epochs = 10)
# 3-3 模型训练
# 定义迭代次数
epochs = 10
loss_history = [] #训练过程中的loss数据
accuracy_history =[] #中间的预测结果
accuracy_batch = 0.0
for i in range(0, epochs):
for j, (x_train, y_train) in enumerate(train_loader):
#(0) 复位优化器的梯度
optimizer.zero_grad()
#(1) 前向计算
y_pred = net(x_train)
#(2) 计算loss
loss = loss_fn(y_pred, y_train)
#(3) 反向求导
loss.backward()
#(4) 反向迭代
optimizer.step()
# 记录训练过程中的损失值
loss_history.append(loss.item()) #loss for a batch
# 记录训练过程中的在训练集上该批次的准确率
number_batch = y_train.size()[0] # 训练批次中图片的个数
_, predicted = torch.max(y_pred.data, dim = 1) # 选出最大可能性的预测
correct_batch = (predicted == y_train).sum().item() # 获得预测正确的数目
accuracy_batch = 100 * correct_batch/number_batch # 计算该批次上的准确率
accuracy_history.append(accuracy_batch) # 该批次的准确率添加到log中
if(j % 100 == 0):
print('epoch {} batch {} In {} loss = {:.4f} accuracy = {:.4f}%'.format(i, j , len(train_data)/64, loss.item(), accuracy_batch))
print("\n迭代完成")
print("final loss =", loss.item())
print("final accu =", accuracy_batch)epoch 0 batch 0 In 781.25 loss = 2.2998 accuracy = 7.8125% epoch 0 batch 100 In 781.25 loss = 2.3023 accuracy = 9.3750% epoch 0 batch 200 In 781.25 loss = 2.2958 accuracy = 14.0625% epoch 0 batch 300 In 781.25 loss = 2.3062 accuracy = 9.3750% epoch 0 batch 400 In 781.25 loss = 2.2994 accuracy = 7.8125% epoch 0 batch 500 In 781.25 loss = 2.3016 accuracy = 10.9375% epoch 0 batch 600 In 781.25 loss = 2.3040 accuracy = 6.2500% epoch 0 batch 700 In 781.25 loss = 2.3030 accuracy = 4.6875% epoch 1 batch 0 In 781.25 loss = 2.3024 accuracy = 4.6875% epoch 1 batch 100 In 781.25 loss = 2.2962 accuracy = 14.0625% epoch 1 batch 200 In 781.25 loss = 2.2991 accuracy = 18.7500% epoch 1 batch 300 In 781.25 loss = 2.2985 accuracy = 12.5000% epoch 1 batch 400 In 781.25 loss = 2.2965 accuracy = 15.6250% epoch 1 batch 500 In 781.25 loss = 2.2950 accuracy = 14.0625% epoch 1 batch 600 In 781.25 loss = 2.2851 accuracy = 21.8750% epoch 1 batch 700 In 781.25 loss = 2.2719 accuracy = 7.8125% epoch 2 batch 0 In 781.25 loss = 2.2673 accuracy = 14.0625% epoch 2 batch 100 In 781.25 loss = 2.2646 accuracy = 18.7500% epoch 2 batch 200 In 781.25 loss = 2.2156 accuracy = 18.7500% epoch 2 batch 300 In 781.25 loss = 2.1538 accuracy = 18.7500% epoch 2 batch 400 In 781.25 loss = 2.0801 accuracy = 15.6250% epoch 2 batch 500 In 781.25 loss = 2.0368 accuracy = 28.1250% epoch 2 batch 600 In 781.25 loss = 2.2541 accuracy = 18.7500% epoch 2 batch 700 In 781.25 loss = 1.8632 accuracy = 32.8125% epoch 3 batch 0 In 781.25 loss = 2.0807 accuracy = 28.1250% epoch 3 batch 100 In 781.25 loss = 1.9539 accuracy = 26.5625% epoch 3 batch 200 In 781.25 loss = 1.9882 accuracy = 23.4375% epoch 3 batch 300 In 781.25 loss = 1.9672 accuracy = 25.0000% epoch 3 batch 400 In 781.25 loss = 1.9345 accuracy = 25.0000% epoch 3 batch 500 In 781.25 loss = 1.9574 accuracy = 18.7500% epoch 3 batch 600 In 781.25 loss = 1.7351 accuracy = 28.1250% epoch 3 batch 700 In 781.25 loss = 1.7798 accuracy = 34.3750% epoch 4 batch 0 In 781.25 loss = 1.8423 accuracy = 29.6875% epoch 4 batch 100 In 781.25 loss = 1.7056 accuracy = 29.6875% epoch 4 batch 200 In 781.25 loss = 1.8324 accuracy = 32.8125% epoch 4 batch 300 In 781.25 loss = 1.9146 accuracy = 28.1250% epoch 4 batch 400 In 781.25 loss = 1.7319 accuracy = 34.3750% epoch 4 batch 500 In 781.25 loss = 1.6023 accuracy = 35.9375% epoch 4 batch 600 In 781.25 loss = 1.6365 accuracy = 43.7500% epoch 4 batch 700 In 781.25 loss = 1.6822 accuracy = 37.5000% epoch 5 batch 0 In 781.25 loss = 1.8602 accuracy = 35.9375% epoch 5 batch 100 In 781.25 loss = 1.3989 accuracy = 48.4375% epoch 5 batch 200 In 781.25 loss = 1.6256 accuracy = 40.6250% epoch 5 batch 300 In 781.25 loss = 1.8250 accuracy = 34.3750% epoch 5 batch 400 In 781.25 loss = 1.6592 accuracy = 32.8125% epoch 5 batch 500 In 781.25 loss = 1.6617 accuracy = 40.6250% epoch 5 batch 600 In 781.25 loss = 1.5431 accuracy = 42.1875% epoch 5 batch 700 In 781.25 loss = 1.6123 accuracy = 43.7500% epoch 6 batch 0 In 781.25 loss = 1.8649 accuracy = 29.6875% epoch 6 batch 100 In 781.25 loss = 1.5037 accuracy = 43.7500% epoch 6 batch 200 In 781.25 loss = 1.4193 accuracy = 45.3125% epoch 6 batch 300 In 781.25 loss = 1.5146 accuracy = 50.0000% epoch 6 batch 400 In 781.25 loss = 1.4917 accuracy = 50.0000% epoch 6 batch 500 In 781.25 loss = 1.5940 accuracy = 37.5000% epoch 6 batch 600 In 781.25 loss = 1.4959 accuracy = 42.1875% epoch 6 batch 700 In 781.25 loss = 1.5738 accuracy = 39.0625% epoch 7 batch 0 In 781.25 loss = 1.7241 accuracy = 43.7500% epoch 7 batch 100 In 781.25 loss = 1.4952 accuracy = 46.8750% epoch 7 batch 200 In 781.25 loss = 1.5233 accuracy = 37.5000% epoch 7 batch 300 In 781.25 loss = 1.5373 accuracy = 45.3125% epoch 7 batch 400 In 781.25 loss = 1.4451 accuracy = 50.0000% epoch 7 batch 500 In 781.25 loss = 1.4423 accuracy = 48.4375% epoch 7 batch 600 In 781.25 loss = 1.4838 accuracy = 50.0000% epoch 7 batch 700 In 781.25 loss = 1.5223 accuracy = 48.4375% epoch 8 batch 0 In 781.25 loss = 1.4175 accuracy = 54.6875% epoch 8 batch 100 In 781.25 loss = 1.4949 accuracy = 46.8750% epoch 8 batch 200 In 781.25 loss = 1.3644 accuracy = 46.8750% epoch 8 batch 300 In 781.25 loss = 1.5125 accuracy = 39.0625% epoch 8 batch 400 In 781.25 loss = 1.5507 accuracy = 39.0625% epoch 8 batch 500 In 781.25 loss = 1.4964 accuracy = 37.5000% epoch 8 batch 600 In 781.25 loss = 1.5248 accuracy = 40.6250% epoch 8 batch 700 In 781.25 loss = 1.2663 accuracy = 53.1250% epoch 9 batch 0 In 781.25 loss = 1.4140 accuracy = 43.7500% epoch 9 batch 100 In 781.25 loss = 1.3880 accuracy = 53.1250% epoch 9 batch 200 In 781.25 loss = 1.2337 accuracy = 51.5625% epoch 9 batch 300 In 781.25 loss = 1.3268 accuracy = 51.5625% epoch 9 batch 400 In 781.25 loss = 1.3944 accuracy = 40.6250% epoch 9 batch 500 In 781.25 loss = 1.4345 accuracy = 57.8125% epoch 9 batch 600 In 781.25 loss = 1.3305 accuracy = 51.5625% epoch 9 batch 700 In 781.25 loss = 1.4600 accuracy = 57.8125% epoch 10 batch 0 In 781.25 loss = 1.4065 accuracy = 50.0000% epoch 10 batch 100 In 781.25 loss = 1.3810 accuracy = 53.1250% epoch 10 batch 200 In 781.25 loss = 1.4630 accuracy = 46.8750% epoch 10 batch 300 In 781.25 loss = 1.4755 accuracy = 51.5625% epoch 10 batch 400 In 781.25 loss = 1.2332 accuracy = 43.7500% epoch 10 batch 500 In 781.25 loss = 1.3078 accuracy = 57.8125% epoch 10 batch 600 In 781.25 loss = 1.2185 accuracy = 53.1250% epoch 10 batch 700 In 781.25 loss = 1.2658 accuracy = 59.3750% epoch 11 batch 0 In 781.25 loss = 1.3261 accuracy = 57.8125% epoch 11 batch 100 In 781.25 loss = 1.2700 accuracy = 54.6875% epoch 11 batch 200 In 781.25 loss = 1.3970 accuracy = 46.8750% epoch 11 batch 300 In 781.25 loss = 1.3336 accuracy = 54.6875% epoch 11 batch 400 In 781.25 loss = 1.3989 accuracy = 50.0000% epoch 11 batch 500 In 781.25 loss = 1.3394 accuracy = 46.8750% epoch 11 batch 600 In 781.25 loss = 1.3924 accuracy = 56.2500% epoch 11 batch 700 In 781.25 loss = 1.2620 accuracy = 56.2500% epoch 12 batch 0 In 781.25 loss = 1.1936 accuracy = 51.5625% epoch 12 batch 100 In 781.25 loss = 1.4169 accuracy = 50.0000% epoch 12 batch 200 In 781.25 loss = 1.2697 accuracy = 56.2500% epoch 12 batch 300 In 781.25 loss = 1.3202 accuracy = 53.1250% epoch 12 batch 400 In 781.25 loss = 1.4378 accuracy = 37.5000% epoch 12 batch 500 In 781.25 loss = 1.1814 accuracy = 62.5000% epoch 12 batch 600 In 781.25 loss = 1.3979 accuracy = 51.5625% epoch 12 batch 700 In 781.25 loss = 1.6219 accuracy = 43.7500% epoch 13 batch 0 In 781.25 loss = 1.7161 accuracy = 48.4375% epoch 13 batch 100 In 781.25 loss = 1.3266 accuracy = 50.0000% epoch 13 batch 200 In 781.25 loss = 1.3687 accuracy = 50.0000% epoch 13 batch 300 In 781.25 loss = 1.4488 accuracy = 50.0000% epoch 13 batch 400 In 781.25 loss = 1.3780 accuracy = 51.5625% epoch 13 batch 500 In 781.25 loss = 1.4341 accuracy = 53.1250% epoch 13 batch 600 In 781.25 loss = 1.2450 accuracy = 60.9375% epoch 13 batch 700 In 781.25 loss = 1.4046 accuracy = 57.8125% epoch 14 batch 0 In 781.25 loss = 1.2583 accuracy = 57.8125% epoch 14 batch 100 In 781.25 loss = 1.2042 accuracy = 59.3750% epoch 14 batch 200 In 781.25 loss = 1.0217 accuracy = 60.9375% epoch 14 batch 300 In 781.25 loss = 1.5322 accuracy = 39.0625% epoch 14 batch 400 In 781.25 loss = 1.2680 accuracy = 59.3750% epoch 14 batch 500 In 781.25 loss = 1.4117 accuracy = 43.7500% epoch 14 batch 600 In 781.25 loss = 1.2070 accuracy = 56.2500% epoch 14 batch 700 In 781.25 loss = 1.5578 accuracy = 53.1250% epoch 15 batch 0 In 781.25 loss = 1.2705 accuracy = 50.0000% epoch 15 batch 100 In 781.25 loss = 1.3118 accuracy = 53.1250% epoch 15 batch 200 In 781.25 loss = 1.3140 accuracy = 56.2500% epoch 15 batch 300 In 781.25 loss = 1.2689 accuracy = 50.0000% epoch 15 batch 400 In 781.25 loss = 1.3345 accuracy = 54.6875% epoch 15 batch 500 In 781.25 loss = 1.2388 accuracy = 57.8125% epoch 15 batch 600 In 781.25 loss = 1.3317 accuracy = 51.5625% epoch 15 batch 700 In 781.25 loss = 1.0944 accuracy = 60.9375% epoch 16 batch 0 In 781.25 loss = 0.9785 accuracy = 65.6250% epoch 16 batch 100 In 781.25 loss = 1.3298 accuracy = 48.4375% epoch 16 batch 200 In 781.25 loss = 1.2975 accuracy = 56.2500% epoch 16 batch 300 In 781.25 loss = 1.3631 accuracy = 45.3125%
epoch 16 batch 400 In 781.25 loss = 1.1714 accuracy = 51.5625%
epoch 16 batch 500 In 781.25 loss = 1.2197 accuracy = 56.2500%
epoch 16 batch 600 In 781.25 loss = 1.1604 accuracy = 54.6875%
epoch 16 batch 700 In 781.25 loss = 1.3643 accuracy = 45.3125%
epoch 17 batch 0 In 781.25 loss = 1.2571 accuracy = 54.6875%
epoch 17 batch 100 In 781.25 loss = 1.3136 accuracy = 50.0000%
epoch 17 batch 200 In 781.25 loss = 1.0692 accuracy = 64.0625%
epoch 17 batch 300 In 781.25 loss = 1.2984 accuracy = 54.6875%
epoch 17 batch 400 In 781.25 loss = 1.3145 accuracy = 56.2500%
epoch 17 batch 500 In 781.25 loss = 1.0156 accuracy = 65.6250%
epoch 17 batch 600 In 781.25 loss = 1.4033 accuracy = 50.0000%
epoch 17 batch 700 In 781.25 loss = 1.3489 accuracy = 48.4375%
epoch 18 batch 0 In 781.25 loss = 1.3279 accuracy = 48.4375%
epoch 18 batch 100 In 781.25 loss = 1.0127 accuracy = 56.2500%
epoch 18 batch 200 In 781.25 loss = 1.2629 accuracy = 48.4375%
epoch 18 batch 300 In 781.25 loss = 1.1487 accuracy = 59.3750%
epoch 18 batch 400 In 781.25 loss = 1.3890 accuracy = 56.2500%
epoch 18 batch 500 In 781.25 loss = 1.0579 accuracy = 62.5000%
epoch 18 batch 600 In 781.25 loss = 1.3453 accuracy = 50.0000%
epoch 18 batch 700 In 781.25 loss = 1.1905 accuracy = 51.5625%
epoch 19 batch 0 In 781.25 loss = 1.1903 accuracy = 57.8125%
epoch 19 batch 100 In 781.25 loss = 1.1407 accuracy = 62.5000%
epoch 19 batch 200 In 781.25 loss = 1.2654 accuracy = 56.2500%
epoch 19 batch 300 In 781.25 loss = 1.2199 accuracy = 57.8125%
epoch 19 batch 400 In 781.25 loss = 1.2242 accuracy = 64.0625%
epoch 19 batch 500 In 781.25 loss = 1.0288 accuracy = 67.1875%
epoch 19 batch 600 In 781.25 loss = 1.0358 accuracy = 60.9375%
epoch 19 batch 700 In 781.25 loss = 1.1985 accuracy = 65.6250%
迭代完成
final loss = 0.8100204467773438
final accu = 68.75
3.4 可视化loss迭代过程
#显示loss的历史数据
plt.grid()
plt.xlabel("iters")
plt.ylabel("")
plt.title("loss", fontsize = 12)
plt.plot(loss_history, "r")
plt.show()

3.5 可视化训练批次的精度迭代过程
#显示准确率的历史数据
plt.grid()
plt.xlabel("iters")
plt.ylabel("%")
plt.title("accuracy", fontsize = 12)
plt.plot(accuracy_history, "b+")
plt.show()
第4章 模型性能验证
4.1 手工验证
# 手工检查
index = 0
print("获取一个batch样本")
images, labels = next(iter(test_loader))
print(images.shape)
print(labels.shape)
print(labels)
print("\n对batch中所有样本进行预测")
outputs = net(images)
print(outputs.data.shape)
print("\n对batch中每个样本的预测结果,选择最可能的分类")
_, predicted = torch.max(outputs, 1)
print(predicted.data.shape)
print(predicted)
print("\n对batch中的所有结果进行比较")
bool_results = (predicted == labels)
print(bool_results.shape)
print(bool_results)
print("\n统计预测正确样本的个数和精度")
corrects = bool_results.sum().item()
accuracy = corrects/(len(bool_results))
print("corrects=", corrects)
print("accuracy=", accuracy)
print("\n样本index =", index)
print("标签值 :", labels[index]. item())
print("分类可能性:", outputs.data[index].numpy())
print("最大可能性:",predicted.data[index].item())
print("正确性 :",bool_results.data[index].item())获取一个batch样本
torch.Size([64, 3, 32, 32])
torch.Size([64])
tensor([6, 5, 9, 6, 9, 4, 1, 1, 2, 0, 0, 2, 6, 9, 2, 9, 1, 1, 6, 1, 1, 4, 4, 3,
1, 9, 9, 7, 3, 9, 6, 3, 7, 9, 1, 4, 8, 0, 9, 4, 5, 8, 8, 4, 4, 8, 0, 4,
0, 8, 6, 3, 5, 9, 2, 0, 7, 2, 3, 7, 1, 6, 7, 5])
对batch中所有样本进行预测
torch.Size([64, 10])
对batch中每个样本的预测结果,选择最可能的分类
torch.Size([64])
tensor([8, 2, 9, 6, 4, 6, 1, 1, 5, 0, 0, 0, 6, 1, 9, 1, 1, 3, 8, 1, 1, 6, 6, 2,
1, 9, 9, 7, 5, 9, 6, 1, 5, 9, 1, 1, 8, 0, 0, 4, 6, 8, 8, 2, 4, 8, 0, 4,
0, 8, 6, 3, 5, 9, 2, 8, 1, 7, 4, 8, 8, 6, 7, 7])
对batch中的所有结果进行比较
torch.Size([64])
tensor([False, False, True, True, False, False, True, True, False, True,
True, False, True, False, False, False, True, False, False, True,
True, False, False, False, True, True, True, True, False, True,
True, False, False, True, True, False, True, True, False, True,
False, True, True, False, True, True, True, True, True, True,
True, True, True, True, True, False, False, False, False, False,
False, True, True, False])
统计预测正确样本的个数和精度
corrects= 36
accuracy= 0.5625
样本index = 0
标签值 : 6
分类可能性: [-0.29385602 -3.5680068 -0.11207527 2.3141491 -1.4549704 0.86066306
1.0907507 -3.04807 3.4386015 -1.4474211 ]
最大可能性: 8
正确性 : False
4.2 整个训练集上的精度验证:精度只有58%
# 对训练后的模型进行评估:测试其在训练集上总的准确率
correct_dataset = 0
total_dataset = 0
accuracy_dataset = 0.0
# 进行评测的时候网络不更新梯度
with torch.no_grad():
for i, data in enumerate(train_loader):
#获取一个batch样本"
images, labels = data
#对batch中所有样本进行预测
outputs = net(images)
#对batch中每个样本的预测结果,选择最可能的分类
_, predicted = torch.max(outputs.data, 1)
#对batch中的样本数进行累计
total_dataset += labels.size()[0]
#对batch中的所有结果进行比较"
bool_results = (predicted == labels)
#统计预测正确样本的个数
correct_dataset += bool_results.sum().item()
#统计预测正确样本的精度
accuracy_dataset = 100 * correct_dataset/total_dataset
if(i % 100 == 0):
print('batch {} In {} accuracy = {:.4f}'.format(i, len(train_data)/64, accuracy_dataset))
print('Final result with the model on the dataset, accuracy =', accuracy_dataset)batch 0 In 781.25 accuracy = 50.0000
batch 100 In 781.25 accuracy = 57.7970
batch 200 In 781.25 accuracy = 57.9291
batch 300 In 781.25 accuracy = 57.6256
batch 400 In 781.25 accuracy = 57.6761
batch 500 In 781.25 accuracy = 57.6129
batch 600 In 781.25 accuracy = 57.6071
batch 700 In 781.25 accuracy = 57.4715
Final result with the model on the dataset, accuracy = 57.598
4.3 整个测试集上的精度验证:精度只有58%
# 对训练后的模型进行评估:测试其在训练集上总的准确率
correct_dataset = 0
total_dataset = 0
accuracy_dataset = 0.0
# 进行评测的时候网络不更新梯度
with torch.no_grad():
for i, data in enumerate(test_loader):
#获取一个batch样本"
images, labels = data
#对batch中所有样本进行预测
outputs = net(images)
#对batch中每个样本的预测结果,选择最可能的分类
_, predicted = torch.max(outputs.data, 1)
#对batch中的样本数进行累计
total_dataset += labels.size()[0]
#对batch中的所有结果进行比较"
bool_results = (predicted == labels)
#统计预测正确样本的个数
correct_dataset += bool_results.sum().item()
#统计预测正确样本的精度
accuracy_dataset = 100 * correct_dataset/total_dataset
if(i % 100 == 0):
print('batch {} In {} accuracy = {:.4f}'.format(i, len(test_data)/64, accuracy_dataset))
print('Final result with the model on the dataset, accuracy =', accuracy_dataset)batch 0 In 156.25 accuracy = 54.6875
batch 100 In 156.25 accuracy = 54.5947
Final result with the model on the dataset, accuracy = 54.94
结论:
LeNet在MNIST数据集上的准确率可以高达98%.
LeNet在CFAR10上的准确率不足60%,因此需要一个更深的神经网络。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121072835