作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【语义分割】技术交流群
后台回复【分割综述】获取语义分割、实例分割、全景分割、弱监督分割等超全学习资料!

Title: Segment Anything in High Quality
PDF: https://arxiv.org/pdf/2306.01567v1.pdf
Code: https://github.com/SysCV/SAM-HQ
导读
SAM 拥有强大的零样本能力和灵活的提示功能,尽管它已经通过11亿个掩膜进行了训练,但在很多情况下,特别是处理结构复杂的对象时,其掩膜预测质量还是有所欠缺。
为此,本文提出了HQ-SAM,为SAM赋予了准确分割任何对象的能力,同时保持了SAM的原始设计、效率和零样本泛化能力。作者设计重用并保留了SAM的预训练模型权重,同时仅引入了最小的额外参数和计算。与此同时还设计了一个可学习的高质量输出令牌,该令牌被注入到SAM的掩膜解码器中,负责预测高质量的遮罩。该方法不仅将其应用于掩膜解码器特征,而且首先将其与初期和最终的ViT特征融合,以改善细节。为了训练引入的可学习参数,本文构建了一个包含44K细粒度掩膜的数据集。HQ-SAM仅在这个引入的44k 掩膜数据集上进行训练,这在8个GPU上只需4小时。
最终,本文在9个不同的分割数据集中展示了HQ-SAM的有效性,这些数据集覆盖了不同的下游任务,其中7个任务在零样本迁移中进行了评估。
引言
对多样化物体进行精确的分割是一系列场景理解应用的基础,包括图像/视频编辑、机器人感知,以及AR/VR等。"Segment Anything Model"(SAM)模型被设计出来,作为通用图像分割的基础视觉模型,它经过了十亿级别的掩膜标签的训练。SAM模型通过接受一个包含点、边界框或者粗糙掩膜的提示,可以在各种场景下分割出一系列物体、部分和视觉结构。尽管SAM模型取得了令人印象深刻的性能,但其分割结果在许多情况下仍然无法满足需求,特别是对于自动标注和图像/视频编辑任务,这些任务对于图像掩膜的精度有着极高的要求。
因此,作者提出了一个新的模型HQ-SAM,能够在保持原始SAM模型的零样本能力和灵活性的同时,预测出极高精度的分割掩膜。为了维护效率和零样本性能,作者在SAM模型上进行了微小的改动,只增加了少于0.5%的参数,以提升其高质量分割的能力。他们设计了一个可学习的HQ-Output令牌,该令牌被输入到SAM的掩膜解码器中,并且被训练以预测高质量的分割掩膜。此外,HQ-Output令牌在一个优化后的特征集上运行,以实现精确的掩膜细节。
为了学习精确的分割,需要一个包含精确掩膜注释的数据集。因此,作者构建了一个新的数据集,名为HQSeg-44K,该数据集包含了44K极其细粒度的图像掩膜注释,覆盖了超过1000种不同的语义类别。由于数据集规模较小和他们的最小化集成架构,HQ-SAM在8个RTX 3090 GPU上只需4小时就能完成训练。
为了验证HQ-SAM的有效性,作者进行了大量的定量和定性实验分析。他们将HQ-SAM与SAM在9个不同的分割数据集中进行比较,这些数据集涵盖了不同的下游任务,其中7个任务采用了零样本转移协议。严格的评估表明,与SAM相比,本文提出的HQ-SAM能够生成更高质量的掩膜,同时保持零样本的能力。
方法
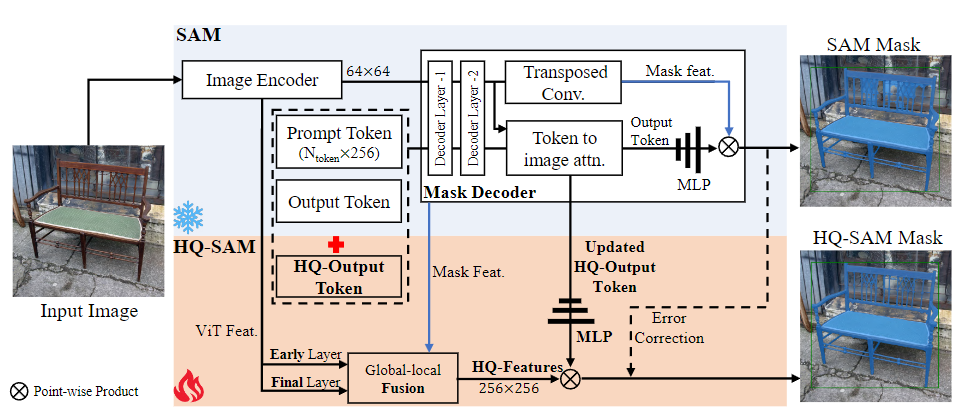
HQ-SAM为了实现高质量的掩膜预测,将HQ-Output Token(高质量输出标记)和全局-局部特征融合引入到SAM中。为了保持SAM的零射能力,轻量级的HQ-Output Token复用了SAM的掩膜解码器,并生成了新的MLP(多层感知器)层来执行与融合后的HQ-Features(高质量特征)的逐点乘积。在训练期间,将预训练的SAM的模型参数固定,只有HQ-SAM中的少数可学习参数可以进行训练。
为了提升原SAM模型在零样本分割任务上的性能,同时保留其零样本的特性。HQ-SAM对SAM模型进行了两处关键的改动。
首先,作者在SAM模型的基础上引入了一个新的输出令牌(High-Quality Output Token)和全局-局部特征融合。HQ-Output Token可以更好地指导高质量的掩模生成,而全局-局部特征融合则可以将来自不同阶段的特征提取和融合,从而富化掩模特征的全局语义上下文和局部边界细节。
HQ-Output Token的引入对SAM模型的掩模预测能力进行了提升。在原SAM模型的设计中,掩模解码器使用一个输出令牌(类似于DETR中的对象查询)进行掩模预测。在HQ-SAM中,作者引入了一个新的可学习的HQ-Output Token,并加入了一个新的掩模预测层来进行高质量的掩模预测。
其次,全局-局部特征融合通过提取和融合SAM模型不同阶段的特征来提升掩模质量。具体来说,作者将SAM模型的ViT编码器的早期层次特征、ViT编码器的最后一层全局特征以及SAM模型掩模解码器的掩模特征进行了融合,生成了新的高质量特征(HQ-Features)。

基于ViT-L的SAM和HQ-SAM的训练和推理比较。HQ-SAM给SAM带来了微不足道的额外计算负担,模型参数的增加少于0.5%,并且达到了其原始速度的96%。SAM-L在128个A100 GPU上进行了180k次迭代的训练。基于SAM-L,只需要在8个RTX3090 GPU上训练HQ-SAM 4小时。
HQ-SAM的训练和推理过程是数据和计算高效的。在训练阶段,作者固定了预训练的SAM模型的参数,只对HQ-SAM中的新引入的可学习参数进行训练。在推理阶段,作者遵循了SAM的推理流程,但使用了HQ-Output token的掩模预测作为高质量的掩模预测。
总体来说,HQ-SAM相比原SAM模型,在提升分割质量的同时,训练过程更加高效,只需要4小时就可以在8块RTX3090 GPUs上完成训练。HQ-SAM也是非常轻量级,增加的模型参数、GPU内存使用和每图像推理时间都可以忽略不计。
实验

SAM与我们的HQ-SAM预测的掩膜比较,输入提示是相同的红色框或者在对象上的几个点。HQ-SAM产生了更为详细且具有非常准确边界的结果。在最右边的列中,SAM错误地解读了风筝线的细长结构,并且在输入框提示下产生了大量带有断裂孔洞的错误。
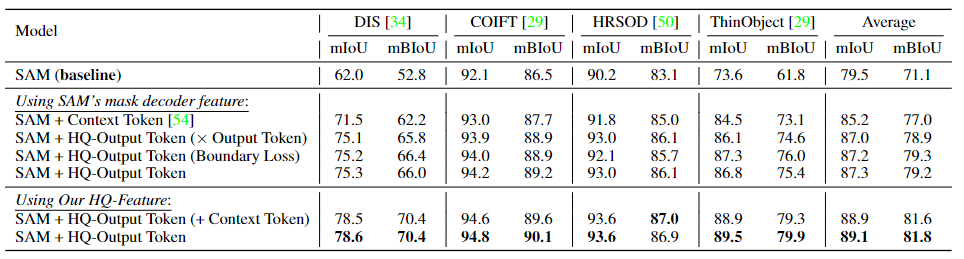
对四个极端细粒度的分割数据集进行的HQ-Output Token的消融实验。本文采用从它们的GT(Ground Truth,真值)mask转换过来的框作为框提示输入。默认情况下,通过计算全GT掩膜损失来训练HQ Output-Token的预测掩膜。
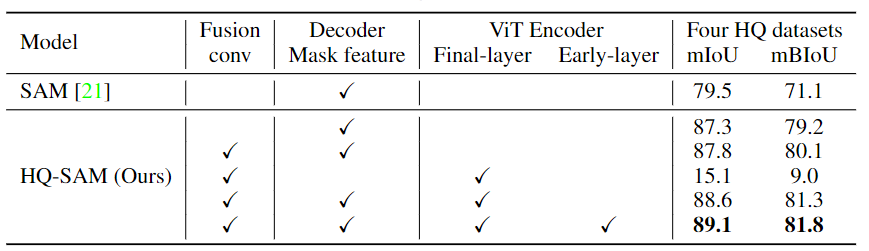
关于HQ-Features来源的消融实验。早期层(Early-layer)表示ViT编码器的第一个全局注意力块之后的特征,而最终层(final-layer)表示最后一个ViT块的输出。四个HQ数据集分别是DIS(验证集),ThinObject-5K(测试集),COIFT 和HR-SOD 。
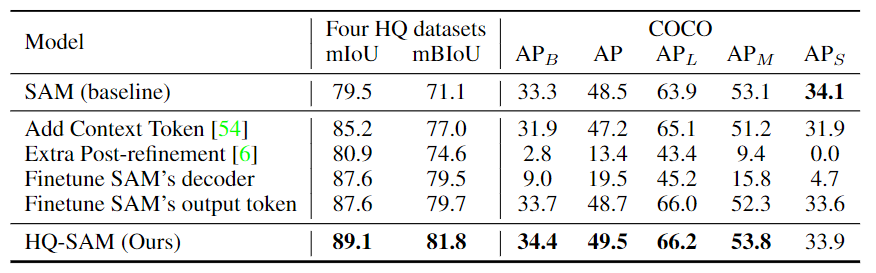
模型微调或额外后处理的比较。对于COCO数据集,作者使用在COCO数据集上训练的最新水平的目标检测器FocalNet-DINO作为边界框提示生成器。
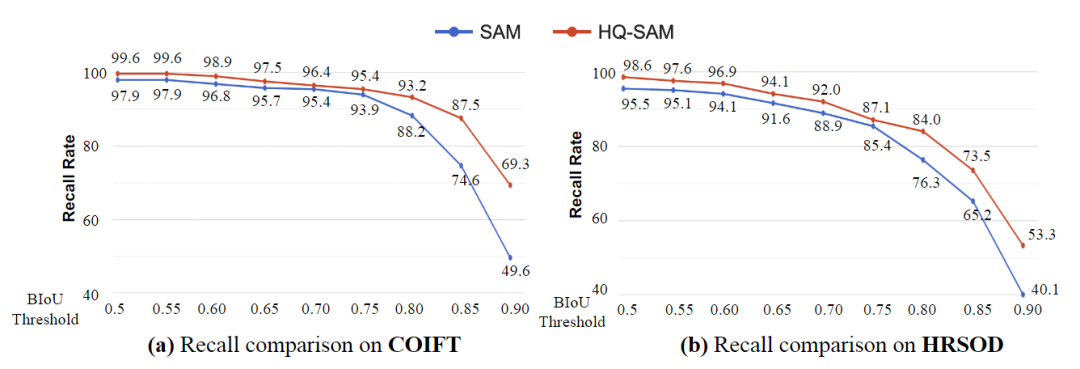
上图展示了COIFT和HRSOD在零样本协议下的召回率比较,使用了从宽松到严格的BIoU阈值。结果显示,当阈值从0.5变化到0.9时,SAM和HQ-SAM之间的性能差距显著增大。这表明HQ-SAM在预测非常准确的分割掩码方面具有优势,即HQ-SAM能够更准确地进行目标分割,尤其在对于严格的阈值要求下表现更好。

在UVO数据集上进行零样本开放世界实例分割的结果比较。为了生成边界提示,作者使用在COCO数据集上训练的FocalNet-DINO模型。其中,符号表示使用更严格的阈值来定义边界区域。

在高质量BIG基准测试集上进行零样本分割结果的比较。为了生成输入提示,作者使用了PSPNet来生成粗糙的掩码提示。通过比较不同类型的输入提示,对零样本分割结果进行了评估。
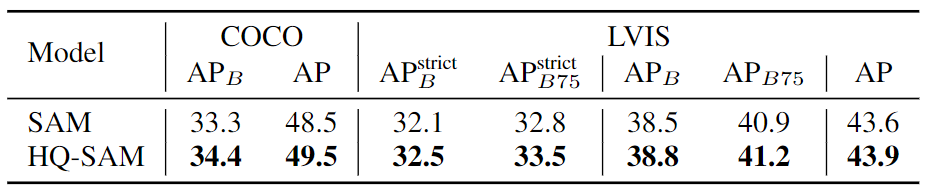
在COCO和LVISv1数据集上进行零样本实例分割结果的比较。对于COCO数据集,作者使用在COCO上训练的FocalNet-DINO模型进行检测,而对于LVIS数据集,则采用在LVIS数据集上训练的ViTDet-H作为它们的边界提示生成器。在SAM模型中,作者使用了ViT-L作为骨干网络,并使用了边界提示。作者在保持原始SAM的零样本分割能力的同时,改善了边界区域的掩码质量。

上图展示了SAM和HQ-SAM在零样本迁移设置下,给定相同的红色框或点提示时的视觉结果比较。从结果可以看出,HQ-SAM产生了明显更多保留细节的结果,并且还修复了掩码中的错误孔洞。相比之下,HQ-SAM在零样本迁移任务中能够更好地保留目标细节,并处理掩码中的错误。
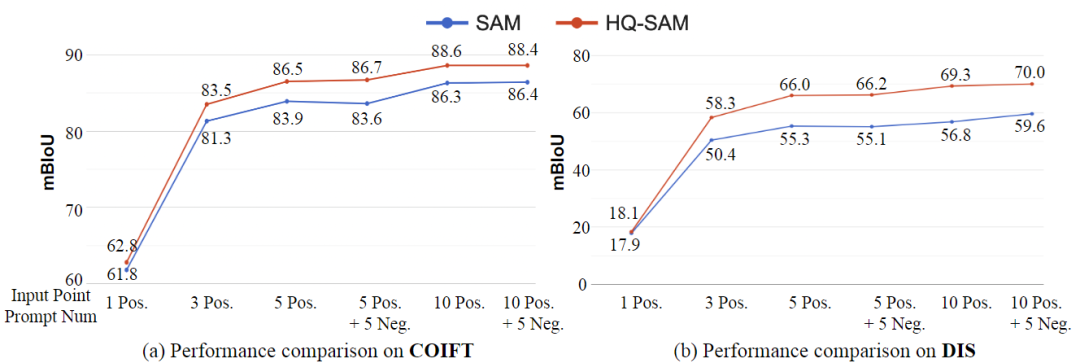
上图展示了在COIFT(零样本)和DIS验证集上,使用不同数量的输入点进行交互式分割的结果比较。结果显示,HQ-SAM在各种点的数量下始终优于SAM,并且在提示模糊度较小的情况下,相对改进更为明显。这表明HQ-SAM在交互式分割任务中对于不同数量的输入点都具有更好的性能,尤其在输入点较少且提示不明确的情况下,HQ-SAM的改进效果更加明显。

上表展示了在HQ-YTVIS基准测试集上进行零样本视频实例分割的比较结果。在该比较中,作者使用了在YTVIS数据集上预训练的基于Swin-L的Mask2Fromer模型作为边界框提示输入,并且重复使用了其对象关联预测。通过这样的设计,作者对于零样本视频实例分割方法进行了评估和比较。
结论
本文提出了HQ-SAM,这是第一个通过对原始SAM引入可忽略开销而实现高质量零样本分割的模型,探讨了如何在数据高效和计算经济的方式下利用和扩展类似SAM的基础分割模型。作者在HQ-SAM中引入了一个轻量级的高质量输出标记,用于替换原始SAM的输出标记,以实现高质量的掩码预测。在仅使用了44K个高度准确的掩码进行训练后,HQ-SAM显著提升了SAM的掩码预测质量,而SAM本身是在11亿个掩码上进行训练的。作者对包括图像和视频任务在内的7个分割基准进行了零样本转移评估,涵盖了各种对象和场景。
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称