最近需要将mmsegmentation训练好的模型部署到机器上,记录一下mmsegmentation训练好的模型转换成可部署的模型记录。
1.还是搭环境,搭环境过程当中遇到一些问题,mmdeploy官方推荐torch版本大于等于1.8。于是一顿操作猛如虎,一看战绩0-5。可能是强迫症犯了,一直用conda在windows上安装高版本的pytorch,结果就是failed。吐槽一下windows,淦。废话少说,搭环境。
conda create -n mmdeploy python=3.8 -y
conda activate mmdeploy
#windows上用conda 装高版本的pytorch老安装不完整,也不知道是个什么情况,这个地方我们用pip 的方式安装
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install onnx
#onnxruntime版本为1.8.1
pip install onnxruntime
2.下载mmdeploy源码,然后找到tools下的转换脚本,转换脚本的具体配置看个人需求自己选。输入尺寸可以是动态的也可以是静态的,
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import logging
import os
import os.path as osp
from mmdeploy.apis import (extract_model, get_predefined_partition_cfg,
torch2onnx)
from mmdeploy.utils import (get_ir_config, get_partition_config,
get_root_logger, load_config)
def parse_args():
parser = argparse.ArgumentParser(description='Export model to ONNX.')
#转换模型数据输入配置文件,这个地方将模型输入转成动态的,静态的输入配置大小也是可以更改的,建议改成动态的,省事。
parser.add_argument('--deploy_cfg', default='../configs/mmseg/segmentation_onnxruntime_dynamic.py', help='deploy config path')
#模型的具体配置文件路径
parser.add_argument('--model_cfg',
default='XXXXX', help='model config path')
#训练保存好的pth模型路径
parser.add_argument('--checkpoint', default='XXXXXXXX',help='model checkpoint path')
#转换测试用到的image 路径
parser.add_argument('--img', default='XXXXX',help='image used to convert model model')
parser.add_argument(
'--work-dir',
default='./work-dir',
help='Directory to save output files.')
parser.add_argument(
'--device', help='device used for conversion', default='cpu')
parser.add_argument(
'--log-level',
help='set log level',
default='INFO',
choices=list(logging._nameToLevel.keys()))
args = parser.parse_args()
return args
def main():
args = parse_args()
logger = get_root_logger(log_level=args.log_level)
logger.info(f'torch2onnx: \n\tmodel_cfg: {
args.model_cfg} '
f'\n\tdeploy_cfg: {
args.deploy_cfg}')
os.makedirs(args.work_dir, exist_ok=True)
# load deploy_cfg
deploy_cfg = load_config(args.deploy_cfg)[0]
save_file = get_ir_config(deploy_cfg)['save_file']
torch2onnx(
args.img,
args.work_dir,
save_file,
deploy_cfg=args.deploy_cfg,
model_cfg=args.model_cfg,
model_checkpoint=args.checkpoint,
device=args.device)
# partition model
partition_cfgs = get_partition_config(deploy_cfg)
if partition_cfgs is not None:
if 'partition_cfg' in partition_cfgs:
partition_cfgs = partition_cfgs.get('partition_cfg', None)
else:
assert 'type' in partition_cfgs
partition_cfgs = get_predefined_partition_cfg(
deploy_cfg, partition_cfgs['type'])
origin_ir_file = osp.join(args.work_dir, save_file)
for partition_cfg in partition_cfgs:
save_file = partition_cfg['save_file']
save_path = osp.join(args.work_dir, save_file)
start = partition_cfg['start']
end = partition_cfg['end']
dynamic_axes = partition_cfg.get('dynamic_axes', None)
extract_model(
origin_ir_file,
start,
end,
dynamic_axes=dynamic_axes,
save_file=save_path)
logger.info(f'torch2onnx finished. Results saved to {
args.work_dir}.pth2onnx success')
if __name__ == '__main__':
main()
3.转换成功后会在tools下的work-dir看到转换后的模型,查看onnx模型的输入输出工具
后期有时间学一下怎么部署自己的模型。
4.对转换后的onnx进行量化,量化实质就是将模型中的Folat映射到8bit量化空间。量化脚本如下:
# Dynamic quantization
import onnx
from onnxruntime.quantization import quantize_dynamic, QuantType
model_fp32 = 'tmp.onnx'
model_quant = 'result1.onnx'
quantized_model = quantize_dynamic(model_fp32, model_quant, weight_type=QuantType.QUInt8)
# QAT quantization QAT量化
import onnx
from onnxruntime.quantization import quantize_qat, QuantType
model_fp32 = 'tmp.onnx'
model_quant = 'result2.onnx'
quantized_model = quantize_qat(model_fp32, model_quant)
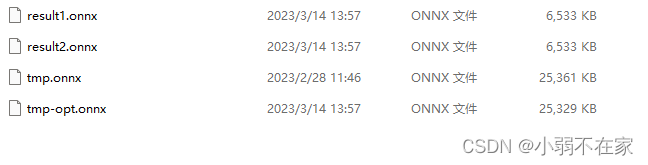
量化后的模型参数量减少四分之三,部署后精度基本保持不变。