文章目录
1 量化介绍
1.1 量化概述
ONNXRuntime 中的量化是指 ONNX 模型的 8 bit 线性量化。
在量化过程中,浮点实数值映射到 8 bit 量化空间,其形式为:
VAL f p 32 = Scale ∗ ( VAL q u a n t i z e d − Zero p o i n t ) \text{VAL}_{fp32}=\text{Scale} * (\text{VAL}_{quantized} - \text{Zero}_{point}) VALfp32=Scale∗(VALquantized−Zeropoint)
Scale 是一个正实数,用于将浮点数映射到量化空间,计算方法如下:
-
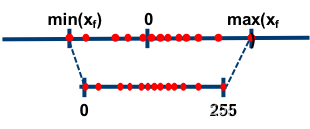
对于非对称量化:
scale = (data_range_max - data_range_min) / (quantization_range_max - quantization_range_min)
使用一个映射公式将输入数据映射到[0,255]的范围内
-
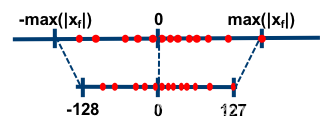
对于对称量化:
scale = abs(data_range_max, data_range_min) * 2 / (quantization_range_max - quantization_range_min)
对称量化即使用一个映射公式将输入数据映射到 [-128,127] 的范围内:
-
Zero_point 表示量化空间中的零。
重要的是,浮点零值在量化空间中可以精确地表示。这是因为许多 CNN 都使用零填充。
如果在量化后无法唯一地表示 0,则会导致精度误差。import sys import time import numpy as np # 随机生成一些浮点数据(Float32) data_float32 = np.random.randn(10).astype('float32') # 量化上下限(UInt8) Qmin = 0 Qmax = 255 # 计算缩放因子(Scale) S = (data_float32.max() - data_float32.min()) / (Qmax - Qmin) # 计算零点(Zero Point) Z = Qmax - data_float32.max() / S # 将浮点数据(Float32)量化为定点数据(UInt8) data_uint8 = np.round(data_float32 / S + Z).astype('uint8') # 将定点数据(UInt8)反量化为浮点数据(Float32) data_float32_ = ((data_uint8 - Z) * S).astype('float32') # 使用均方误差计算差异 mse = ((data_float32-data_float32_)**2).mean() print("原始数据:", data_float32) print("反量化后数据:", data_float32_) print("量化后数据:", data_uint8) print("原始数据和反量化后数据的均方误差:", mse) """ 原始数据: [-0.47069794 0.8608386 -0.947035 -1.0697421 0.10035864 0.0013437 0.6782814 0.7141242 -0.09668107 0.4391506 ] 反量化后数据: [-0.4716406 0.8608386 -0.94860756 -1.069742 0.10374816 -0.00224451 0.6791369 0.7169914 -0.09309536 0.43686795] 量化后数据: [ 79 255 16 0 155 141 231 236 129 199] 原始数据和反量化后数据的均方误差: 5.4746083e-06 """
1.2 量化方式
ONNXRuntime 支持两种模型量化方式:
- 动态量化:
- 对于动态量化,缩放因子(Scale)和零点(Zero Point)是在推理时计算的,并且特定用于每次激活
- 因此它们更准确,但引入了额外的计算开销
- 静态量化:
- 对于静态量化,它们使用校准数据集离线计算
- 所有激活都具有相同的缩放因子(Scale)和零点(Zero Point)
- 方法选择:
- 通常,建议对 RNN 和基于 Transformer 的模型使用动态量化,对 CNN 模型使用静态量化
1.3 量化类型
- ONNXRuntime 支持两种量化数据类型:
- Int8 (QuantType.QInt8): 有符号 8 bit 整型
- UInt8 (QuantType.QUInt8): 无符号 8 bit 整型
- 数据类型选择:
- 结合激活和权重,数据格式可以是(activation:uint8,weight:uint8),(activation:uint8,weight:int8)等。
- 这里使用 U8U8 作为 (activation:uint8, weight:uint8) 的简写,U8S8 作为 (activation:uint8, weight:int8) 和 S8U8, S8S8 作为其他两种格式的简写。
- CPU 上的 OnnxRuntime Quantization 可以运行 U8U8,U8S8 和 S8S8。
- 具有 QDQ 格式的 S8S8 是性能和准确性的默认设置,它应该是第一选择。
- 只有在精度下降很多的情况下,才能尝试U8U8。
- 请注意,具有 QOperator 格式的 S8S8 在 x86-64 CPU 上会很慢,通常应避免使用。
- GPU 上的 OnnxRuntime Quantization 仅支持 S8S8 格式。
- 在具有 AVX2 和 AVX512 扩展的 x86-64 计算机上,OnnxRuntime 使用 U8S8 的 VPMADDUBSW 指令来提高性能,但此指令会遇到饱和问题。
- 一般来说,对于最终结果来说,这不是一个大问题。
- 如果某些模型的精度大幅下降,则可能是由饱和度引起的。
- 在这种情况下,您可以尝试 reduce_range 或 U8U8 格式,没有饱和度问题。
- 在其他 CPU 架构(使用 VNNI 和 ARM 的 x64)上没有这样的问题。
1.4 量化格式
- ONNXRuntime 支持两种量化模型格式:
- Tensor Oriented, aka Quantize and DeQuantize (QuantFormat.QDQ):
- 该格式使用 DQ (Q (tensor)) 来模拟量化和去量化过程,并且 QuantizeLinear 和DeQuantizeLinear 算子也携带量化参数
- Operator Oriented (QuantFormat.QOperator):
- 所有量化运算符都有自己的 ONNX 定义,如QLinearConv、MatMulInteger 等
- Tensor Oriented, aka Quantize and DeQuantize (QuantFormat.QDQ):
2. 量化实践
2.1 安装依赖
- 转换 Paddle 模型至 ONNX 格式需要 Paddle2ONNX 模块
- 量化 ONNX 模型需要依赖 ONNX 和 ONNXRuntime 两个模块
- 使用如下代码进行安装:
pip install onnxruntime onnx paddle2onnx
2.2 模型准备
- 这里仍然使用 PaddlClas 提供的 MobileNet V1 预训练模型
- 在开始模型量化之前需要先将 Paddle 格式的模型转换为 ONNX 格式
- 这里使用 Paddle2ONNX 的命令行命令进行模型格式转换
- 具体的下载和转换命令如下:
# 下载模型文件 wget -P models https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/inference/MobileNetV1_infer.tar # 解压缩模型文件 !cd models && tar -xf MobileNetV1_infer.tar # 模型转换 !paddle2onnx \ --model_dir models/MobileNetV1_infer \ --model_filename inference.pdmodel \ --params_filename inference.pdiparams \ --save_file models/MobileNetV1_infer.onnx \ --opset_version 12
2.3 动态量化
- 动态量化只转换模型的参数类型,无需额外数据,所以非常简单,仅将模型中特定算子的权重从浮点类型映射成整数类型。
- 只需要调用 ONNXRuntime 的 quantize_dynamic 接口即可实现模型动态量化
- 具体的量化代码如下:
from onnxruntime.quantization import QuantType, quantize_dynamic # 模型路径 model_fp32 = 'models/MobileNetV1_infer.onnx' model_quant_dynamic = 'models/MobileNetV1_infer_quant_dynamic.onnx' # 动态量化 quantize_dynamic( model_input=model_fp32, # 输入模型 model_output=model_quant_dynamic, # 输出模型 weight_type=QuantType.QUInt8, # 参数类型 Int8 / UInt8 optimize_model=True # 是否优化模型 )
2.4 静态量化
其他量化方法:https://www.cnblogs.com/hyz-695729754/p/14346177.html
- 因为需要额外的数据用于校准模型,所以相比动态量化,静态量化更加复杂一些。使用少量无标签校准数据,采用KL散度等方法计算量化比例因子。
- 需要先编写一个校准数据的读取器,然后再调用 ONNXRuntime 的 quantize_static 接口进行静态量化
- 具体的量化代码如下:
import os
import numpy as np
import time
from PIL import Image
import onnxruntime
from onnxruntime.quantization import quantize_static, CalibrationDataReader, QuantFormat, QuantType
quanti_infos = {
"ASL": {
"model_fp32": "./weight/tooNet_simple.onnx",
"model_u8": "./weight/t00Net_simple_u8.onnx",
"img_dir": "./VOCdevkit/VOC2012/JPEGImages",
"input_shape": (1, 3, 448, 448),
},
"CSSS": {
"model_fp32": "./kaka_simple.onnx",
"model_u8": "./kaka_simple_u8.onnx",
"img_dir": "./dataset/test",
"input_shape": (1, 3, 60, 160),
}
}
class DataReader(CalibrationDataReader):
def __init__(self, calibration_image_folder, augmented_model_path=None):
self.image_folder = calibration_image_folder
self.augmented_model_path = augmented_model_path
self.preprocess_flag = True
self.enum_data_dicts = []
self.datasize = 0
def get_next(self):
if self.preprocess_flag:
self.preprocess_flag = False
session = onnxruntime.InferenceSession(self.augmented_model_path, None)
(_, _, height, width) = session.get_inputs()[0].shape
nchw_data_list = proprocess_func(self.image_folder, height, width)
input_name = session.get_inputs()[0].name
self.datasize = len(nchw_data_list)
self.enum_data_dicts = iter([{
input_name: nhwc_data} for nhwc_data in nchw_data_list])
return next(self.enum_data_dicts, None)
def proprocess_func(images_folder, height, width, size_limit=32):
batch_filenames = os.listdir(images_folder)
unconcatenated_batch_data = []
for image_name in batch_filenames[:size_limit]:
print("image_name=>", images_folder + "/" + image_name)
img_rgb = Image.open(images_folder + "/" + image_name)
img_pre = np.array(img_rgb) / 255.0
# img_pre = resize_img_asl(np.array(img_rgb)) / 255.0
img_pre = np.transpose(img_pre, (2, 0, 1))
input_data = img_pre.reshape((1, 3, height, width)).astype(np.float32)
unconcatenated_batch_data.append(input_data)
return np.concatenate(np.expand_dims(unconcatenated_batch_data, axis=0), axis=0)
def resize_img_asl(image, target_size=(448, 448)):
"""
:param image: 原图(np.ndarray)
:param target_size:(resize尺寸:效果等比例缩放居中)
:return:
"""
height, width = image.shape[:2]
scale_xy = min(target_size[0] / height, target_size[1] / width)
M = np.array([[scale_xy, 0, -scale_xy * width * 0.5 + target_size[1] * 0.5],
[0, scale_xy, -scale_xy * height * 0.5 + target_size[0] * 0.5]])
return cv2.warpAffine(image, M, target_size, None, borderValue=(144, 144, 144))
def benchmark(model_path):
"""
用于测试速度
:param model_path:
:return:
"""
session = onnxruntime.InferenceSession(model_path)
input_name = session.get_inputs()[0].name
total = 0.0
runs = 10
input_data = np.zeros((1, 3, 60, 160), np.float32) # 随便输入一个假数据,注意shape要与模型一致,我这里是灰度图输入所以(1,1),三通道图为(1,3)
_ = session.run([], {
input_name: input_data})
for i in range(runs):
start = time.perf_counter()
_ = session.run([], {
input_name: input_data})
end = (time.perf_counter() - start) * 1000
total += end
print(f"{
end:.2f}ms")
total /= runs
print(f"Avg: {
total:.2f}ms")
def main():
input_model_path = quanti_infos["CSSS"]["model_fp32"] # 输入onnx模型 227.6M
output_model_path = quanti_infos["CSSS"]["model_u8"] # 输出模型名 57.2M
calibration_dataset_path = quanti_infos["CSSS"]["img_dir"] # 校准数据集图像地址
dr = DataReader(calibration_dataset_path, input_model_path)
# 开始量化
quantize_static(input_model_path,
output_model_path,
dr,
quant_format=QuantFormat.QDQ,
per_channel=False,
weight_type=QuantType.QInt8)
print("量化完成")
print("float32测试") # Avg: 313.30ms
benchmark(input_model_path)
print("int8测试") # Avg: 217.81ms
benchmark(output_model_path)
if __name__ == "__main__":
main()
3. 对比测试
3.1 文件大小
-
量化前后的模型文件大小如下表所示:
模型 大小 原始模型 16.3MB 优化模型 16.1MB 动态量化 4.1MB 静态量化 4.1MB -
可以看到量化后的模型文件大小约为原始模型的 1/4
3.2 运行速度
-
这里采用多次前向计算来对比量化前后模型的运行速度
-
可以看出,动态量化模型在运行速度上没有优势
-
而静态量化模型的运行速度在 AIStudio 的 CPU 环境中表现差不多,甚至会有一些下降
-
如果在一些专门为 Int8 优化的设备上,量化模型的表现将会更加优秀
import os import time import numpy as np from PIL import Image from paddle.vision.transforms import Compose, Resize, CenterCrop, Normalize from onnxruntime import InferenceSession, get_available_providers # 模型基类 class Session: def __init__(self, model_onnx): self.session = InferenceSession(model_onnx, providers=get_available_providers()) def __call__(self, x): outputs = self.session.run([], { 'inputs': x}) return outputs def benchmark(self, x, warmup=5, repeat=10): for i in range(warmup): self(x) start = time.time() for i in range(repeat): self(x) return time.time() - start # 图像预处理 mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] val_transforms = Compose( [ Resize(256, interpolation="bilinear"), CenterCrop(224), lambda x: np.asarray(x, dtype='float32').transpose(2, 0, 1) / 255.0, Normalize(mean, std), lambda x: x[None, ...] ] ) # 加载模型 dynamic = Session('models/MobileNetV1_infer_quant_dynamic.onnx') static = Session('models/MobileNetV1_infer_quant_static.onnx') session = Session('models/MobileNetV1_infer.onnx') # 加载测试数据 img_dir = 'data/data143470' imgs = np.concatenate([val_transforms(Image.open(os.path.join(img_dir, img)).convert('RGB')) for img in os.listdir(img_dir)], 0) # 速度测试 warmup = 5 repeat = 20 time_session = session.benchmark(imgs, warmup, repeat) time_dynamic = dynamic.benchmark(imgs, warmup, repeat) time_static = static.benchmark(imgs, warmup, repeat) # 打印结果 print('原始模型重复 %d 次前向计算耗时:%f s' % (repeat, time_session)) print('动态量化模型重复 %d 次前向计算耗时:%f s' % (repeat, time_dynamic)) print('静态量化模型重复 %d 次前向计算耗时:%f s' % (repeat, time_static)) 原始模型重复 20 次前向计算耗时:3.098398 s 动态量化模型重复 20 次前向计算耗时:28.396264 s 静态量化模型重复 20 次前向计算耗时:2.297622 s
3.3 模型精度
- 由于 ImageNet 数据集过大,这里不太好演示
- 所以就简单对量化前后模型输出的结果进行对比
- 可以看到基本上精度表现上会有些许下降
outputs_dynamic = dynamic(imgs)[0] outputs_static = static(imgs)[0] outputs_session = session(imgs)[0] argmax_dynamic = outputs_dynamic.argmax(-1) argmax_static = outputs_static.argmax(-1) argmax_session = outputs_session.argmax(-1) MSE = lambda inputs, labels: ((inputs-labels)**2).mean() mse_dynamic = MSE(outputs_dynamic, outputs_session) mse_static = MSE(outputs_static, outputs_session) print('原始模型结果:', argmax_session) print('动态量化模型结果:', argmax_dynamic) print('静态量化模型结果:', argmax_static) print('动态量化 MSE:', mse_dynamic) print('静态量化 MSE:', mse_static) 原始模型结果: [308 943] 动态量化模型结果: [308 943] 静态量化模型结果: [308 943] 动态量化 MSE: 1.2413246e-05 静态量化 MSE: 8.649646e-05