题目:
请实现函数ComplexListNode* Clone(ComplexListNode * pHead),复制一个复杂链表。在复杂链表中,每个结点除了有一个m_pNext指针指向下一个结点外,还有一个m_pSibling指向链表中的任意结点或者NULL。结点的C++定义如下:
struct ComplexListNode{
int m_nValue;
ComplexListNode* m_pNext;
ComplexListNode* m_pSibling;
};

上图是一个含有5个结点的复杂链表。图中实线箭头表示m_pNext指针,虚线箭头表示m_pSibling指针。为了简单起见,指向NULL的指针没有画出。
public class ComplexListNode {
public int m_nValue;
ComplexListNode m_pNext;
ComplexListNode m_pSibling;
public ComplexListNode() {
}
public ComplexListNode(int m_nValue) {
super();
this.m_nValue = m_nValue;
}
}
第一思路:
把复杂链表的复制分为两步:第一步是复制原始链表上的每一个结点,并用m_pNext连接起来;第二步是设置m_pSibling指向结点S,由于S的位置在链表中可能在N的前面也可能在N的后面,所以要定位S的位置需要从原始链表的头结点开始找。如果从原始链表的头结点开始沿着m_pNext经过s步找到结点S,那么在复制链表上结点N'的m_pSibling(记为S')离复制链表的头结点的距离也是沿着m_pNext指针s步。用这种办法我们就可以为复制链表上的每个结点设置m_pSibling指针。对于每一个含有n个结点的链表,由于定位每个结点的m_pSibling都需要从链表头结点开始经过O(n)步才能找到,因此这种方法的总时间复杂度是O(n^2)。
优化思路:
上面的时间为主要花在定位结点的m_pSibling上面,所以我们能优化的地方也只有这个地方。我们还是分为两步:第一步仍然是复制原始链表上的每个结点N创建N',然后把这些创建出来的结点用m_pNext链接起来。同时我们把<N, N'>的配对信息放到一个哈希表中。第二步还是设置复制链表上的每个结点的m_pSibling。如果在原始链表中结点N的m_pSibling指向结点S,那么在复制链表中,对应的N'应该指向S'。由于有了哈希表,我们可以在O(1)的时间根据S找到S’。这种是以O(n)的空间换来了O(n)的时间复杂度。
代码实现:
public ComplexListNode clone(ComplexListNode pHead){
if(pHead == null){
return null;
}
HashMap<ComplexListNode, ComplexListNode> map = new HashMap<ComplexListNode, ComplexListNode>();
ComplexListNode pClonedHead = new ComplexListNode(pHead.m_nValue); //复制链表的头结点
ComplexListNode pNode = pHead, pClonedNode = pClonedHead;
map.put(pNode, pClonedNode);
//第一步,hashMap保存,原链表节点映射复制链表节点
while(pNode.m_pNext != null){
pClonedNode.m_pNext = new ComplexListNode(pNode.m_pNext.m_nValue);
pNode = pNode.m_pNext;
pClonedNode = pClonedNode.m_pNext;
map.put(pNode, pClonedNode);
}
//第二步:找到对应的m_pSibling
pNode = pHead;
pClonedNode = pClonedHead;
while(pClonedNode!=null){
pClonedNode.m_pSibling = map.get(pNode.m_pSibling);
pNode = pNode.m_pNext;
pClonedNode = pClonedNode.m_pNext;
}
return pClonedHead;
}
最优思路:
不用O(n)的空间复杂度来实现O(n)的时间效率。
第一步:让仍然是根据原始链表的每个结点N创建对应的N'。不过我们把N’链接在N的后面。
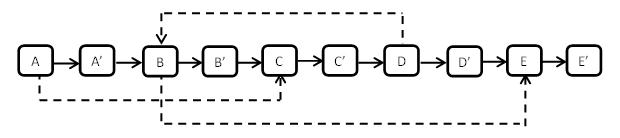
第二步:设置复制出来的结点的m_pSibling。原始链表上的A的m_pSibling指向结点C,那么其对应复制出来的A’是A的m_pNext指向的结点,同样C’也是C的m_pNext指向的结点。即A' = A.next,A'.m_pSibling = A.m_pSibling.next;故像这样就可以把每个结点的m_pSibling设置完毕。

第三步:将这个长链表拆分成两个链表:把奇数位置的结点用m_pNext链接起来就是原始链表,把偶数位置的结点用m_pNext链接起来就是复制出来的链表。

代码实现:
//根据原始结点A在其后面创建A'。
public void cloneNodes(ComplexListNode pHead){
ComplexListNode pNode = pHead;
while(pNode != null){
//创建pCloned结点即A'结点使其指向原始链表中A结点的下一结点B,不过A'的m_pSibling设置为null
ComplexListNode pCloned = new ComplexListNode();
pCloned.m_nValue = pNode.m_nValue;
pCloned.m_pNext = pNode.m_pNext;
pCloned.m_pSibling = null;
//将A结点指向A’结点
pNode.m_pNext = pCloned;
//使pNode指向A的下一结点B并以此循环修改(此时中间已将克隆结点A‘插入了原始列表)
pNode = pCloned.m_pNext;
}
}
//设置每个结点的m_pSibling(注:m_pSibling为空结点不做修改)
public void connectSiblingNodes(ComplexListNode pHead){
ComplexListNode pNode = pHead;
while(pNode!=null){
ComplexListNode pCloned = pNode.m_pNext;
if(pNode.m_pSibling!=null){
pCloned.m_pSibling = pNode.m_pSibling.m_pNext;
}
pNode = pCloned.m_pNext;
}
}
//拆分链表
public ComplexListNode reconnectNodes(ComplexListNode pHead){
ComplexListNode pNode = pHead;
ComplexListNode pClonedHead = null;
ComplexListNode pClonedNode = null;
if(pNode!=null){
pClonedHead = pClonedNode = pNode.m_pNext;
pNode.m_pNext = pClonedNode.m_pNext;
pNode = pNode.m_pNext;
}
while(pNode!=null){
pClonedNode.m_pNext = pNode.m_pNext;
pClonedNode = pClonedNode.m_pNext;
pNode.m_pNext = pClonedNode.m_pNext;
pNode = pNode.m_pNext;
}
return pClonedHead;
}
//上面的三步合起来即为复杂链表的复制
public ComplexListNode clone(ComplexListNode pHead){
cloneNodes(pHead);
connectSiblingNodes(pHead);
return reconnectNodes(pHead);
}

小结:
对链表的考查,面对复杂问题时需要学会拆分,将复杂的大问题拆分成一个个小问题,这样大而化小的解决问题方法也是一种经典的解决问题方法。有时候我们还需要学会分析时间效率和空间的效率。力争在最小的空间复杂度和最小的时间复杂度解决问题才是王道。