近期评论区有小伙伴需要蚁群算法ACO优化VMD的,所以打算写一篇。
同样以西储大学数据集为例,选用105.mat中的X105_BA_time.mat数据。
首先进行VMD分解,采用蚁群优化算法(ACO)对VMD的两个关键参数(惩罚因子α和模态分解数K)进行优化,以最小包络熵为适应度值。
老规矩,先上结果图:

实验过程中,会实时显示每次寻优后的最小包络熵值和VMD对应的两个最佳参数。本次寻优共30次(自己可以随意更改寻优次数)。
可以看到寻优30次后,最小包络熵为7.3589,对应两个vmd的最佳参数为657,5,其中惩罚因子为657,模态分解数为5。
收敛曲线如下所示:
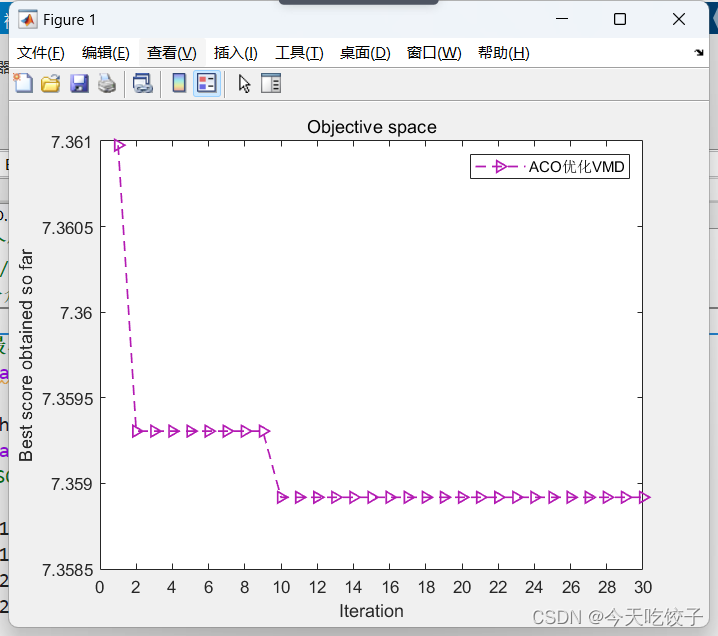
代码:
%%
%% 以最小包络熵为目标函数,采用ACO算法优化VMD,求取VMD最佳的两个参数
clear all
clc
addpath(genpath(pwd))
load 105.mat
D=2; % 优化变量数目
popmin1 = 100; %惩罚因子
popmax1 = 2500;
popmin2 = 3; %模态分解K值
popmax2 = 10;
T=30; % 最大迭代数目
N=20; % 种群规模
y=@Cost;
da = X105_DE_time(1:2048); %这里选取105的DE数据
[AcoBest_pos,AcoBest_score,ACO_curve] = ACO(y,popmin1,popmax1,popmin2,popmax2,N,T,da);
%画适应度函数图
figure
plot(1:T,ACO_curve,'Color',[0.7 0.1 0.7],'Marker','>','LineStyle','--','linewidth',1);
title('Objective space')
xlabel('Iteration');
set(gca,'xtick',0:2:T);
ylabel('Best score obtained so far');
legend('ACO优化VMD')
display(['The best solution obtained by ACO is : ', num2str(round(AcoBest_pos))]); %输出最佳位置
display(['The best optimal value of the objective funciton found by ACO is : ', num2str(AcoBest_score)]); %输出最佳适应度值
完整代码获取:下方卡片回复关键词:ACOVMD
觉着不错的给博主留个小赞吧!您的一个小赞就是博主更新的动力!谢谢!