在强化学习rl中对于state value function和state action value function的理解
在rl中,经常会提及两个基础的概念:
state (V) and action(Q)
或者也可以按照所刻画的内容称为:
V(s), Q(s, a)
在这里进行一定的区分和理解:
-
state value function:
英文解释可以理解为:
It is the expected return (cumulative reward)starting from the state s following policy, π.
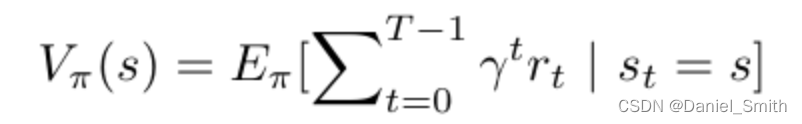
我们可以将带有折扣因子的gamma的求和项写成累计g:
γ is the discount factor that determines how far future rewards are taken into account in the return
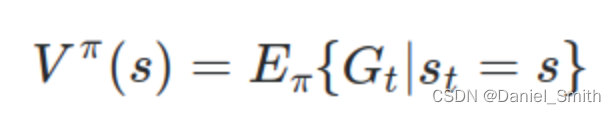
这样便是v(s)的结果表示值 -
action value function:
The expected return(cumulative reward) starts from state s, following policy π, taking action a.
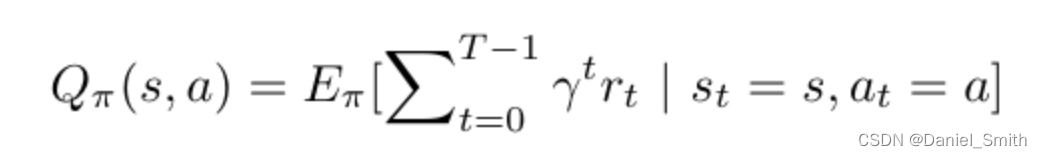
可以看到,其中最不同的一点便是,在q function中,不仅是基于当前状态,并且还要基于某一个采取的action进行未来可能回报value的衡量
同理 将求和项可以表示为:
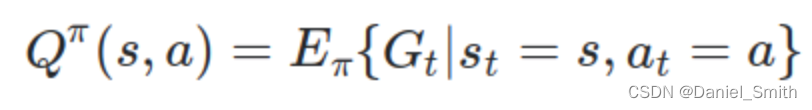
-
这时候我们可以考虑一下q function与v function之间是否存在某种关系?
我们其实可以分两种方式:
a.用v表示q:
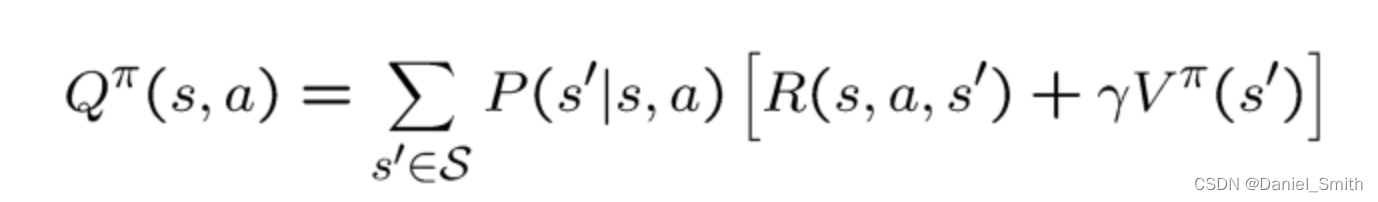
P 是一个 state-transition-matrix(状态转移矩阵)输出probability of reaching the next state s’ 从 state s
R is the immediate reward, and V is the state value of the next state s’
b.用q表示v:
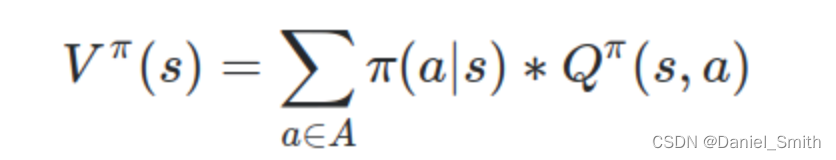
value function 是总计的统计值:total sum of probability of choosing action or policy 乘以 the action-value of taking each action
最后可以看一下这个图片从而更好的理解两者之间的关系: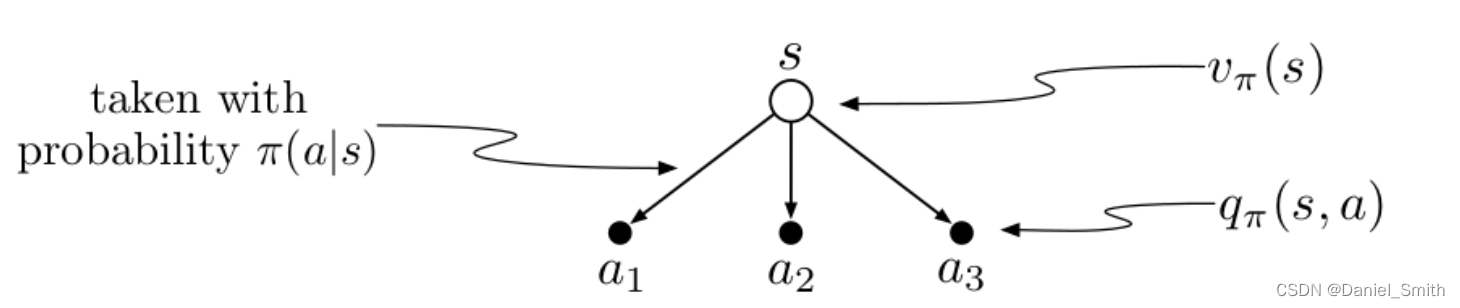
当然也有一些其他的理解,不过都比较准确:

在应用advantage function方面,这个工作便是例子:
Dueling Network Architectures for Deep Reinforcement Learning
另外一种理解:

基本上便是一致的表述,即为q function更加突出对action的刻画,也正是因为这个原因,他更佳适合于action space很大或者state action pair很难收集的情况!
respect!