TensorRT部署神经网络
大佬的讲解记录一下

基础知识
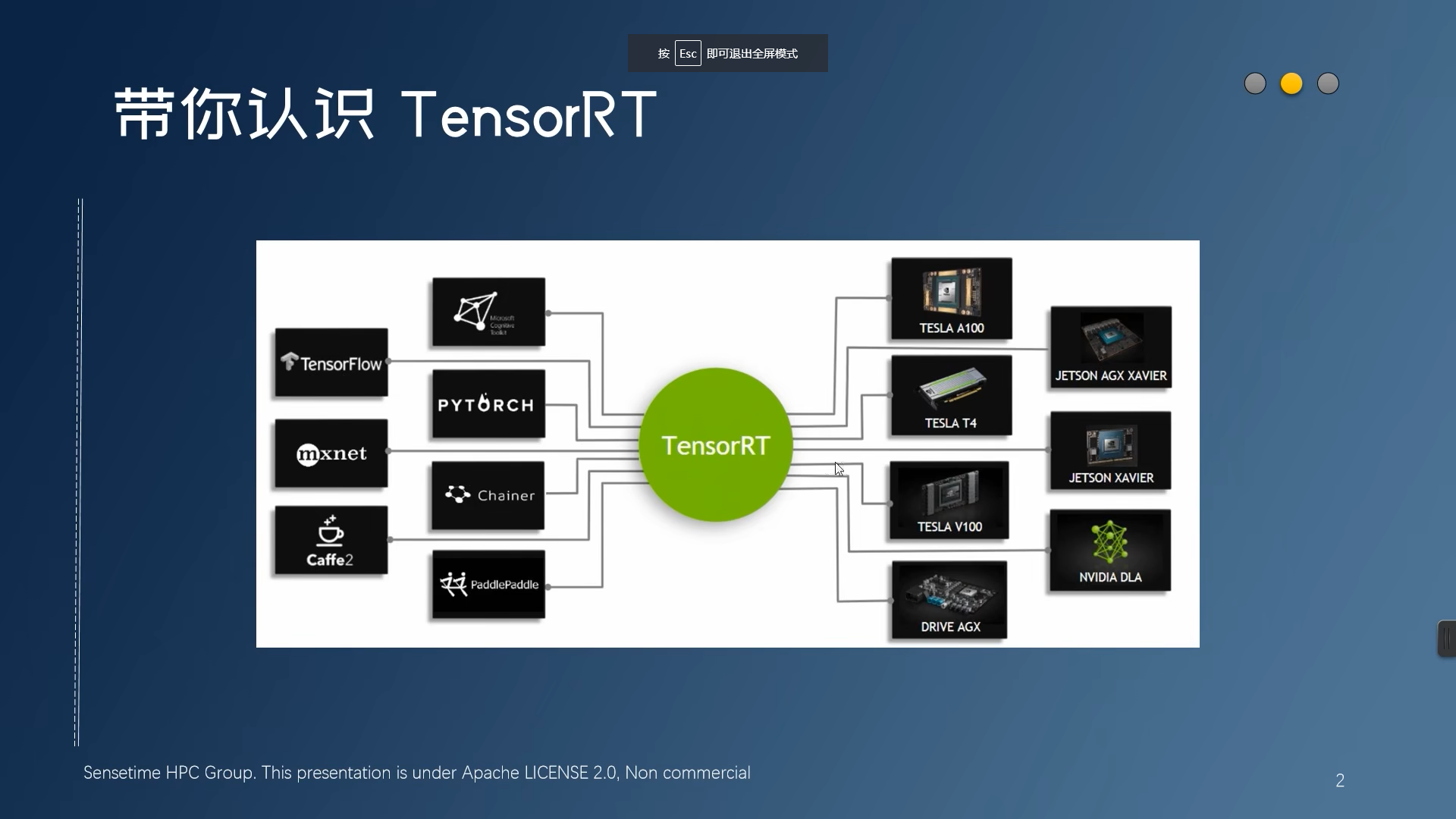
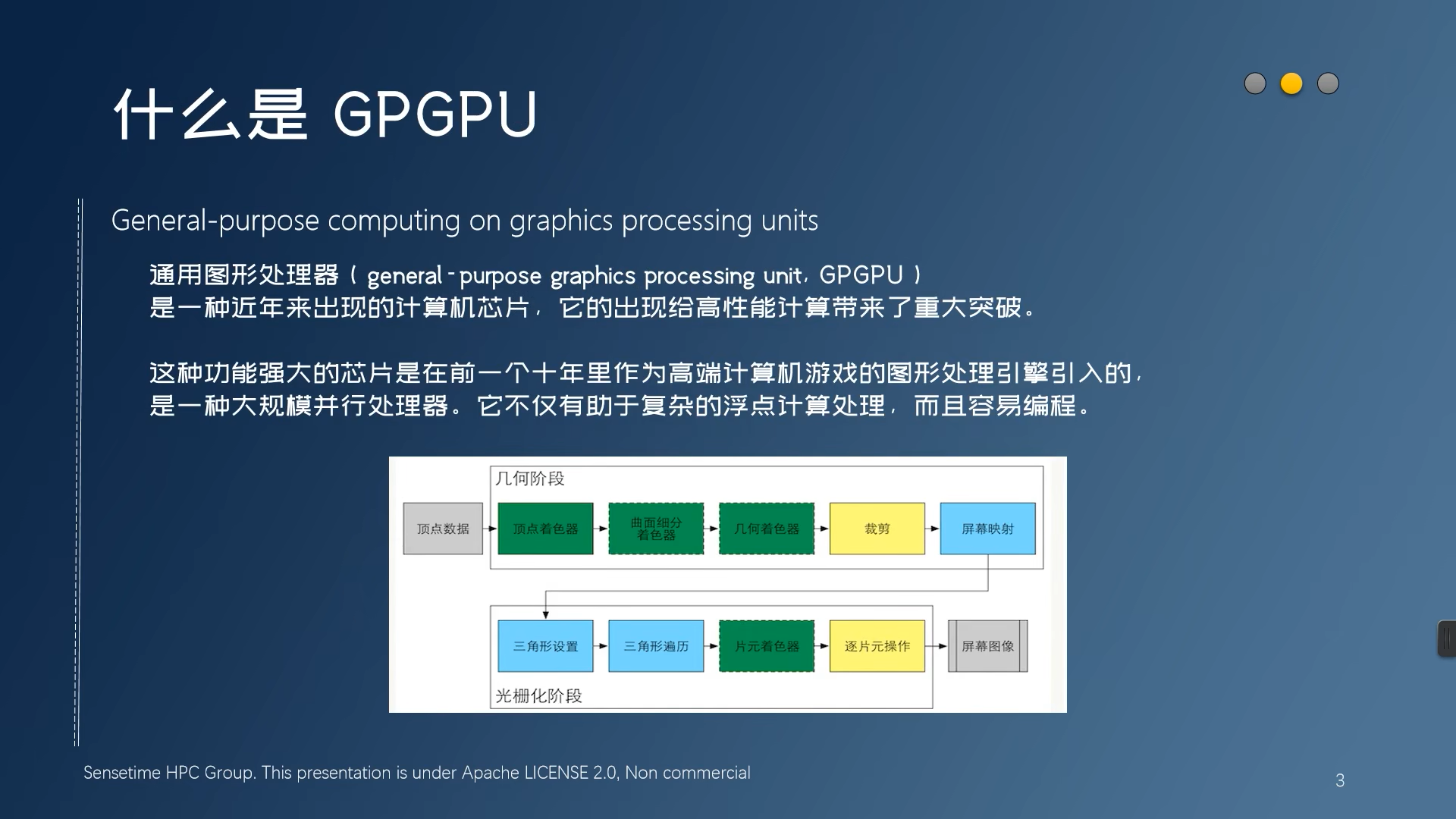

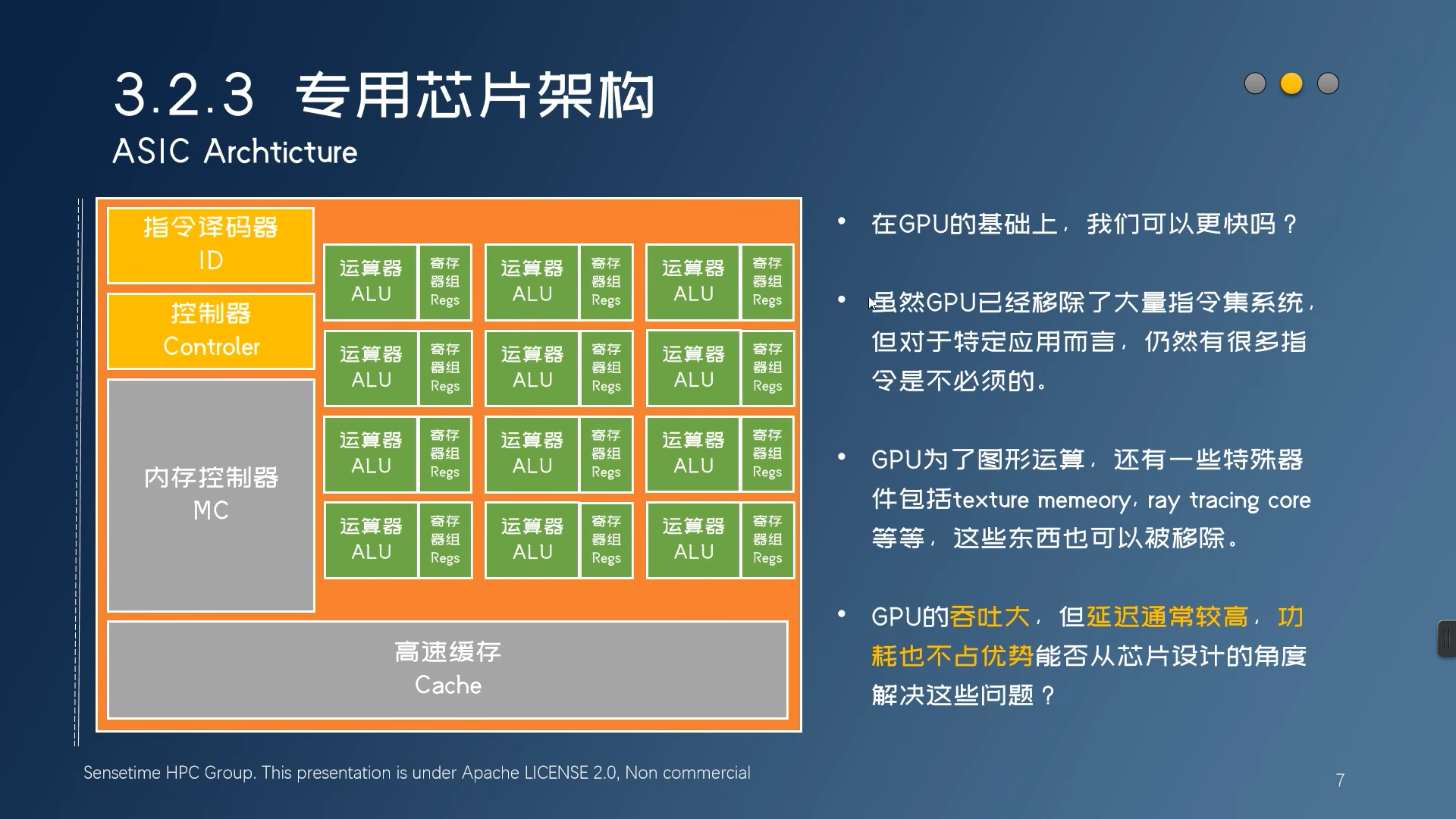




TensorRT使用例子
TensorRT加速模型
示例代码
# ---------------------------------------------------------------
# 这个脚本向你展示了如何使用 torch2trt 加速 pytorch 推理
# 截止目前为止 torch2trt 的适配能力有限,不要尝试运行特别奇怪的模型
# 你可以把模型分块来绕开那些不支持的算子。
# 使用之前你必须先装好 tensorRT
# https://github.com/NVIDIA-AI-IOT/torch2trt
# ---------------------------------------------------------------
import torch
import torch.profiler
import torch.utils.data
import torchvision
from torch2trt import torch2trt
from tqdm import tqdm
# load model
SAMPLES = [torch.zeros(1, 3, 224, 224) for _ in range(1024)]
MODEL = torchvision.models.resnet18()
FP16_MODE = True
# Model has to be eval mode, and deploy to cuda.
MODEL.eval()
MODEL.cuda()
# benckmark with pytorch
for sample in tqdm(SAMPLES, desc='Torch Executing'):
MODEL.forward(sample.cuda())
# convert torch.nn.module with tensorrt
# 在转换过后,你模型中的执行函数将会被 trt 替换,同时进行图融合
model_trt = torch2trt(MODEL, [sample.cuda()], fp16_mode=FP16_MODE)
for sample in tqdm(SAMPLES, desc='TRT Executing'):
model_trt.forward(sample.cuda())
print(isinstance(model_trt, torch.nn.Module))
# benchmark with your model.
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=1,
active=7),
# on_trace_ready=trace_handler
on_trace_ready=torch.profiler.tensorboard_trace_handler('log')
# used when outputting for tensorboard
) as p:
for iter in range(10):
model_trt.forward(sample.cuda())
# send a signal to the profiler that the next iteration has started
p.step()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=1,
active=7),
# on_trace_ready=trace_handler
on_trace_ready=torch.profiler.tensorboard_trace_handler('log')
# used when outputting for tensorboard
) as p:
for iter in range(10):
MODEL.forward(sample.cuda())
# send a signal to the profiler that the next iteration has started
p.step()
优化前
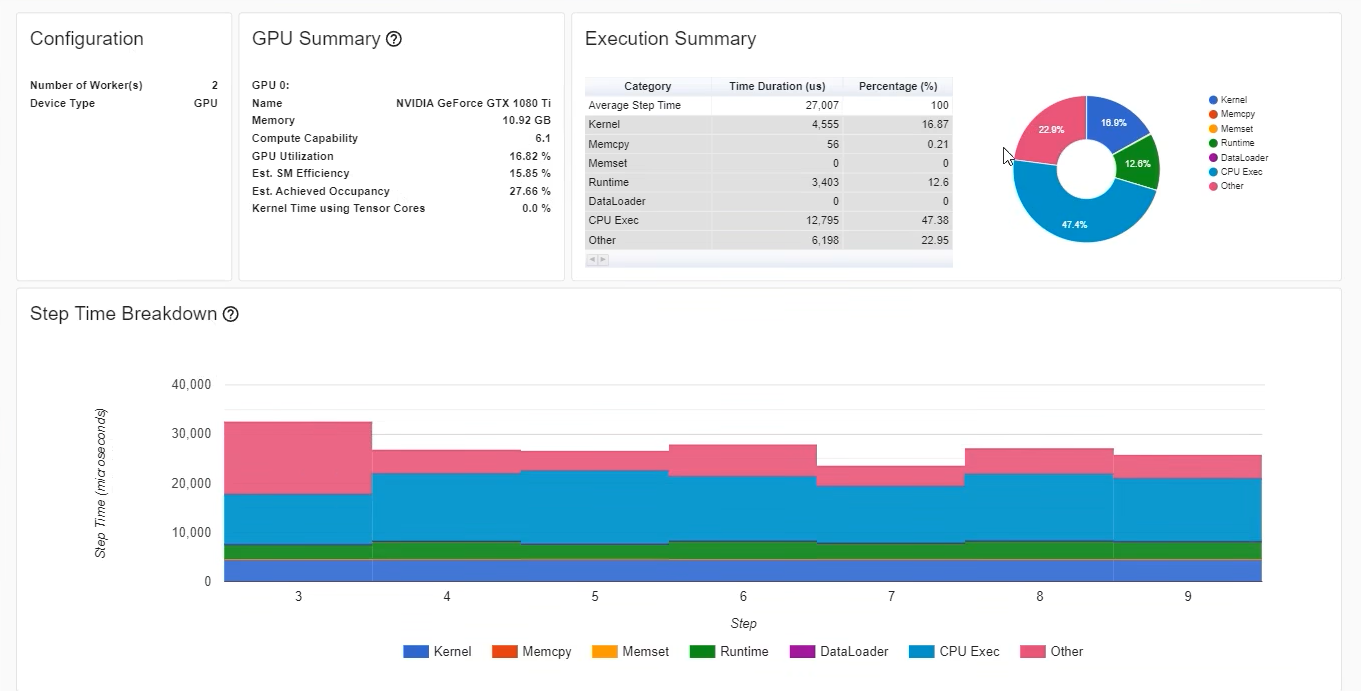
优化后
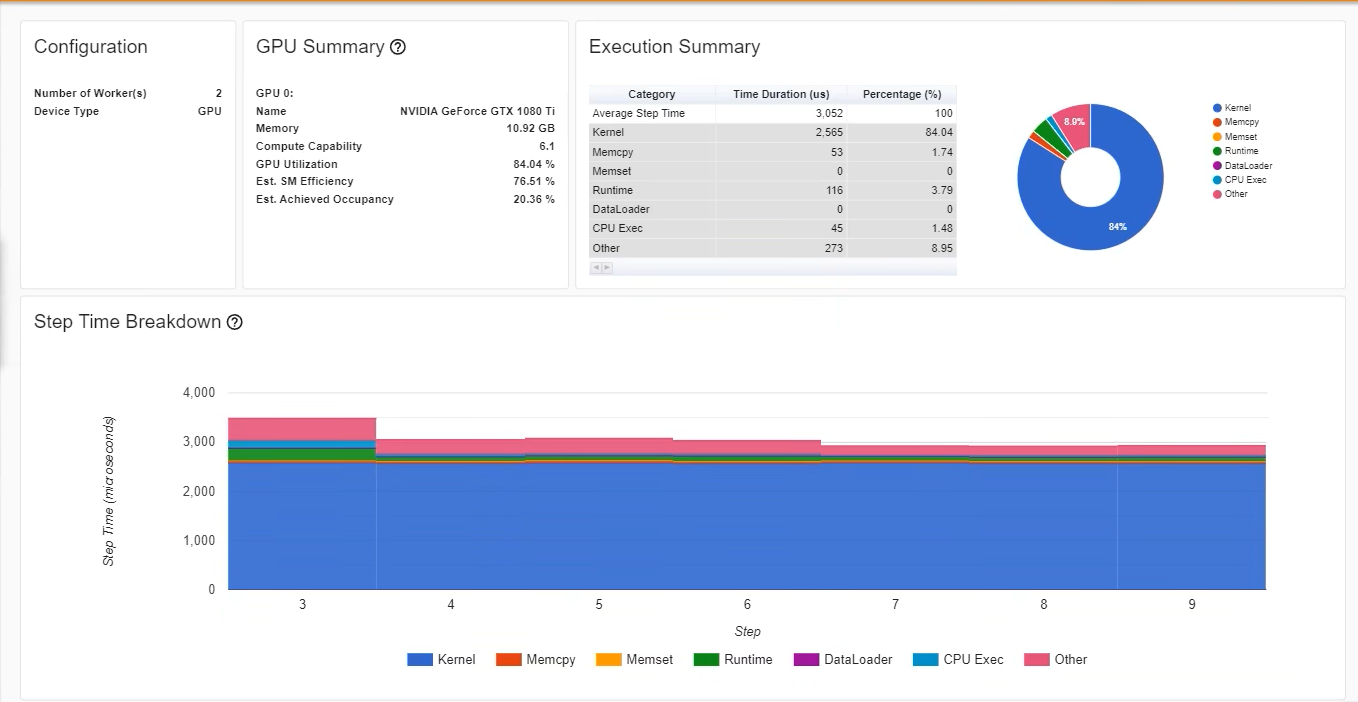
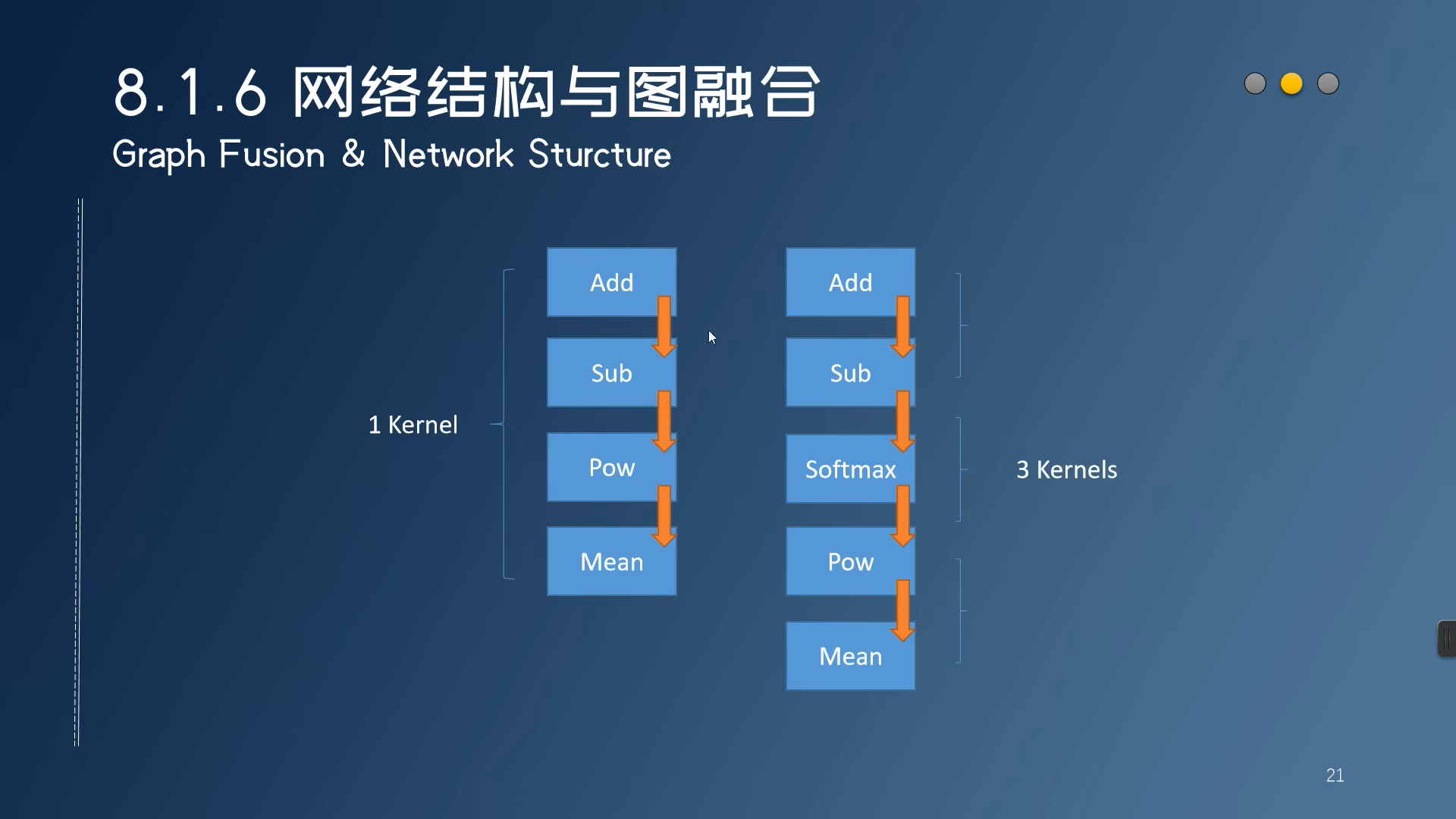
融图,多余的kernal去除 速度更快
TensorRT量化训练
代码
import torch
import torch.utils.data
import torchvision
from absl import logging
# 装一下下面这个库
from pytorch_quantization import nn as quant_nn
logging.set_verbosity(logging.FATAL) # Disable logging as they are too noisy in notebook
from pytorch_quantization import quant_modules
# 调用这个 quant_modules.initialize()
# 然后你正常训练就行了 ...
quant_modules.initialize()
model = torchvision.models.resnet50()
model.cuda()
# Quantization Aware Training is based on Straight Through Estimator (STE) derivative approximation.
# It is some time known as “quantization aware training”.
# We don’t use the name because it doesn’t reflect the underneath assumption.
# If anything, it makes training being “unaware” of quantization because of the STE approximation.
# After calibration is done, Quantization Aware Training is simply select a training schedule and continue training the calibrated model.
# Usually, it doesn’t need to fine tune very long. We usually use around 10% of the original training schedule,
# starting at 1% of the initial training learning rate,
# and a cosine annealing learning rate schedule that follows the decreasing half of a cosine period,
# down to 1% of the initial fine tuning learning rate (0.01% of the initial training learning rate).
# Quantization Aware Training (Essentially a discrete numerical optimization problem) is not a solved problem mathematically.
# Based on our experience, here are some recommendations:
# For STE approximation to work well, it is better to use small learning rate.
# Large learning rate is more likely to enlarge the variance introduced by STE approximation and destroy the trained network.
# Do not change quantization representation (scale) during training, at least not too frequently.
# Changing scale every step, it is effectively like changing data format (e8m7, e5m10, e3m4, et.al) every step,
# which will easily affect convergence.
# https://github.com/NVIDIA/TensorRT/blob/main/tools/pytorch-quantization/examples/finetune_quant_resnet50.ipynb
def export_onnx(model, onnx_filename, batch_onnx):
model.eval()
quant_nn.TensorQuantizer.use_fb_fake_quant = True # We have to shift to pytorch's fake quant ops before exporting the model to ONNX
opset_version = 13
# Export ONNX for multiple batch sizes
print("Creating ONNX file: " + onnx_filename)
dummy_input = torch.randn(batch_onnx, 3, 224, 224, device='cuda') #TODO: switch input dims by model
torch.onnx.export(model, dummy_input, onnx_filename, verbose=False, opset_version=opset_version, enable_onnx_checker=False, do_constant_folding=True)
return True
TensorRT 后训练量化(PPQ)
Quant with TensorRT OnnxParser
提升算子计算效率
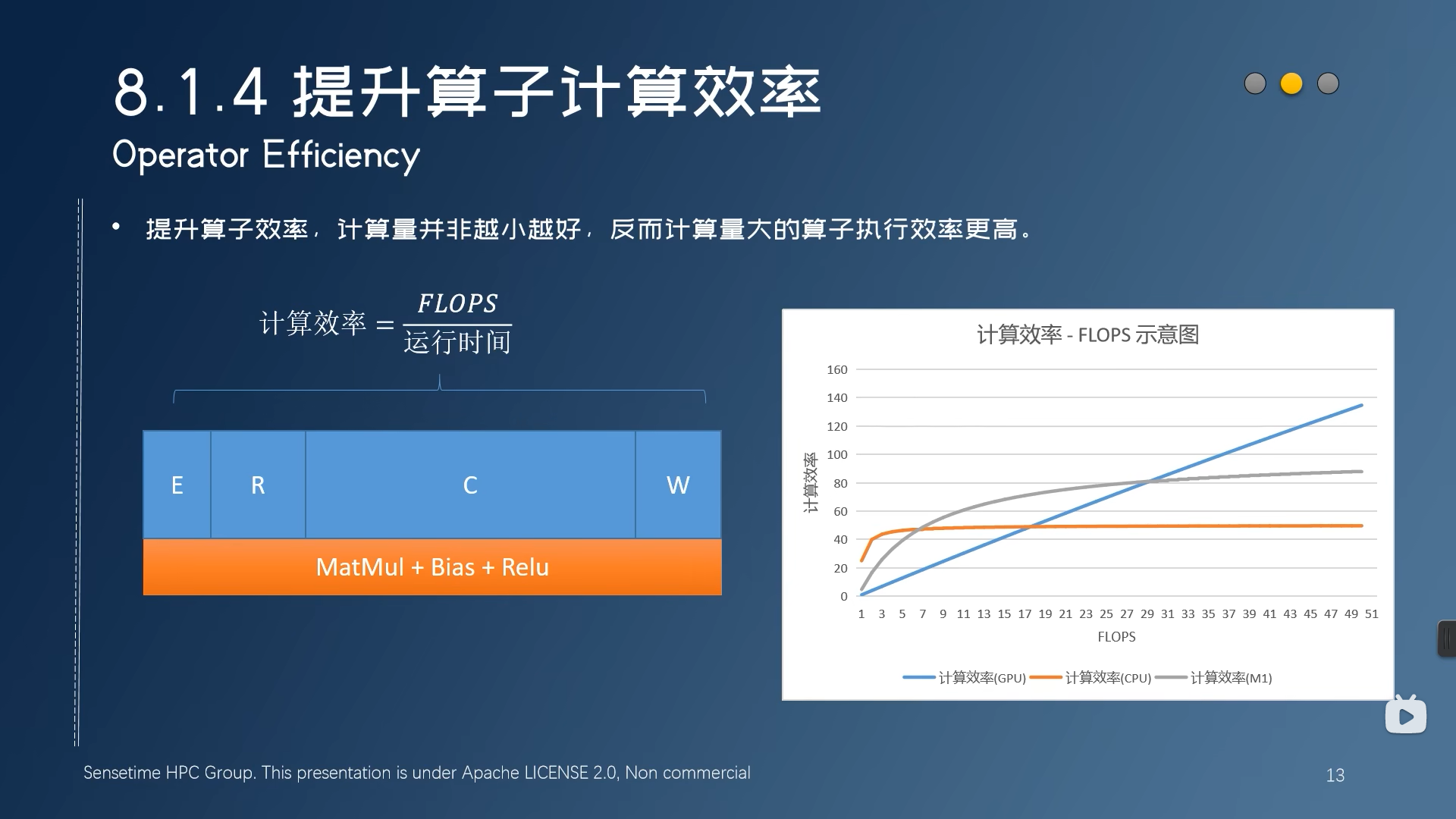

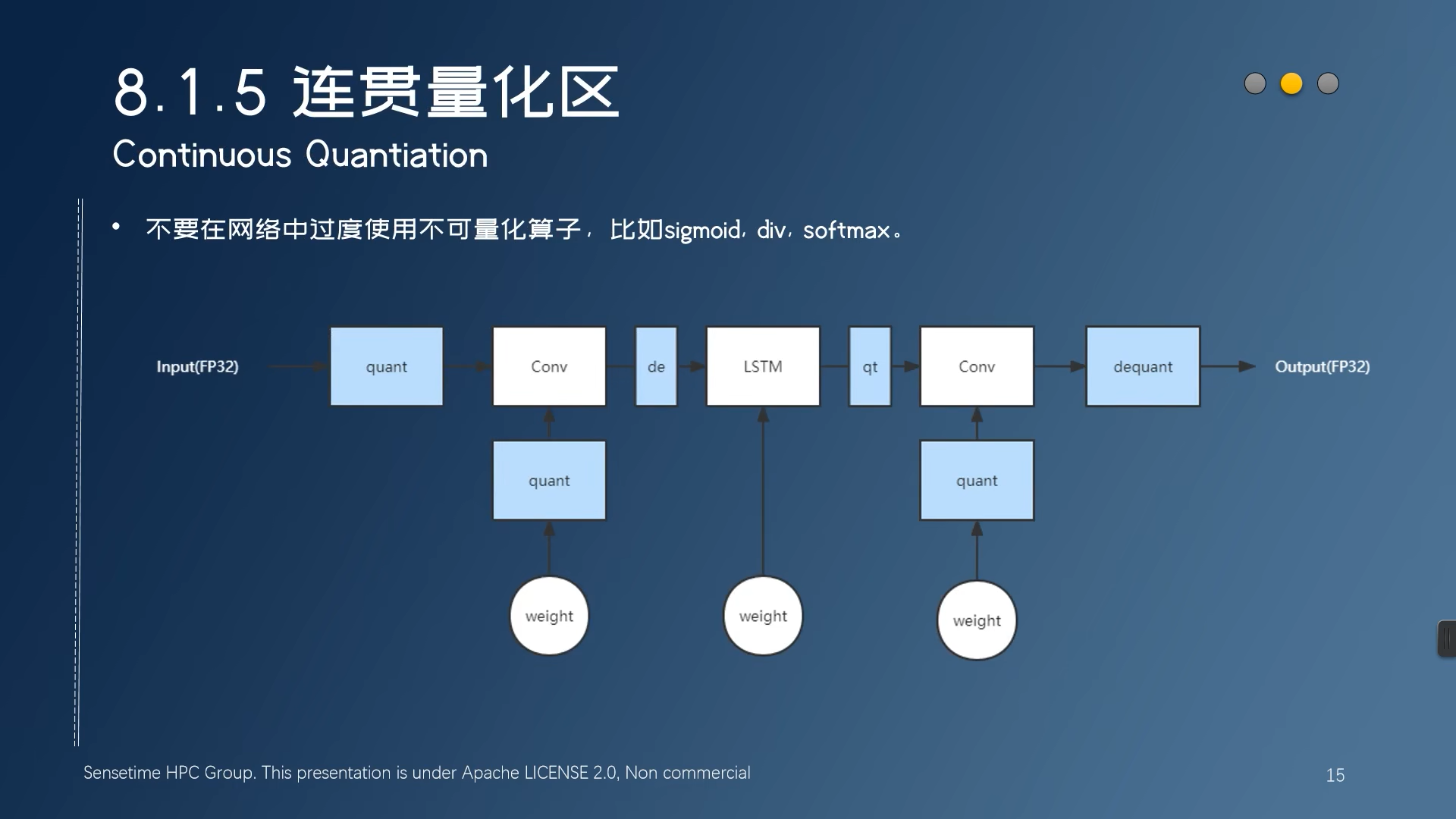
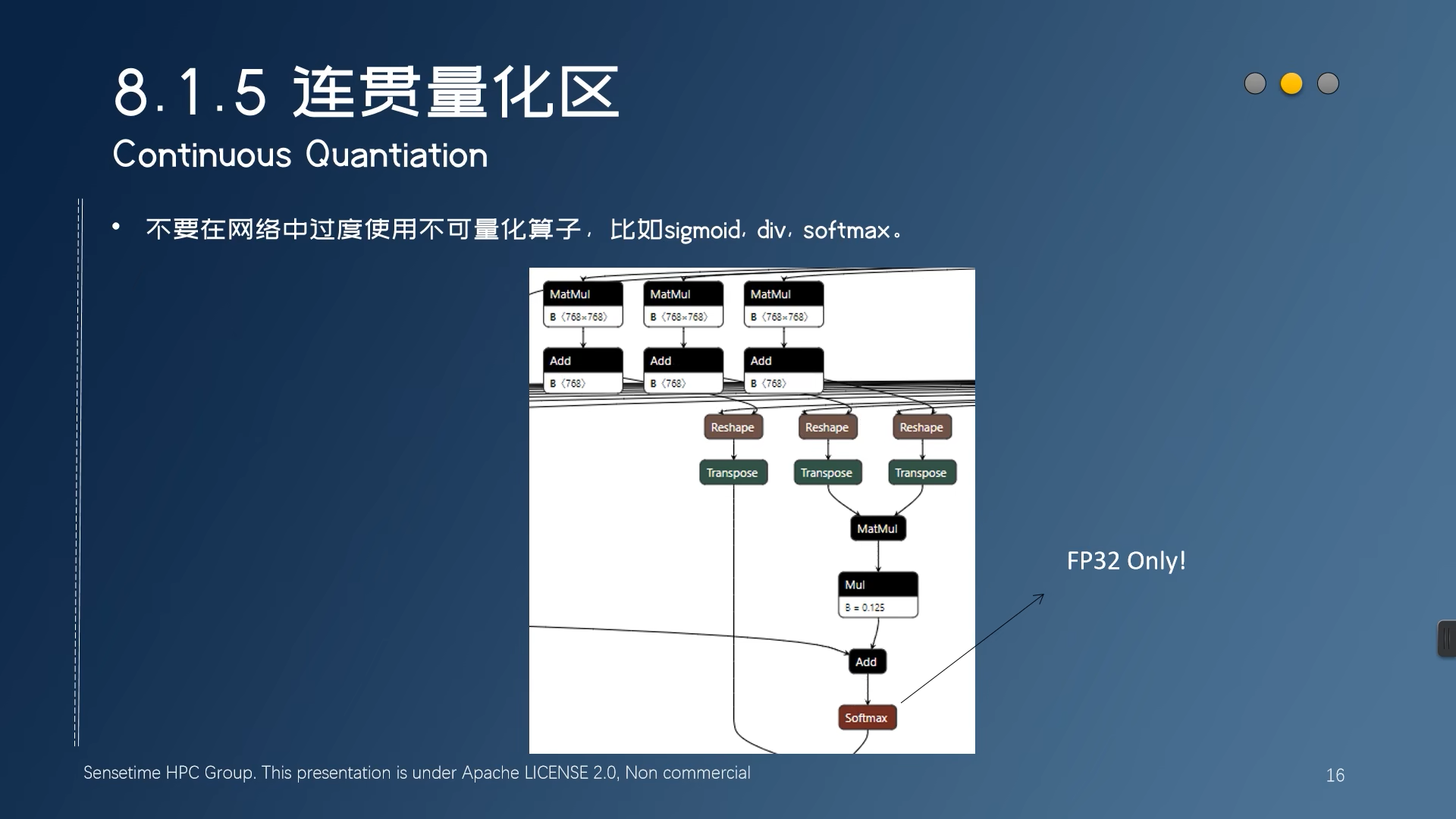

可以融合的结构



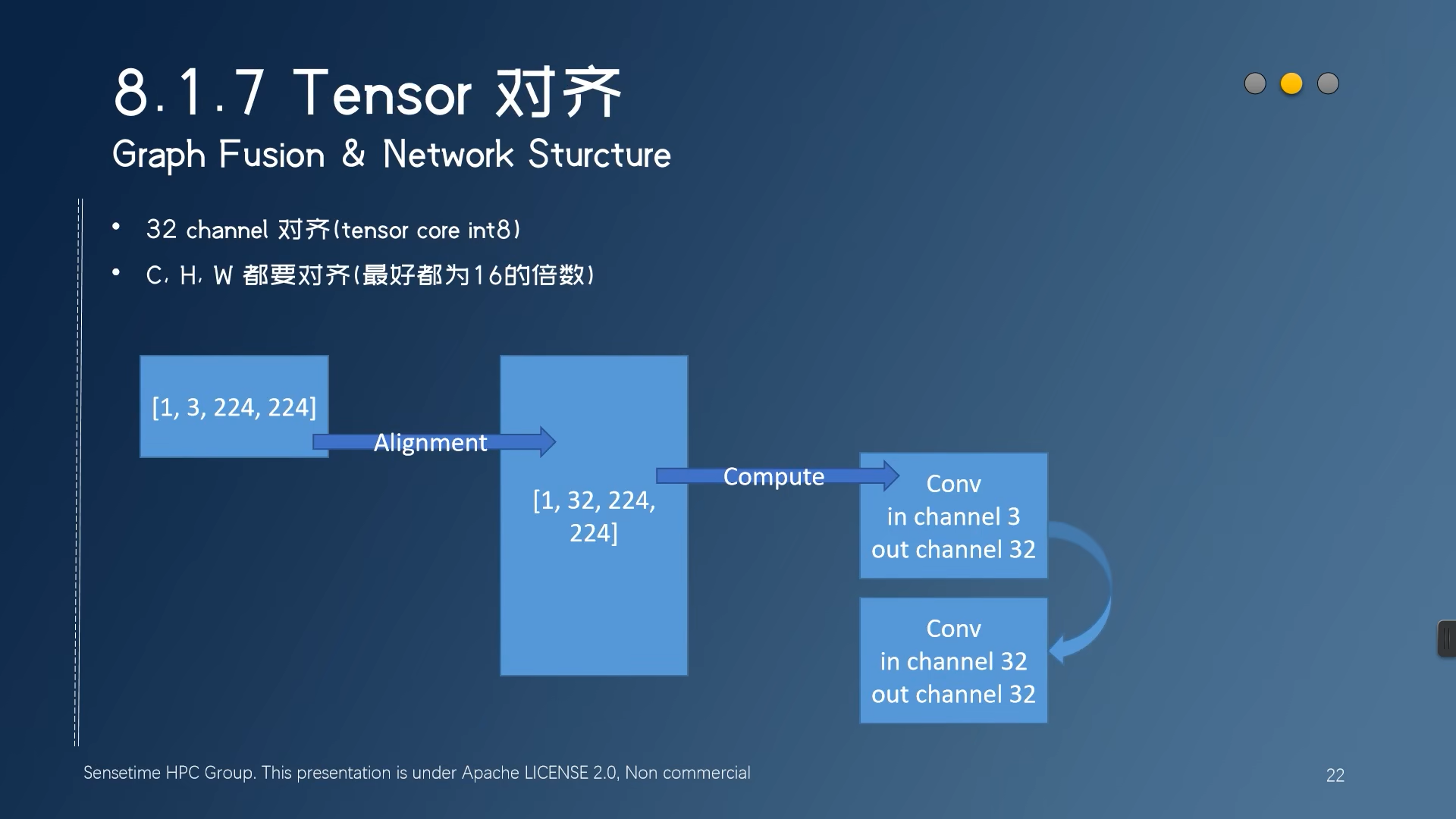
Tensor对齐
Profiling
自定义算子
