
摘要
https://arxiv.org/pdf/2303.16900.pdf
受 Vision Transformer 长距离依赖关系建模能力的启发,大核卷积最近被广泛研究和采用,以扩大感受野和提高模型性能,如采用7×7深度卷积的杰出工作connext。虽然这种深度算子只消耗少量的flop,但由于其较高的访存开销,极大地影响了模型在功能强大的计算设备上的效率。例如,ConvNeXt-T与ResNet-50具有类似的FLOPs,但在A100 gpu上进行全精度训练时,仅实现了60%的吞吐量。虽然减小ConvNeXt的核大小可以提高速度,但会导致性能的显著下降。目前还不清楚如何在保持性能的同时加快基于大核的CNN模型的速度。为解决该问题,受概念启发,本文提出将大核深度卷积分解为沿通道维度的四个平行分支,即小方形核、两个正交带核和一个单位映射。通过这种新的Inception深度卷积,构建了一系列网络,即IncepitonNeXt,不仅享有高吞吐量,而且保持有竞争力的性能。例如,InceptionNeXt-T实现了比convnext - t高1.6倍的训练吞吐量,并在ImageNet- 1K上实现了0.2%的top-1精度提高。我们期望InceptionNeXt可以作为未来架构设计的经济基准,以减少碳排放量。
1、简介
回顾深度学习的历史[31],卷积神经网络(Convolutional Neural Networks, cnn)[32,33]无疑是计算机视觉中最流行的模型。在2012年,AlexNet[30]赢得了ImageNet[11,50]比赛,开启了cnn在深度学习,尤其是计算机视觉领域的新时代。从那时起,大量的cnn成为潮流的引领者,如Network In Network[35]、VGG[53]、Inception Nets[56]、ResNe(X)t[20,71]、DenseNet[24]和其他高效模型[23,51,81,58,59]。
受到Transformer在NLP领域巨大成就的鼓舞,研究者们尝试将其模块或块集成到视觉CNN模型中[67,4,26,2],如代表性作品Non-local Neural Networks[67]和DETR[4],甚至将自注意作为独立的原语[48,82]。进一步,受语言生成式预训练[44]的启发,Image GPT (iGPT)[6]将像素作为token,采用纯Transformer进行视觉自监督学习。然而,由于计算成本高,iGPT处理高分辨率图像的能力受到限制[6]。Vision Transformer (ViT)[16]的开创性工作解决了这个问题,它将图像补丁视为令牌,并提出了一种简单的补丁嵌入来生成输入嵌入。ViT利用纯Transformer作为图像分类的主干,在大规模监督图像预训练后表现出显著的性能。
显然,ViT[16]进一步点燃了人们对Transformer在计算机视觉中的应用的热情。许多ViT变体[61,76,65,37,15,73,34],如DeiT[61]和Swin[37],被提出并在广泛的视觉任务中取得了显着的性能。类维特模型优于传统cnn的性能(例如,swun - t在ImageNet上的81.2% vs . resnet -50的76.1%[37,20,11,50])使许多研究人员认为变形金刚最终将取代cnn并主导计算机视觉领域。
现在是CNN反击的时候了。通过DeiT[61]和Swin[37]使用先进的训练技术,“ResNet反击”的工作表明,ResNet-50的性能可以提高2.3%,达到78.4%[69]。此外,ConvNeXt[38]表明,使用GELU[21]等现代模块激活和类似于注意力窗口大小[37]的大内核大小,CNN模型可以在各种设置和任务中稳定地优于Swin Transformer[37]。ConvNeXt并不孤单:越来越多的研究显示了类似的观察结果[13,17,72,49,36,75,64,22]。在这些现代CNN模型中,共同的关键特征是大的接受场,通常通过大核尺寸(例如7 × 7)的深度卷积[41,7]来实现。
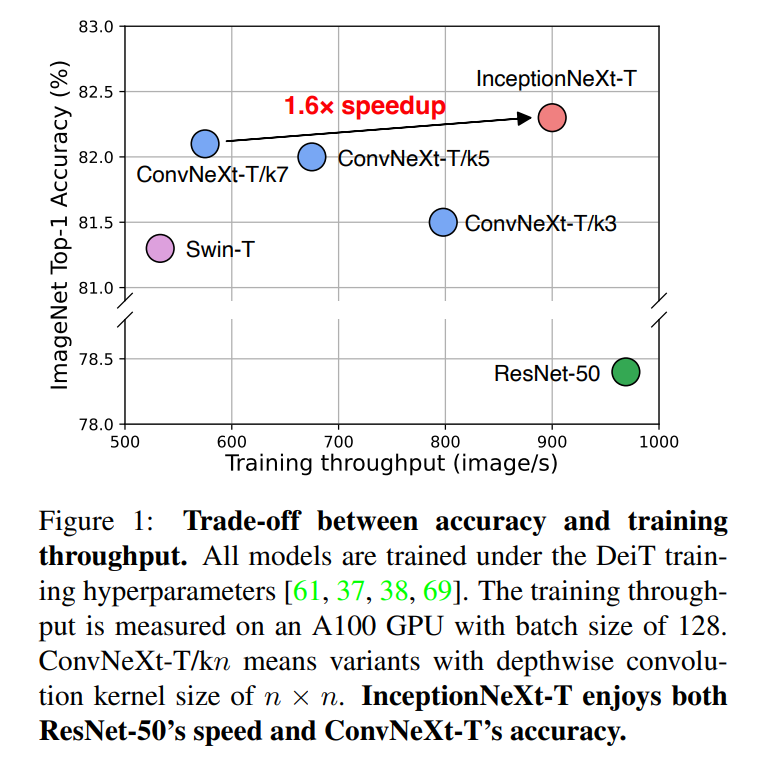
然而,尽管深度卷积的FLOPs很小,但它实际上是一个“昂贵”的运算符,因为它带来了很高的内存访问成本,并且可能成为gpu等强大计算设备的瓶颈[40]。此外,正如在[13]中所观察到的,更大的内核尺寸导致更低的速度。如图1所示,默认内核大小为7 × 7的ConvNeXt-T比内核大小为3 × 3的ConvNeXt-T慢1.4倍,比ResNet-50慢1.8倍,尽管它们具有相似的FLOPs。然而,使用较小的内核大小限制了接受域,这可能导致性能下降。例如,与ConvNeXt-T/k7(其中kn表示内核大小为n × n)相比,ConvNeXt-T/k3在ImageNet-1K数据集上的top-1精度下降了0.6%。
目前还不清楚如何在保持大内核cnn性能的同时加速它们。在本文中,我们的目标是通过以ConvNeXt为基础并改进深度卷积模块来解决这个问题。我们的初步发现表明,并不是所有的输入通道都需要进行计算代价高昂的深度卷积运算[40],我们的初步实验结果也证明了这一点(见表10)。因此,我们建议保留一些通道不变,仅对部分通道进行深度卷积操作。接下来,我们提出将深度卷积的大核分解成几组具有Inception风格的小核[56,57,55]。具体来说,对于处理通道,1/3的通道以3 × 3的核进行,1/3的通道以1 × k进行,剩下的1/3的通道以k × 1进行。有了这个新的简单而廉价的运算符,称为“Inception深度卷积”,我们构建的模型InceptionNeXt在准确性和速度之间实现了更好的权衡。例如,如图1所示,InceptionNeXt-T实现了比ConvNeXt-T更高的准确率,同时享有与ResNet-50相似的1.6倍的训练吞吐量加速。
本文的贡献是双重的。首先,我们提出了Inception深度卷积,它将代价高昂的深度卷积分解为三个核大小较小的卷积分支和一个恒等映射分支。其次,大量的图像分类和语义分割实验表明,与ConvNeXt相比,我们的模型InceptionNeXt实现了更好的速度-精度权衡。我们希望InceptionNeXt可以作为一个新的CNN基线来加速神经架构设计的研究。
2. 相关工作
2.1. Transformer v.s.CNN
Transformer[63]于2017年推出,用于NLP任务。与LSTM相比,Transformer不仅可以并行训练,而且性能更好。然后在Transformer上建立了许多著名的NLP模型,包括GPT系列[44,45,3,42],BERT [12], T5[47]和OPT[80]。对于Transformer在视觉任务中的应用,vision Transformer (ViT)绝对是开创性的工作,它表明Transformer在经过大规模监督训练后可以取得令人印象深刻的性能。Swin[37]等后续研究[61,76,65,66,18]不断提高模型性能,在各种视觉任务上取得了新的进展。这些结果似乎告诉我们“注意力是你所需要的”[63]。
但事情并没有那么简单。像DeiT这样的ViT变体通常采用现代训练程序,包括各种先进的数据增强技术[10,9,79,77,83]、正则化[57,25]和优化器[28,39]。Wightman等人发现,通过类似的训练程序,ResNet的性能可以得到很大的提高。此外,Yu等人[74]认为在模型性能中起关键作用的是通用架构而不是注意力。Han等人[19]发现,用规则或动态深度卷积代替Swin中的注意力,模型也能获得相当的性能。ConvNeXt[38]是一项出色的工作,它将ResNet现代化为一个高级版本,其中包含一些来自vit的设计,并且所得到的模型始终优于Swin[37]。RepLKNet[13]、VAN[17]、FocalNets[72]、HorNet[49]、SLKNet[36]、ConvFormer[75]、Conv2Former[22]、InternImage[64]等工作也在不断提高cnn的性能。尽管这些模型获得了很高的性能,但忽略了效率,表现出比ConvNeXt更低的速度。实际上,与ResNet相比,ConvNeXt也不是一个高效的模型。我们认为CNN模型应该保持原有的效率优势。因此,在本文中,我们的目标是在保持高性能的同时提高cnn的模型效率。
2.2. 大核卷积。
众所周知的作品,如AlexNet[30]和Inception v1[56]已经分别使用了高达11×11和7×7的大型内核。为了提高大核的效率,VGG[53]提出将3 × 3卷积大量堆叠,而Inception v3[57]则将k× k卷积依次分解为1 × k和k×1堆叠。对于深度卷积,MixConv[60]将内核从3 × 3到k分成几组×k。此外,Peng等人发现大核对于语义分割很重要,他们分解了类似于Inception v3的大核[57]。目睹了Transformer在视觉任务中的成功[16,65,37],大核卷积得到了更多的重视,因为它可以为模仿注意力提供一个大的接受场[19,38]。例如,ConvNeXt默认采用7 × 7的核大小进行深度卷积。为了使用更大的内核,RepLKNet[13]建议利用结构重新参数化技术[78,14]将内核大小扩大到31 × 31;VAN[17]将大核深度卷积(DWConv)和深度扩张卷积依次叠加,得到21×21接受域;FocalNets采用门控机制从深度卷积叠加中融合多层次特征;最近,SLaK[36]将大内核k×k分解为两个小的非平方内核(k×s和s×k),其中s <k).与这些工作不同,我们的目标不是扩大更大的内核。相反,我们的目标是提高效率,并以一种简单且对速度友好的方式分解大型内核,同时保持相当的性能。
3、方法
3.1、MetaNeXt
MetaNeXt块的构想。ConvNeXt[38]是一种结构简单的现代CNN模型。对于每个ConvNeXt块,首先通过深度卷积处理输入X,以沿空间维度传播信息。我们遵循MetaFormer[74]将深度卷积抽象为负责空间信息交互的令牌混合器。因此,如图2中的第二个子图所示,ConvNeXt被抽象为MetaNeXt块。形式上,在MetaNeXt块中,它的输入X首先被处理为
X ′ = TokenMixer ( X ) (1) X^{\prime}=\operatorname{TokenMixer}(X) \tag{1} X′=TokenMixer(X)(1)
式中 X , X ′ ∈ R B × C × H × W X, X^{\prime} \in \mathbb{R}^{B \times C \times H \times W} X,X′∈RB×C×H×W分别表示批量大小、通道数、高度、宽度。然后对token mixer的输出进行归一化,
Y = Norm ( X ′ ) (2) Y=\operatorname{Norm}\left(X^{\prime}\right) \tag{2} Y=Norm(X′)(2)
经过归一化[27,1]后,得到的特征被输入到由两个全连接层组成的MLP模块中,在它们之间夹着一个激活函数,与Transformer中的前馈网络相同[63]。两个全连接层也可以通过1 × 1卷积实现。采用快捷连接[20,54]。这个过程可以用
Y = Conv 1 × 1 r C → C { σ [ Conv 1 × 1 C → r C ( Y ) ] } + X , (3) Y=\operatorname{Conv}_{1 \times 1}^{r C \rightarrow C}\left\{\sigma\left[\operatorname{Conv}_{1 \times 1}^{C \rightarrow r C}(Y)\right]\right\}+X, \tag{3} Y=Conv1×1rC→C{
σ[Conv1×1C→rC(Y)]}+X,(3)
其中 Conv k × k C i → C o \operatorname{Conv}_{k \times k}^{C_{i} \rightarrow C_{o}} Convk×kCi→Co表示卷积核大小为k×k, C i C_{i} Ci的输入通道和 C o C_{o} Co的输出通道;r为膨胀比,σ为激活函数。
与MetaFormer块的比较。如图2所示,可以发现MetaNeXt块与MetaFormer块[74]共享相似的模块,例如token mixer和MLP。然而,两种模型之间的关键区别在于快捷连接的数量[20,54]。MetaNeXt块实现一个快捷连接,而MetaFormer块包含两个,一个用于令牌混合器,另一个用于MLP。从这个角度来看,MetaNeXt块可以看作是合并了MetaFormer的两个剩余子块的结果,从而简化了整个体系结构。因此,与MetaFormer相比,MetaNeXt架构表现出更高的速度。然而,这种简单的设计有一个限制:MetaNeXt中的令牌混频器组件不能很复杂(例如,Attention),如我们的实验所示(表3)。
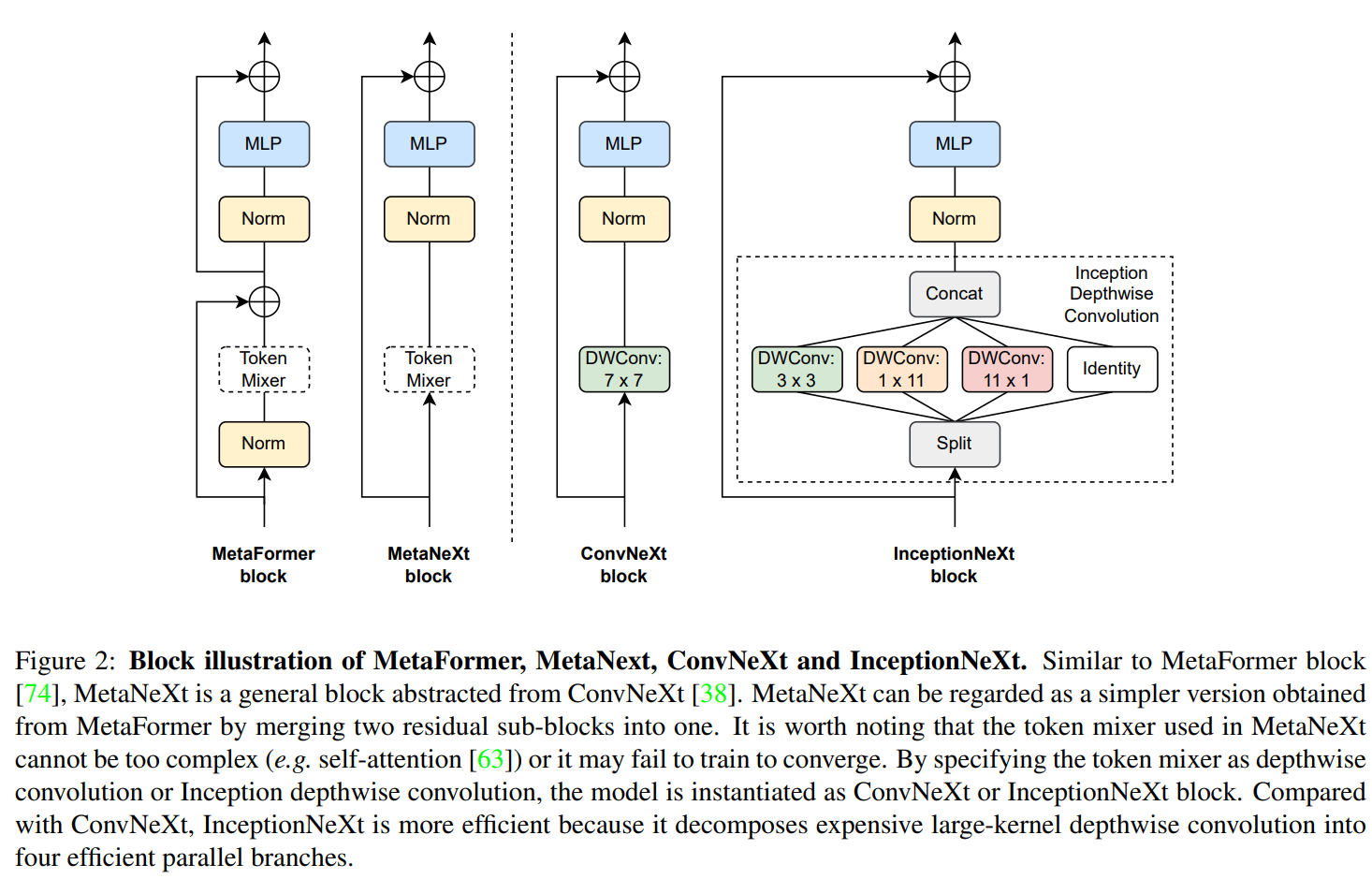
实例化到ConvNeXt。如图2所示,在ConvNeXt中,令牌混频器仅通过深度卷积实现,
X ′ = TokenMixer ( X ) = DWConv k × k C → C ( X ) (4) X^{\prime}=\operatorname{TokenMixer}(X)=\operatorname{DWConv}_{k \times k}^{C \rightarrow C}(X) \tag{4} X′=TokenMixer(X)=DWConvk×kC→C(X)(4)
其中 D W C o n v k × k C → C DWConv { }_{k \times k}^{C \rightarrow C} DWConvk×kC→C表示深度卷积,核大小为k×k。在ConvNeXt中,k默认为7。
3.2. Inception深度卷积
构想。如图1所示,具有大核大小的传统深度卷积显著阻碍了模型速度。首先,受ShuffleNetV2[40]的启发,我们发现处理部分通道对于单个深度卷积层也足够了,如我们在附录a中的初步实验所示。因此,我们保持部分通道不变,并将其表示为恒等映射的一个分支。对于处理通道,我们建议采用Inception风格对深度操作进行分解[56,57,55]。Inception [56]利用了小内核(例如3×3)和大内核(例如5×5)的几个分支。同样,我们采用3 × 3作为我们的分支之一,但避免使用大的方形核,因为它们的实际速度很慢。相反,大内核kh × kw被分解为1 × kw和kh × 1,灵感来自于Inception v3[57]。
具体来说,对于输入X,我们沿着通道维度将其分成四组,
X h w , X w , X h , X i d = Split ( X ) = X : , : g , X : g : 2 g , X : 2 g : 3 g , X : 3 g : (5) \begin{aligned} X_{\mathrm{hw}}, X_{\mathrm{w}}, X_{\mathrm{h}}, X_{\mathrm{id}} & =\operatorname{Split}(X) \\ & =X_{:,: g}, X_{: g: 2 g}, X_{: 2 g: 3 g}, X_{: 3 g:} \end{aligned} \tag{5} Xhw,Xw,Xh,Xid=Split(X)=X:,:g,X:g:2g,X:2g:3g,X:3g:(5)
其中g是卷积分支的通道数。我们可以通过 g = r g C g=r_{g} C g=rgC设置比率 r g r_{g} rg来确定分支通道数。接下来,分裂的输入被馈送到不同的平行分支,
X h w ′ = D W C o n v k s × k s g → g g ( X h w ) , X w ′ = D W C o n v 1 × k b g → g ( X w ) , X h ′ = D W C o n v k b × 1 g → g g ( X h ) , X i d ′ = X i d . (6) \begin{aligned} X_{\mathrm{hw}}^{\prime} & =\mathrm{DWConv}_{k_{s} \times k_{s}}^{g \rightarrow g} g\left(X_{\mathrm{hw}}\right), \\ X_{\mathrm{w}}^{\prime} & =\mathrm{DWConv}_{1 \times k_{b}}^{g \rightarrow} g\left(X_{\mathrm{w}}\right), \\ X_{\mathrm{h}}^{\prime} & =\mathrm{DWConv}_{k_{b} \times 1}^{g \rightarrow g} g\left(X_{\mathrm{h}}\right), \\ X_{\mathrm{id}}^{\prime} & =X_{\mathrm{id}} . \end{aligned} \tag{6} Xhw′Xw′Xh′Xid′=DWConvks×ksg→gg(Xhw),=DWConv1×kbg→g(Xw),=DWConvkb×1g→gg(Xh),=Xid.(6)
式中 k s k_{s} ks表示小平方内核大小默认设置为3; k b k_{b} kb表示默认设置为11的带内核大小。最后,将每个分支的输出连接起来,
X ′ = Concat ( X h w ′ , X w ′ , X h ′ , X i d ′ ) . (7) X^{\prime}=\operatorname{Concat}\left(X_{\mathrm{hw}}^{\prime}, X_{\mathrm{w}}^{\prime}, X_{\mathrm{h}}^{\prime}, X_{\mathrm{id}}^{\prime}\right) \text {. } \tag{7} X′=Concat(Xhw′,Xw′,Xh′,Xid′). (7)
InceptionNeXt块的示例如图2所示。此外,其PyTorch[43]代码在算法1中进行了总结。

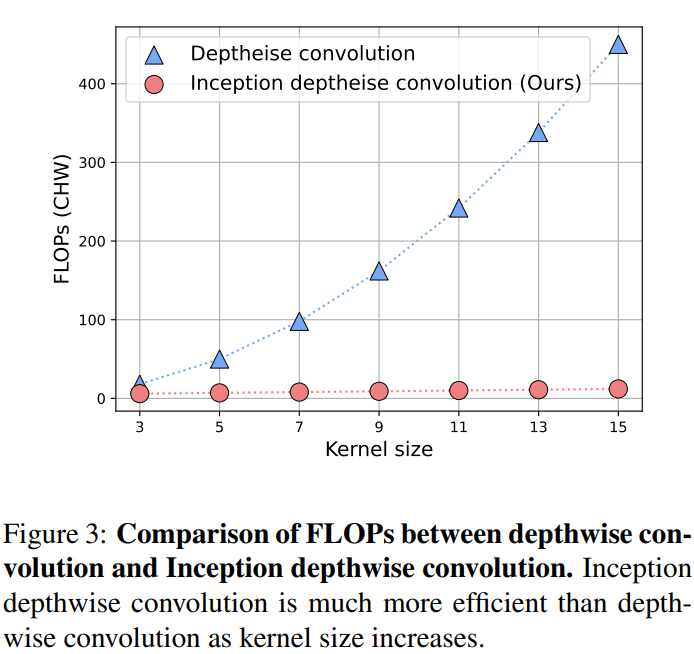
复杂度。常规卷积、深度卷积和Inception深度卷积这三种卷积的复杂度如表1所示。可以看出,就FLOPs的参数数量而言,起始深度卷积比其他两种卷积更有效。Inception深度卷积消耗与通道和内核大小线性的参数和计算量。关于FLOPs, depthwise和Inception depthwise卷积的比较也清晰地显示在图3中。
3.3. InceptionNeXt
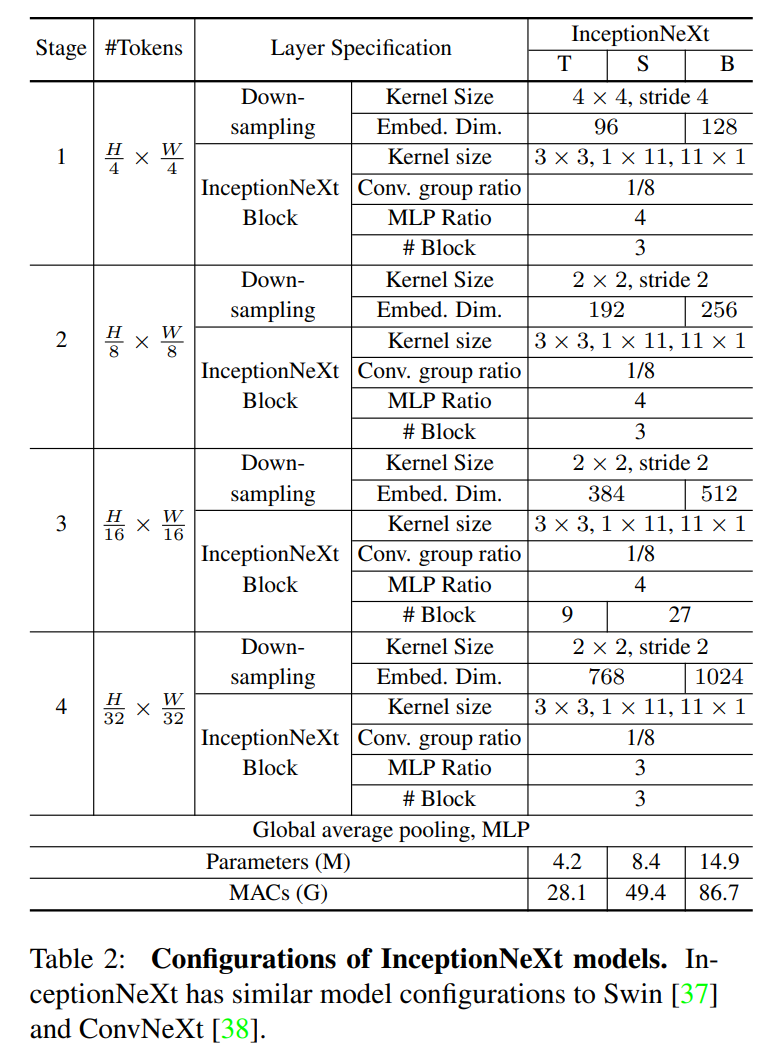
基于InceptionNeXt块,我们可以构建一系列名为InceptionNeXt的模型。由于ConvNeXt[38]是我们的主要比较基线,我们主要遵循它来构建具有几种尺寸的模型。具体而言,与ResNet[20]和ConvNeXt类似,InceptionNeXt也采用了4阶段框架。与ConvNeXt一样,对于小尺寸,4个阶段的数量是[3,3,9,3],对于基本尺寸,4个阶段的数量是[3,3,27,3]。由于强调速度,我们采用了批量归一化。与ConvNeXt的另一个区别是,InceptionNeXt在阶段4中使用3的MLP比率,并将保存的参数移动到分类器,这可以帮助减少一些失败(例如,基础大小为3%)。详细的模型配置如表2所示。
4. 实验
4.1. 图像分类
设置。对于图像分类任务,ImageNet-1K[11,50]是最常用的基准之一,它在训练集中包含约130万张图像,在验证集中包含5万张图像。为了与广泛使用的基线(如swin[37]和ConvNeXt[38])公平地比较,本文主要遵循DeiT[61]的训练超参数,而没有蒸馏。具体来说,模型由AdamW[39]优化器训练,学习率lr = 0.001 × batchsize/1024(本文使用lr = 4e−3和batchsize = 4096,与ConvNeXt相同)。在DeiT之后,数据增强包括标准随机调整大小的裁剪,水平翻转,RandAugment [10], Mixup [79], CutMix[77],随机擦除[83]和颜色抖动。正则化采用标签平滑[57]、随机深度[25]和权重衰减。与ConvNeXt一样,我们也使用LayerScale[62],这是一种帮助训练深度模型的技术。我们的代码基于PyTroch[43]和timm[68]库。
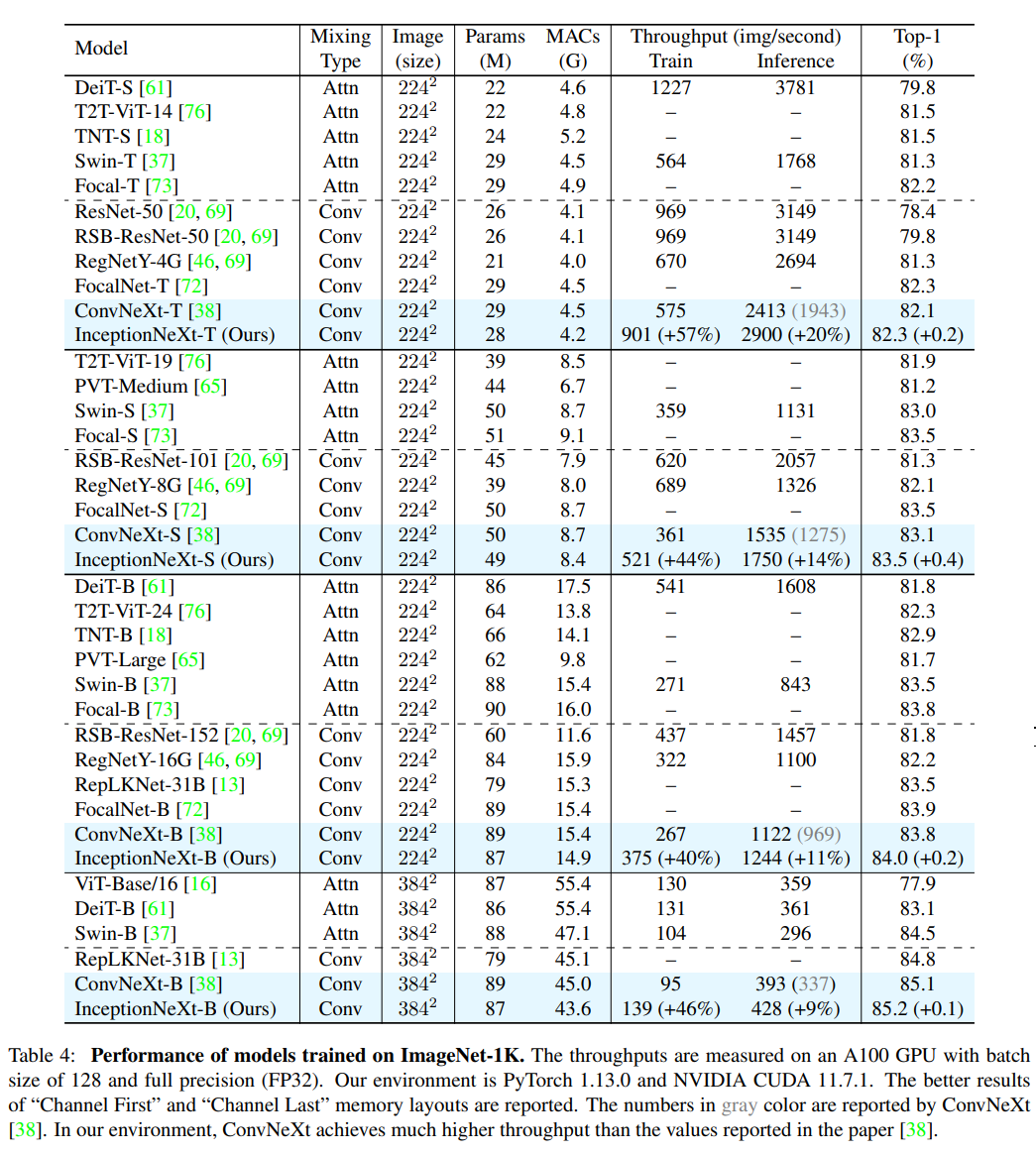
结果。将InceptionNeXt与各种最先进的模型进行了比较,包括基于注意力和基于卷积的模型。从表4中可以看出,InceptionNeXt在获得更高速度的同时,也获得了极具竞争力的性能。在相似的模型大小和mac下,InceptionNeXt在top-1精度方面始终优于ConvNeXt,并表现出更高的吞吐量。例如,InceptionNeXt-T不仅超过ConvNeXtT 0.2%,而且比ConvNeXts享有1.6×/1.2×训练/推理吞吐量,与ResNet50相似。也就是说,InceptionNeXt-T同时具有ResNet50的速度和ConvNeXt-T的精度。此外,在Swin和ConvNeXt之后,我们还对在224 × 224到384 × 384分辨率下训练的模型进行了30个epoch的微调。我们可以看到,InceptionNeXt仍然获得了类似于ConvNeXt的良好性能。
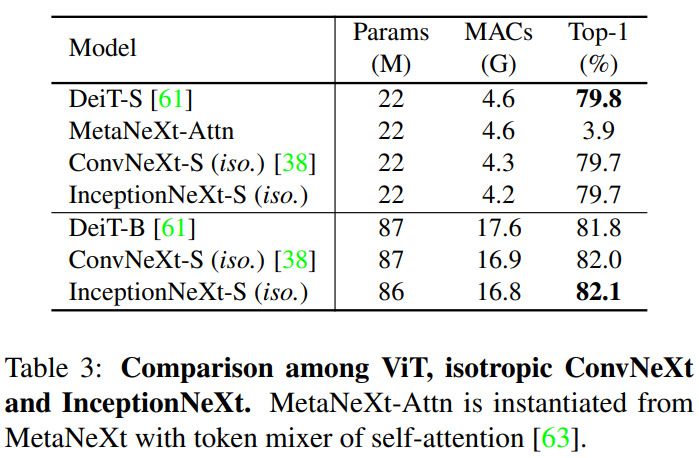
除了4阶段框架[53,20,37],另一个值得注意的是ViT-style[16]各向同性架构,它只有一个阶段。为了匹配DeiT的参数和mac,我们在ConvNeXt[38]之后构造了InceptionNeXt (iso.)。具体来说,对于small/base模型,我们将嵌入维度设置为384/768,块号设置为18/18。此外,通过将self-attention指定为token mixer,从MetaNeXt块实例化一个名为MetaNeXt- attn的模型。该模型的目的是研究是否有可能将Transformer块的两个剩余子块合并为一个单独的子块。实验结果如表3所示。可以看到,InceptionNeXt也可以在各向同性架构中表现良好,表明InceptionNeXt在不同框架中表现出良好的泛化性。值得注意的是,MetaNeXt-Attn无法训练收敛,仅实现了3.9%的准确率。这个结果表明,与MetaFormer中的令牌混合器不同,MetaNeXt中的令牌混合器不能太复杂。如果是,则模型可能不可训练。
4.2、语义分割
设置。ADE20K[84]是常用的场景解析基准之一,用于评估在语义分割任务上的模型。ADE20K包含150个细粒度语义类别,在训练集和验证集上分别包含20000张和2000张图像。使用分辨率为2242的ImageNet1K[11]上训练的检查点来初始化骨干网络。在Swin[37]和ConvNeXt[38]之后,我们首先用UperNet[70]评估了InceptionNeXt。模型使用AdamW[39]优化器进行训练,学习率为6e-5,批量大小为16,迭代次数为160K。继PVT[65]和PoolFormer[74]之后,还使用语义FPN[29]对InceptionNeXt进行评估。在通常的实践中[29,5],对于设置80K迭代,批量大小为16。在PoolFormer[74]之后,我们将批量大小增加到32,并将迭代次数减少到40K,以加快训练速度。采用优化的AdamW[28,39],学习率为2e-4,多项式衰减调度为0.9功率。我们的代码基于PyTorch[43]和mmsegmentation库[8]。
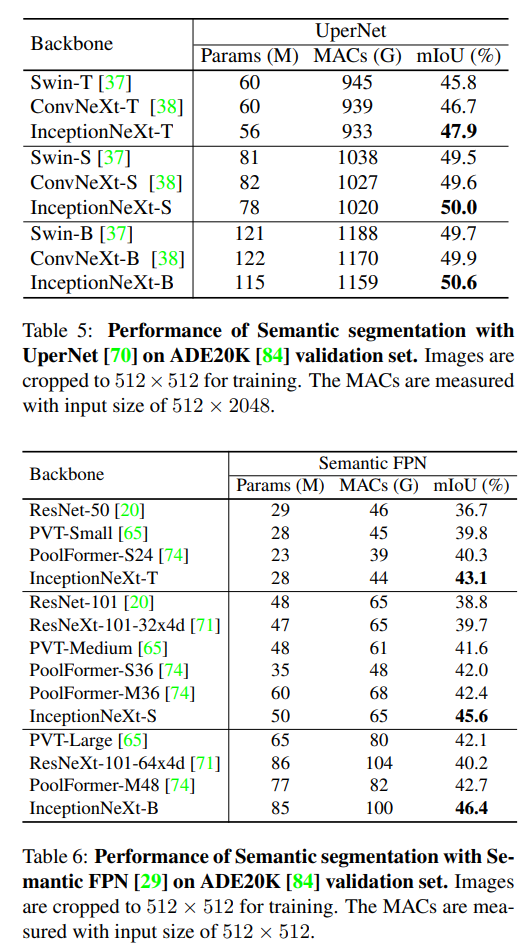
结果。使用UpNet[70]进行分割,结果如表5所示。可以看到,在不同的模型尺寸下,InceptionNeXt始终优于Swin[37]和ConvNeXt[38]。在语义FPN[29]的设置上,如表6所示,InceptionNeXt显著优于其他骨干,如PVT[65]和PoolFormer[74]。这些结果表明,InceptionNeXt在密集预测任务中也具有很高的潜力。
4.3、消融研究
使用InceptionNeXt-T作为基线,从以下几个方面对ImageNet-1K[11,50]进行了消融研究。
分支。Inception深度卷积包括四个分支,三个卷积分支和身份映射。当移除水平或垂直波段内核的任何分支时,性能从82.3%显著下降到81.9%,表明了这两个分支的重要性。这是因为这两个带核的分支可以扩大模型的感受野。对于3 × 3大小的正方形分支,删除该分支也可以达到82.0%的top-1准确率,并带来更高的吞吐量。这启发我们,如果我们更加重视模型速度,可以采用InceptionNeXt的简单版本,不需要3×3的平方核。对于band内核,Inception v3主要以顺序的方式装备它们。我们发现这种组装方法同样可以获得类似的性能,甚至可以使模型的速度略有提高。一个可能的原因是PyTorch/CUDA可能对顺序卷积优化得很好,而我们只在较高的层次上实现了并行分支(参见算法1)。我们相信优化得越好,并行方法会更快。因此,默认采用并行的带核方法。

带内核大小。研究发现,当内核大小为7到11时,性能可以得到提高,但当内核大小增加到13时,性能会下降。这种现象可能是由于优化困难造成的,可以通过结构重新参数化等方法来解决[14,13]。为简单起见,我们默认将带内核大小设置为11。
卷积分支比。当比值从1/8增加到1/4时,无法观察到性能改善。Ma等[40]也指出,并非所有通道都需要进行卷积。但当该比率降低到1/16时,会带来严重的性能下降。这是因为较小的比率会限制令牌混合的程度,从而导致性能下降。因此,我们将卷积分支比默认设置为1/8。
5. 结论及未来工作展望
本文提出一种高效的CNN InceptionNeXt架构,与之前的网络架构相比,在实际速度和性能之间享有更好的权衡。InceptionNeXt沿着通道维度将大核深度卷积分解为四个平行分支,包括单位映射,一个小正方形核和两个正交的带核。在实践中,所有这四个分支的计算效率都比大核深度卷积高得多,并且还可以一起工作,具有一个大的空间感受野,以获得良好的性能。大量的实验结果验证了InceptionNeXt的优越性能和较高的实用效率。
我们还注意到,推理中InceptionNeXt的加速比小于训练时的加速比。未来,我们将深入研究训练和推理过程中不同的加速比,希望找到一种方法,在推理过程中进一步提高InceptionNeXt网络架构的加速比。