注:本模型仍在测试与改进阶段,由于解码器部分是由自己借鉴Unet模型设计,如果发现bug或者更好的改进方法设计理念欢迎私信!
1.模型结构
ConvNext的结构如下图左侧。
After the publication of the famous paper "Attention is all you need", the Transformer model, which is based on the theory of concentration, has become more popular than ever in the field of computer vision, and once outperformed the older convolutional neural network models. ConvNeXt is a model introduced in a paper written by Facebook and Berkeley University in 2022. It takes advantage of Vision Transformers and "modularizes" several key components of Convnet to improve accuracy. At the same time, it maintains the efficiency and simplicity of traditional CNN models and can compete with Vision Transformer in terms of accuracy and scalability. The design highlights include "reasonable Stage Ratio", "grouped convolution", "larger convolution kernel", "fewer However, ConvNeXt were originally designed for classification problems, and the last fully connected layer of the model has only 'num_class'. nodes. In order to make it competent for MRI segmentation tasks, a decoder referencing the Unet model was designed to upsample the convolved model of ConvNeXt. For distinction, this new model is named ConvNeXt++ by our group. The following figure is a schematic diagram of the model structure of ConvNeXt++.
# 引用自我们组的group report

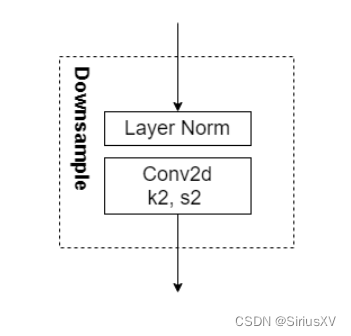
ConvNeXts++的编码部分的基本结构由三个模块组成。STEM、BLOCK和DownSample下采样。Block和Downsample模块的结构如上所示。(模块化是ConvNeXt的一个非常好的优点)
BLOCK
在每个block中,输入图像被复制成两份,一份通过深度卷积层和LN层,然后再通过两个k=1,s=1的卷积层,激活函数放在两层之间。最后由Layer Scale层进行缩放,Drop Path层实现神经元的随机失活,以避免噪声数据导致模型向局部最优解收敛。另一份输入图像不作处理,通过 "Shortcut"直接与模型的输出相加。每个Stage(一系列Block加其上可能存在的Downsample层称为一个Stage)的Block的数量可以根据需要修改。ConvNeXts有不同的版本,它们在Block的数量和一些参数上有所不同。
DECODER
decoder 的结构在上面的结构图右侧展示的非常清楚,可惜我还没有实现完全的模块化。decoder的设计参考了unet改进版,即应用了BN与padding的Unet模型,在ConvNeXt++中模型中,每个stage的输出结果经过上采样,与上一层经过处理的结果相叠加,经过层层叠加最后经过一个最终上采样层,输出一个原尺寸(224*224*1)的图像mask。其中n就是分割任务的种类个数,在本次task中n为1,也即只需要进行0-1分类。模型的各个层的输入输出参数以及卷积层的k,s,p值都描述的很清楚了,这里不再赘述。
在本次项目中,我们自行构建ConvNeXt的解码器,组建ConvNeXt++模型并且使之可以适应分割任务。很难否定这是一个大胆的尝试,因为现有的模型,包括Unet,Unet++与Deeplab等模型都较为成熟。同时本次分类任务也比较简单,所有的样本都已经过初步的处理。但ConvNeXt更巧妙的网络设计决定了其在卷积时对图像特征的保留能力,这使他在分割任务中也存在很大潜能,事实证明其相比于Unet等模型仍然存在优势。
然而,出于批判性思维,我们自行设计的ConvNeXt++模型仍有部分缺陷,其中之一就是解码器的结构。解码器的结构可以被更好的优化并且模块化化,同时在解码器中上采样层的参数也可以再被进一步调试,以找到更优的模型。除此之外,对于本样本的增强手段也可以被进一步调试,考虑到整个样本数据库,包括训练集与测试集的图片都较为相似,这是MRI图像的特性,并且图片的清晰度等特征也较为统一,因此在数据增强操作中,添加非刚体转换(ElasticTransform,GridDistortion and OpticalDistortion)与非空间性转换的意义不大,同时添加噪声的操作的必要性也非常低,所以只对数据进行垂直翻转就可以达到数据增强的目的。比较有趣的一点是,在本次任务中,无论是Unet还是ConvNeXt++模型的训练精准度都很高,这说明ConvNeXt++的潜力可能没有被充分发挥,因为从模型结构的角度来看,ConvNeXt++要比Unet更加复杂同时更加严谨。这可能也与数据集的标准程度有关,因此ConvNeXt++的潜力与其后续的完善发展,仍需要面对更加丰富多样的数据集的挑战与磨练。ConvNeXt++模型的更加客观的表现还需要与更多其他模型进行比较。最后,受限于时间限制,使用更大的epoch,不同size的batch等操作对模型进行多次训练也没办法实施。目前的ConvNeXt++模型或许是个不完美的模型,它的潜力仍然是有待发掘的。# 引用自我们组的group report
接下来是代码,模型通过TensorFlow搭建(tf可坑死我了,快用torch!)