文章目录
paddle2.0高层API实现ResNet50(十二生肖分类实战)
『深度学习7日打卡营·快速入门特辑』
零基础解锁深度学习神器飞桨框架高层API,七天时间助你掌握CV、NLP领域最火模型及应用。
- 掌握深度学习常用模型基础知识
- 熟练掌握一种国产开源深度学习框架
- 具备独立完成相关深度学习任务的能力
- 能用所学为AI加一份年味

① 问题定义
十二生肖分类的本质是图像分类任务,我们采用CNN网络结构进行相关实践。
② 数据准备
2.1 解压缩数据集
我们将网上获取的数据集以压缩包的方式上传到aistudio数据集中,并加载到我们的项目内。
在使用之前我们进行数据集压缩包的一个解压。
!unzip -q -o data/data68755/signs.zip
2.2 数据标注
我们先看一下解压缩后的数据集长成什么样子。
.
├── test
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
├── train
│ ├── dog
│ ├── dragon
│ ├── goat
│ ├── horse
│ ├── monkey
│ ├── ox
│ ├── pig
│ ├── rabbit
│ ├── ratt
│ ├── rooster
│ ├── snake
│ └── tiger
└── valid
├── dog
├── dragon
├── goat
├── horse
├── monkey
├── ox
├── pig
├── rabbit
├── ratt
├── rooster
├── snake
└── tiger
数据集分为train、valid、test三个文件夹,每个文件夹内包含12个分类文件夹,每个分类文件夹内是具体的样本图片。
我们对这些样本进行一个标注处理,最终生成train.txt/valid.txt/test.txt三个数据标注文件。
# %cd work
!ls
1512224.ipynb config.py data dataset.py __MACOSX __pycache__ signs work
import io
import os
from PIL import Image
from config import get
# 数据集根目录
DATA_ROOT = 'signs'
# 标签List
LABEL_MAP = get('LABEL_MAP')
# 标注生成函数
def generate_annotation(mode):
# 建立标注文件
with open('{}/{}.txt'.format(DATA_ROOT, mode), 'w') as f:
# 对应每个用途的数据文件夹,train/valid/test
train_dir = '{}/{}'.format(DATA_ROOT, mode)
# 遍历文件夹,获取里面的分类文件夹
for path in os.listdir(train_dir):
# 标签对应的数字索引,实际标注的时候直接使用数字索引
label_index = LABEL_MAP.index(path)
# 图像样本所在的路径
image_path = '{}/{}'.format(train_dir, path)
# 遍历所有图像
for image in os.listdir(image_path):
# 图像完整路径和名称
image_file = '{}/{}'.format(image_path, image)
try:
# 验证图片格式是否ok
with open(image_file, 'rb') as f_img:
image = Image.open(io.BytesIO(f_img.read()))
image.load()
if image.mode == 'RGB':
f.write('{}\t{}\n'.format(image_file, label_index))
except:
continue
generate_annotation('train') # 生成训练集标注文件
generate_annotation('valid') # 生成验证集标注文件
generate_annotation('test') # 生成测试集标注文件
2.3 数据集定义
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
2.3.1 导入相关库
import paddle
import numpy as np
from config import get
paddle.__version__
'2.0.0'
2.3.2 导入数据集的定义实现
我们数据集的代码实现是在dataset.py中。
数据增强data_augumentation为:
self.transforms = T.Compose([
T.RandomResizedCrop(IMAGE_SIZE), # 随机裁剪大小
T.RandomHorizontalFlip(0.5), # 随机水平翻转
T.ToTensor(), # 数据的格式转换和标准化 HWC => CHW
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 图像归一化
])
from dataset import ZodiacDataset
2.3.3 实例化数据集类
根据所使用的数据集需求实例化数据集类,并查看总样本量。
train_dataset = ZodiacDataset(mode='train')
valid_dataset = ZodiacDataset(mode='valid')
print('训练数据集:{}张;验证数据集:{}张'.format(len(train_dataset), len(valid_dataset)))
训练数据集:7096张;验证数据集:639张
③ 模型选择和开发
3.1 网络构建
本次我们使用ResNet50网络来完成我们的案例实践。
1)ResNet系列网络

2)ResNet50结构

3)残差区块
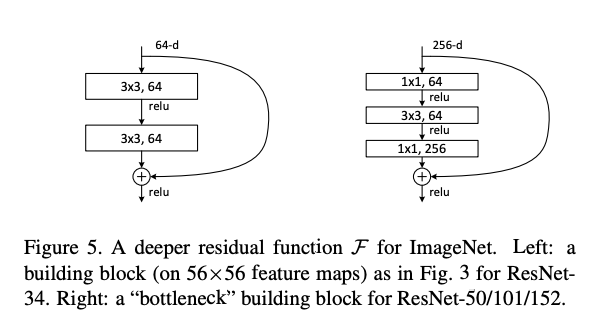
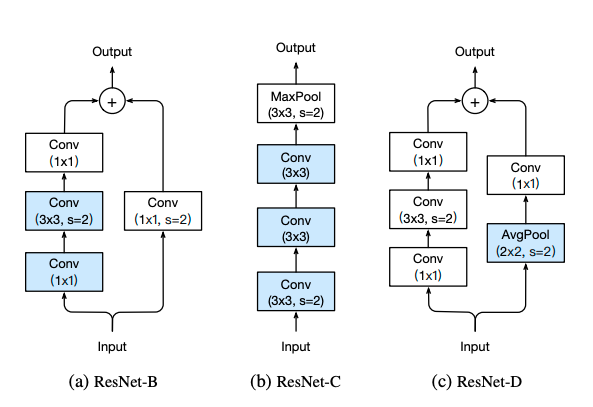
4)ResNet其他版本

# 请补齐模型实例化代码
network = paddle.vision.models.resnet50(num_classes=get('num_classes'), pretrained=True)
100%|██████████| 151272/151272 [00:03<00:00, 41104.37it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for fc.weight. fc.weight receives a shape [2048, 1000], but the expected shape is [2048, 12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for fc.bias. fc.bias receives a shape [1000], but the expected shape is [12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
模型可视化
model = paddle.Model(network)
model.summary((-1, ) + tuple(get('image_shape')))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408
BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096
BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-5 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
Conv2D-2 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0
Conv2D-6 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-8 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-8 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-9 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-4 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-11 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-11 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-13 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,768
BatchNorm2D-13 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-14 [[1, 128, 56, 56]] [1, 128, 28, 28] 147,456
BatchNorm2D-14 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-15 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-15 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
Conv2D-12 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,072
BatchNorm2D-12 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-4 [[1, 256, 56, 56]] [1, 512, 28, 28] 0
Conv2D-16 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-16 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-18 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-18 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-19 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-19 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-21 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-21 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-22 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-22 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-8 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-24 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-24 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-26 [[1, 512, 28, 28]] [1, 256, 28, 28] 131,072
BatchNorm2D-26 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-27 [[1, 256, 28, 28]] [1, 256, 14, 14] 589,824
BatchNorm2D-27 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-28 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-28 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
Conv2D-25 [[1, 512, 28, 28]] [1, 1024, 14, 14] 524,288
BatchNorm2D-25 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-8 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0
Conv2D-29 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-29 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-31 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-31 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-32 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-32 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-34 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-34 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-35 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-35 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-37 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-37 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-38 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-38 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-40 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-40 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-41 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-41 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-14 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-43 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-43 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-45 [[1, 1024, 14, 14]] [1, 512, 14, 14] 524,288
BatchNorm2D-45 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-46 [[1, 512, 14, 14]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-46 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-47 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-47 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
Conv2D-44 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,097,152
BatchNorm2D-44 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-14 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0
Conv2D-48 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576
BatchNorm2D-48 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-50 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-50 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-51 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576
BatchNorm2D-51 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-17 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-53 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-53 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
AdaptiveAvgPool2D-1 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0
Linear-1 [[1, 2048]] [1, 12] 24,588
===============================================================================
Total params: 23,585,740
Trainable params: 23,479,500
Non-trainable params: 106,240
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 261.48
Params size (MB): 89.97
Estimated Total Size (MB): 352.02
-------------------------------------------------------------------------------
{'total_params': 23585740, 'trainable_params': 23479500}
超参数配置
CONFIG = {
'model_save_dir': "./output/zodiac",
'num_classes': 12,
'total_images': 7096,
'epochs': 20,
'batch_size': 32,
'image_shape': [3, 224, 224],
'LEARNING_RATE': {
'params': {
'lr': 0.00375
}
},
'OPTIMIZER': {
'params': {
'momentum': 0.9
},
'regularizer': {
'function': 'L2',
'factor': 0.000001
}
},
'LABEL_MAP': [
"ratt",
"ox",
"tiger",
"rabbit",
"dragon",
"snake",
"horse",
"goat",
"monkey",
"rooster",
"dog",
"pig",
]
}
④ 模型训练和优化
EPOCHS = get('epochs')
BATCH_SIZE = get('batch_size')
# 请补齐模型训练过程代码
def create_optim(parameters):
step_each_epoch = get('total_images') // get('batch_size')
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=get('LEARNING_RATE.params.lr'),
T_max=step_each_epoch * EPOCHS)
return paddle.optimizer.Momentum(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(get('OPTIMIZER.regularizer.factor')))
# 模型训练配置
model.prepare(create_optim(network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, 5))) # 评估指标
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
valid_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/20
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:636: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
step 222/222 [==============================] - loss: 0.5499 - acc_top1: 0.7851 - acc_top5: 0.9548 - 734ms/step
save checkpoint at /home/aistudio/chk_points/0
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3935 - acc_top1: 0.9092 - acc_top5: 0.9922 - 812ms/step
Eval samples: 639
Epoch 2/20
step 222/222 [==============================] - loss: 0.3459 - acc_top1: 0.8519 - acc_top5: 0.9790 - 732ms/step
save checkpoint at /home/aistudio/chk_points/1
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.7412 - acc_top1: 0.8983 - acc_top5: 0.9890 - 833ms/step
Eval samples: 639
Epoch 3/20
step 222/222 [==============================] - loss: 0.4244 - acc_top1: 0.8671 - acc_top5: 0.9817 - 728ms/step
save checkpoint at /home/aistudio/chk_points/2
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5254 - acc_top1: 0.9218 - acc_top5: 0.9984 - 819ms/step
Eval samples: 639
Epoch 4/20
step 222/222 [==============================] - loss: 0.2774 - acc_top1: 0.8878 - acc_top5: 0.9858 - 738ms/step
save checkpoint at /home/aistudio/chk_points/3
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3364 - acc_top1: 0.9280 - acc_top5: 0.9969 - 823ms/step
Eval samples: 639
Epoch 5/20
step 222/222 [==============================] - loss: 0.2692 - acc_top1: 0.8922 - acc_top5: 0.9884 - 728ms/step
save checkpoint at /home/aistudio/chk_points/4
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2550 - acc_top1: 0.9311 - acc_top5: 0.9969 - 804ms/step
Eval samples: 639
Epoch 6/20
step 222/222 [==============================] - loss: 0.5775 - acc_top1: 0.9121 - acc_top5: 0.9894 - 727ms/step
save checkpoint at /home/aistudio/chk_points/5
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5690 - acc_top1: 0.9531 - acc_top5: 0.9969 - 821ms/step
Eval samples: 639
Epoch 7/20
step 222/222 [==============================] - loss: 0.2791 - acc_top1: 0.9136 - acc_top5: 0.9897 - 731ms/step
save checkpoint at /home/aistudio/chk_points/6
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5091 - acc_top1: 0.9609 - acc_top5: 0.9969 - 820ms/step
Eval samples: 639
Epoch 8/20
step 222/222 [==============================] - loss: 0.1944 - acc_top1: 0.9253 - acc_top5: 0.9920 - 734ms/step
save checkpoint at /home/aistudio/chk_points/7
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2852 - acc_top1: 0.9531 - acc_top5: 0.9953 - 821ms/step
Eval samples: 639
Epoch 9/20
step 222/222 [==============================] - loss: 0.3202 - acc_top1: 0.9287 - acc_top5: 0.9927 - 735ms/step
save checkpoint at /home/aistudio/chk_points/8
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.4450 - acc_top1: 0.9531 - acc_top5: 0.9969 - 824ms/step
Eval samples: 639
Epoch 10/20
step 222/222 [==============================] - loss: 0.1250 - acc_top1: 0.9359 - acc_top5: 0.9925 - 745ms/step
save checkpoint at /home/aistudio/chk_points/9
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.4062 - acc_top1: 0.9609 - acc_top5: 0.9953 - 844ms/step
Eval samples: 639
Epoch 11/20
step 222/222 [==============================] - loss: 0.0311 - acc_top1: 0.9366 - acc_top5: 0.9917 - 737ms/step
save checkpoint at /home/aistudio/chk_points/10
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1610 - acc_top1: 0.9577 - acc_top5: 1.0000 - 831ms/step
Eval samples: 639
Epoch 12/20
step 222/222 [==============================] - loss: 0.2705 - acc_top1: 0.9479 - acc_top5: 0.9938 - 726ms/step
save checkpoint at /home/aistudio/chk_points/11
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1312 - acc_top1: 0.9577 - acc_top5: 1.0000 - 811ms/step
Eval samples: 639
Epoch 13/20
step 222/222 [==============================] - loss: 0.1966 - acc_top1: 0.9548 - acc_top5: 0.9942 - 729ms/step
save checkpoint at /home/aistudio/chk_points/12
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3287 - acc_top1: 0.9562 - acc_top5: 1.0000 - 833ms/step
Eval samples: 639
Epoch 14/20
step 222/222 [==============================] - loss: 0.2755 - acc_top1: 0.9563 - acc_top5: 0.9956 - 740ms/step
save checkpoint at /home/aistudio/chk_points/13
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1597 - acc_top1: 0.9546 - acc_top5: 0.9969 - 811ms/step
Eval samples: 639
Epoch 15/20
step 222/222 [==============================] - loss: 0.1340 - acc_top1: 0.9589 - acc_top5: 0.9945 - 741ms/step
save checkpoint at /home/aistudio/chk_points/14
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3858 - acc_top1: 0.9531 - acc_top5: 0.9937 - 828ms/step
Eval samples: 639
Epoch 16/20
step 222/222 [==============================] - loss: 0.0603 - acc_top1: 0.9600 - acc_top5: 0.9975 - 741ms/step
save checkpoint at /home/aistudio/chk_points/15
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1964 - acc_top1: 0.9656 - acc_top5: 0.9984 - 826ms/step
Eval samples: 639
Epoch 17/20
step 222/222 [==============================] - loss: 0.0447 - acc_top1: 0.9581 - acc_top5: 0.9955 - 740ms/step
save checkpoint at /home/aistudio/chk_points/16
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1808 - acc_top1: 0.9703 - acc_top5: 0.9969 - 818ms/step
Eval samples: 639
Epoch 18/20
step 222/222 [==============================] - loss: 0.5067 - acc_top1: 0.9625 - acc_top5: 0.9956 - 741ms/step
save checkpoint at /home/aistudio/chk_points/17
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2021 - acc_top1: 0.9656 - acc_top5: 0.9984 - 833ms/step
Eval samples: 639
Epoch 19/20
step 222/222 [==============================] - loss: 0.0673 - acc_top1: 0.9593 - acc_top5: 0.9946 - 738ms/step
save checkpoint at /home/aistudio/chk_points/18
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5409 - acc_top1: 0.9577 - acc_top5: 0.9969 - 836ms/step
Eval samples: 639
Epoch 20/20
step 222/222 [==============================] - loss: 0.1440 - acc_top1: 0.9596 - acc_top5: 0.9965 - 742ms/step
save checkpoint at /home/aistudio/chk_points/19
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2487 - acc_top1: 0.9640 - acc_top5: 0.9984 - 809ms/step
Eval samples: 639
save checkpoint at /home/aistudio/chk_points/final
VisualDL训练过程可视化展示
visualdl = paddle.callbacks.VisualDL(log_dir='VisualDL_log')
模型存储
将我们训练得到的模型进行保存,以便后续评估和测试使用。
model.save(get('model_save_dir'))
⑤ 模型评估和测试
5.1 批量预测测试
5.1.1 测试数据集
predict_dataset = ZodiacDataset(mode='test')
print('测试数据集样本量:{}'.format(len(predict_dataset)))
测试数据集样本量:646
5.1.2 执行预测
from paddle.static import InputSpec
# 请补充网络结构
network = paddle.vision.models.resnet50(num_classes=get('num_classes'))
# 模型封装
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])
# 请补充模型文件加载代码
# 训练好的模型加载
model_2.load(get('model_save_dir'))
# 模型配置
model_2.prepare()
# 执行预测
result = model_2.predict(predict_dataset)
Predict begin...
step 646/646 [==============================] - 33ms/step
Predict samples: 646
# 样本映射
LABEL_MAP = get('LABEL_MAP')
# 随机取样本展示
indexs = np.random.randint(1, 646, size=20)
for idx in indexs:
predict_label = np.argmax(result[0][idx])
real_label = predict_dataset[idx][1]
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))
样本ID:393, 真实标签:pig, 预测值:pig
样本ID:107, 真实标签:monkey, 预测值:monkey
样本ID:466, 真实标签:tiger, 预测值:tiger
样本ID:279, 真实标签:horse, 预测值:horse
样本ID:425, 真实标签:pig, 预测值:pig
样本ID:127, 真实标签:monkey, 预测值:monkey
样本ID:432, 真实标签:tiger, 预测值:tiger
样本ID:377, 真实标签:pig, 预测值:pig
样本ID:99, 真实标签:dragon, 预测值:dragon
样本ID:322, 真实标签:dog, 预测值:dog
样本ID:460, 真实标签:tiger, 预测值:tiger
样本ID:554, 真实标签:ox, 预测值:ox
样本ID:77, 真实标签:dragon, 预测值:dragon
样本ID:335, 真实标签:dog, 预测值:dog
样本ID:398, 真实标签:pig, 预测值:pig
样本ID:176, 真实标签:snake, 预测值:snake
样本ID:207, 真实标签:snake, 预测值:snake
样本ID:29, 真实标签:rooster, 预测值:rooster
样本ID:476, 真实标签:tiger, 预测值:tiger
样本ID:424, 真实标签:pig, 预测值:pig
⑥ 模型部署
model_2.save('infer/zodiac', training=False)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/math_op_patch.py:298: UserWarning: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/vision/models/resnet.py:145
The behavior of expression A + B has been unified with elementwise_add(X, Y, axis=-1) from Paddle 2.0. If your code works well in the older versions but crashes in this version, try to use elementwise_add(X, Y, axis=0) instead of A + B. This transitional warning will be dropped in the future.
op_type, op_type, EXPRESSION_MAP[method_name]))
MobileNet_V2测试
由于ResNet模型和计算量都比较大,在AI_Studio的GPU下跑20个Epoch还是跑了很久,这里测试一下用MobileNet来进行训练,测试运算效率和准确性。
network = paddle.vision.models.mobilenet_v2(num_classes=get('num_classes'), pretrained=True)
model_lite = paddle.Model(network)
model_lite.summary((-1, ) + tuple(get('image_shape')))
100%|██████████| 20795/20795 [00:00<00:00, 44614.48it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for classifier.1.weight. classifier.1.weight receives a shape [1280, 1000], but the expected shape is [1280, 12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for classifier.1.bias. classifier.1.bias receives a shape [1000], but the expected shape is [12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-160 [[1, 3, 224, 224]] [1, 32, 112, 112] 864
BatchNorm2D-107 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-161 [[1, 32, 112, 112]] [1, 32, 112, 112] 288
BatchNorm2D-108 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-162 [[1, 32, 112, 112]] [1, 16, 112, 112] 512
BatchNorm2D-109 [[1, 16, 112, 112]] [1, 16, 112, 112] 64
InvertedResidual-1 [[1, 32, 112, 112]] [1, 16, 112, 112] 0
Conv2D-163 [[1, 16, 112, 112]] [1, 96, 112, 112] 1,536
BatchNorm2D-110 [[1, 96, 112, 112]] [1, 96, 112, 112] 384
ReLU6-3 [[1, 96, 112, 112]] [1, 96, 112, 112] 0
Conv2D-164 [[1, 96, 112, 112]] [1, 96, 56, 56] 864
BatchNorm2D-111 [[1, 96, 56, 56]] [1, 96, 56, 56] 384
ReLU6-4 [[1, 96, 56, 56]] [1, 96, 56, 56] 0
Conv2D-165 [[1, 96, 56, 56]] [1, 24, 56, 56] 2,304
BatchNorm2D-112 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
InvertedResidual-2 [[1, 16, 112, 112]] [1, 24, 56, 56] 0
Conv2D-166 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-113 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-5 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-167 [[1, 144, 56, 56]] [1, 144, 56, 56] 1,296
BatchNorm2D-114 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-6 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-168 [[1, 144, 56, 56]] [1, 24, 56, 56] 3,456
BatchNorm2D-115 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
InvertedResidual-3 [[1, 24, 56, 56]] [1, 24, 56, 56] 0
Conv2D-169 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-116 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-7 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-170 [[1, 144, 56, 56]] [1, 144, 28, 28] 1,296
BatchNorm2D-117 [[1, 144, 28, 28]] [1, 144, 28, 28] 576
ReLU6-8 [[1, 144, 28, 28]] [1, 144, 28, 28] 0
Conv2D-171 [[1, 144, 28, 28]] [1, 32, 28, 28] 4,608
BatchNorm2D-118 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-4 [[1, 24, 56, 56]] [1, 32, 28, 28] 0
Conv2D-172 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-119 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-9 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-173 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-120 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-10 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-174 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-121 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-5 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-175 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-122 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-11 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-176 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-123 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-12 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-177 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-124 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-6 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-178 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-125 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-13 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-179 [[1, 192, 28, 28]] [1, 192, 14, 14] 1,728
BatchNorm2D-126 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU6-14 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-180 [[1, 192, 14, 14]] [1, 64, 14, 14] 12,288
BatchNorm2D-127 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-7 [[1, 32, 28, 28]] [1, 64, 14, 14] 0
Conv2D-181 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-128 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-15 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-182 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-129 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-16 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-183 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-130 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-8 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-184 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-131 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-17 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-185 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-132 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-18 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-186 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-133 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-9 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-187 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-134 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-19 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-188 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-135 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-20 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-189 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-136 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-10 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-190 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-137 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-21 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-191 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-138 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-22 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-192 [[1, 384, 14, 14]] [1, 96, 14, 14] 36,864
BatchNorm2D-139 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-11 [[1, 64, 14, 14]] [1, 96, 14, 14] 0
Conv2D-193 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-140 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-23 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-194 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-141 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-24 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-195 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-142 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-12 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-196 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-143 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-25 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-197 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-144 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-26 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-198 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-145 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-13 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-199 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-146 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-27 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-200 [[1, 576, 14, 14]] [1, 576, 7, 7] 5,184
BatchNorm2D-147 [[1, 576, 7, 7]] [1, 576, 7, 7] 2,304
ReLU6-28 [[1, 576, 7, 7]] [1, 576, 7, 7] 0
Conv2D-201 [[1, 576, 7, 7]] [1, 160, 7, 7] 92,160
BatchNorm2D-148 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-14 [[1, 96, 14, 14]] [1, 160, 7, 7] 0
Conv2D-202 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-149 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-29 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-203 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-150 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-30 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-204 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-151 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-15 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-205 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-152 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-31 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-206 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-153 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-32 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-207 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-154 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-16 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-208 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-155 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-33 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-209 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-156 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-34 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-210 [[1, 960, 7, 7]] [1, 320, 7, 7] 307,200
BatchNorm2D-157 [[1, 320, 7, 7]] [1, 320, 7, 7] 1,280
InvertedResidual-17 [[1, 160, 7, 7]] [1, 320, 7, 7] 0
Conv2D-211 [[1, 320, 7, 7]] [1, 1280, 7, 7] 409,600
BatchNorm2D-158 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 5,120
ReLU6-35 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 0
AdaptiveAvgPool2D-3 [[1, 1280, 7, 7]] [1, 1280, 1, 1] 0
Dropout-1 [[1, 1280]] [1, 1280] 0
Linear-4 [[1, 1280]] [1, 12] 15,372
===============================================================================
Total params: 2,273,356
Trainable params: 2,205,132
Non-trainable params: 68,224
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 152.87
Params size (MB): 8.67
Estimated Total Size (MB): 162.12
-------------------------------------------------------------------------------
{'total_params': 2273356, 'trainable_params': 2205132}
EPOCHS = 10
BATCH_SIZE = 32
# 请补齐模型训练过程代码
# 模型训练配置
model_lite.prepare(paddle.optimizer.Adam(learning_rate=0.0001, parameters=model_lite.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, 5))) # 评估指标
# 训练可视化VisualDL工具的回调函数
visualdl = paddle.callbacks.VisualDL(log_dir='./mobilenet/visualdl_log')
# 启动模型全流程训练
model_lite.fit( train_dataset, # 训练数据集
valid_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./mobilenet/chk_points/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/10
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:636: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
step 222/222 [==============================] - loss: 0.2848 - acc_top1: 0.8271 - acc_top5: 0.9762 - 690ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/0
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5077 - acc_top1: 0.9124 - acc_top5: 0.9906 - 803ms/step
Eval samples: 639
Epoch 2/10
step 222/222 [==============================] - loss: 0.2549 - acc_top1: 0.8541 - acc_top5: 0.9800 - 689ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/1
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3955 - acc_top1: 0.9218 - acc_top5: 0.9937 - 813ms/step
Eval samples: 639
Epoch 3/10
step 222/222 [==============================] - loss: 0.3388 - acc_top1: 0.8660 - acc_top5: 0.9842 - 693ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/2
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2251 - acc_top1: 0.9390 - acc_top5: 0.9937 - 817ms/step
Eval samples: 639
Epoch 4/10
step 222/222 [==============================] - loss: 0.6369 - acc_top1: 0.8773 - acc_top5: 0.9845 - 688ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/3
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3293 - acc_top1: 0.9311 - acc_top5: 0.9937 - 813ms/step
Eval samples: 639
Epoch 5/10
step 222/222 [==============================] - loss: 0.4066 - acc_top1: 0.8908 - acc_top5: 0.9872 - 696ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/4
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.2782 - acc_top1: 0.9343 - acc_top5: 0.9937 - 808ms/step
Eval samples: 639
Epoch 6/10
step 222/222 [==============================] - loss: 0.3100 - acc_top1: 0.8961 - acc_top5: 0.9876 - 686ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/5
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.4607 - acc_top1: 0.9390 - acc_top5: 0.9937 - 810ms/step
Eval samples: 639
Epoch 7/10
step 222/222 [==============================] - loss: 0.1829 - acc_top1: 0.9016 - acc_top5: 0.9887 - 688ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/6
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.3421 - acc_top1: 0.9264 - acc_top5: 0.9969 - 815ms/step
Eval samples: 639
Epoch 8/10
step 222/222 [==============================] - loss: 0.4560 - acc_top1: 0.8932 - acc_top5: 0.9870 - 688ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/7
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1464 - acc_top1: 0.9343 - acc_top5: 0.9922 - 830ms/step
Eval samples: 639
Epoch 9/10
step 222/222 [==============================] - loss: 0.4075 - acc_top1: 0.9040 - acc_top5: 0.9873 - 686ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/8
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.5118 - acc_top1: 0.9468 - acc_top5: 0.9953 - 820ms/step
Eval samples: 639
Epoch 10/10
step 222/222 [==============================] - loss: 0.0882 - acc_top1: 0.9094 - acc_top5: 0.9866 - 686ms/step
save checkpoint at /home/aistudio/mobilenet/chk_points/9
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 20/20 [==============================] - loss: 0.1651 - acc_top1: 0.9468 - acc_top5: 0.9953 - 821ms/step
Eval samples: 639
save checkpoint at /home/aistudio/mobilenet/chk_points/final
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-49-266b4a21aaf0> in <module>
23 callbacks=[visualdl]) # 回调函数使用
24
---> 25 model.save(get('./mobilenet/model'))
~/config.py in get(full_path)
43 config = CONFIG
44
---> 45 config = config[name]
46
47 return config
KeyError: ''
model.save('./mobilenet/model')
# 模型评估
val = model_lite.evaluate(valid_dataset, verbose=1)
print(val)
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 639/639 [==============================] - loss: 1.0871e-04 - acc_top1: 0.9374 - acc_top5: 0.9890 - 46ms/step
Eval samples: 639
{'loss': [0.000108712964], 'acc_top1': 0.9374021909233177, 'acc_top5': 0.9890453834115805}
# 执行预测
pred = model_lite.predict(predict_dataset)
# 样本映射
LABEL_MAP = get('LABEL_MAP')
# 随机取样本展示
indexs = np.random.randint(1, 646, size=20)
for idx in indexs:
predict_label = np.argmax(pred[0][idx])
real_label = predict_dataset[idx][1]
real_label = predict_dataset[idx][1]
print('样本ID:{}, 真实标签:{}, 预测值:{}'.format(idx, LABEL_MAP[real_label], LABEL_MAP[predict_label]))
Predict begin...
step 646/646 [==============================] - 42ms/step
Predict samples: 646
样本ID:611, 真实标签:ratt, 预测值:dragon
样本ID:42, 真实标签:rooster, 预测值:dragon
样本ID:11, 真实标签:rooster, 预测值:rooster
样本ID:625, 真实标签:ratt, 预测值:ratt
样本ID:263, 真实标签:goat, 预测值:goat
样本ID:635, 真实标签:ratt, 预测值:ratt
样本ID:78, 真实标签:dragon, 预测值:dragon
样本ID:567, 真实标签:ox, 预测值:ox
样本ID:280, 真实标签:horse, 预测值:horse
样本ID:406, 真实标签:pig, 预测值:pig
样本ID:167, 真实标签:snake, 预测值:snake
样本ID:19, 真实标签:rooster, 预测值:rooster
样本ID:41, 真实标签:rooster, 预测值:rooster
样本ID:406, 真实标签:pig, 预测值:pig
样本ID:497, 真实标签:rabbit, 预测值:rabbit
样本ID:71, 真实标签:dragon, 预测值:dragon
样本ID:300, 真实标签:horse, 预测值:horse
样本ID:247, 真实标签:goat, 预测值:goat
样本ID:450, 真实标签:tiger, 预测值:tiger
样本ID:82, 真实标签:dragon, 预测值:dragon