目标检测 YOLOv5 - 如何提高模型的指标,提高精确率,召回率,mAP等
文中包括了YOLOv5作者分享的提高模型指标小技巧和吴恩达(Andrew Ng)在做缺陷检测项目( steel sheets for defects)时遇到的需要提高模型指标的问题是如何解决的。
1 YOLOv5获得最佳训练效果指南
大多数情况下,只要数据集足够大且良好标注(provided your dataset is sufficiently large and well labelled),就可以在不更改模型或训练设置的情况下获得良好的结果。如果一开始没有得到好的结果,在考虑任何更改之前,首先使用所有默认设置进行训练。这有助于建立性能baseline和需要改进的地方。
YOLOv5提供了大量的信息包括训练损失, 验证损失, 精确率(P), 召回率(R), mAP等可视化结果, 包括PR曲线(PR curve),混淆矩阵(confusion matrix), 马赛克训练, 测试结果等数据集统计图像。这些信息的图像所在目录是yolov5/runs/Train/exp
1.1 数据集方面
1.1.1 每个类别的图像
- 每个类别的图像张数大于1500张
1.1.2 每个类别的实例
- 我们人工标注的目标框就是实例,每个类别的实例要大于10000张。
1.1.3 图像的多样性
- 数据集必须展现出部署环境,推荐来自一天中不同时间、不同季节、不同天气、不同光照、不同角度、不同数据源(在线抓取、本地收集、不同相机)等的图像。
1.1.4 标注的一致性
- 所有图像中所有类的所有实例都必须标注。部分标注将不起作用。
1.1.5 标注的精度
- 边框必须紧密地包围每个目标。目标和边框之间不应存在任何空。任何目标都不应缺少标签。
- 背景图像:背景图像是图像里没有感兴趣目标的图像,加到数据集以减少误报 (FP) 。建议约 0-10% 的背景图像,以帮助减少FP(COCO数据集有1000张背景图像供参考,占总数的 1%)。
1.2 模型选择
- 更大的模型,如YOLOv5x,在几乎所有情况下都会产生更好的结果,但参数更多,运行速度也更慢。对于移动应用推荐YOLOv5s/m;对于云或桌面应用,推荐YOLOv5l/x。
- 对于所有YOLOv5系列模型全面的比较,请看https://github.com/ultralytics/yolov5#pretrained-checkpoints
1.3 训练设置
- 在修改任何内容之前,首先使用默认设置进行训练,以建立性能baseline。(
first train with default settings to establish a performance baseline) - training.py的argparser中提供了训练设置的完整列表。
1.3.1 epochs:
- 从300个epoch开始。如果过早过拟合,那么可以减少epochs。如果在300个epoch后没有发生过拟合,则训练更长时间,即 600、1200个等epoch。
1.3.2 图像大小
- COCO以–img 640的原始分辨率训练,尽管由于数据集中有大量的小目标,它可以从更高分辨率(如-img 1280)的训练中受益。如果有许多小目标,则自定义数据集将从原始或更高分辨率的训练中受益。最佳推理结果是训练时设置的 --img x与推理时设置的–img x相同,例如如果–img 1280训练,则在–img 1280进行推理测试。
1.3.3 batch size
- 使用自己的硬件资源允许的最大Batch size。小的Batch size会产生较差的batchnorm统计,应该避免。
1.3.4 超参数
- 默认超参数位于
hpy.scratch.yaml中。建议先使用默认超参数进行训练,然后再考虑修改任何参数。一般来说,增加augmentation超参数将减少和延迟过度拟合,从而允许更长的训练时间和更高的最终mAP。减少loss component gain超参数(如hyp[‘obj’])将有助于减少对特定loss component的过度拟合。
2 以数据为中心的AI(Data-Centric AI)
- 以数据为中心的AI(data-centric AI)这一概念是吴恩达(Andrew Ng)的提出的。
AI system = Code + Data
Code = model / algorithm
提高模型指标的两种路径
以模型为中心
- 通过改进模型来提升表现(
Asks how you can change the model to improve performance.)
以数据为中心
- 通过改进数据来提升表现(
Asks how you can change or improve your data to improve performance.)
2.1 听听大佬怎么说的
- 训练神经网络的第一步是根本不是接触任何神经网络代码,而是从彻底检查数据开始。这一步至关重要。(
The first step to training a neural net is to not touch any neural net code at all and instead begin by thoroughly inspecting your data. This step is critical.) - 你的模型架构足够好了。总而言之,不要试图和一屋子的博士比聪明。相反,在尝试改进模型之前,请确保数据的质量是一流的。
(your model architecture is good enough.To summarize — don’t try to outsmart a room full of PhDs. Instead, make sure the quality of your data is top-notch before trying to improve the model.) - 以数据为中心的ML归结为以下三点:
(1)数据飞轮:同步开发模型和数据。(The data flywheel: develop model and data in tandem)
(2)您可以自己对数据进行注释,至少在开始时是这样。(Annotate the data yourself, at least at the beginning)
(3)使用工具尽可能减少MLOps的麻烦(Use tools to reduce the MLOps hassle as much as possible)
注释
tandem: adv. 二马纵列地,这里翻译成两项工作同时展开 MLOps: 全称是`Machine Learning Operations
Andrew` Ng在他的ppt中这样描述MLOps最重要的任务是在ML项目生命周期的所有阶段提供高质量的数据。(MLOps’ most important task is to make high quality data available through all stages of the ML project lifecycle.)
2.2 什么是好的标注
数据数量还是数据质量(Data Quantity vs. Data Quality)
如果要追求数据的质量,我们就必须有严格而统一的标注规则,反之就是指标下降

2.3 deeplearning.ai提供了Andrew Ng在遇到一个检测问题是如何解决的
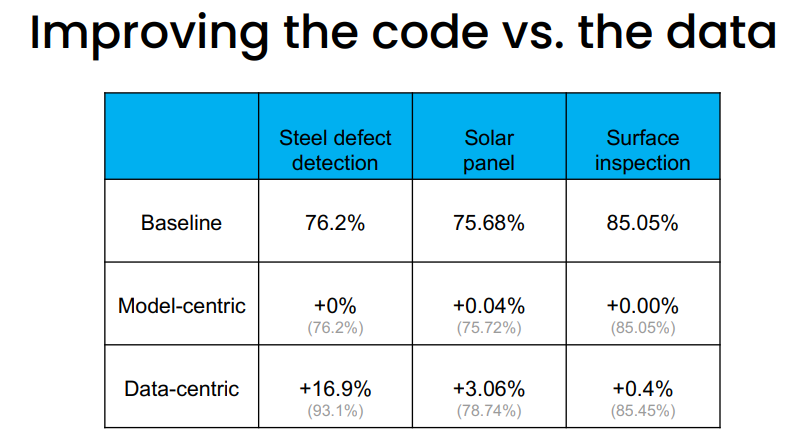
Andrew Ng和他的团队在进行钢铁缺陷检测项目( steel sheets for defects)时,accuracy卡在了76.2%,期望结果是accuracy>=90%。于是他把团队拆分,各个小组做不同的事。一个小组保持模型不变,做new
examples,data augmentation,labeling等提高数据质量的工作,另一个小组保持数据不变,但尝试改进模型。从事数据工作的小组能够将准确率提高到93.1%,而另一个小组却丝毫没能提高baseline。
详细结果看Andrew Ng的ppt,如下图
参考
Stop treating data as a commodity
Andrew Ng MLOps-From-Model-centric-to-Data-centric-AI
A Recipe for Training Neural Networks
YOLOv5 issues
YOLOv5 issues