“ 前文我们使用libtorch来实现的LeNet-5网络、Alexnet网络、Resnet34网络,都是用于图像分类的神经网络。现在,让我们进入深度学习的目标检测系列吧~”
首先我们来讲一下目标检测任务的理解。我们知道,图像分类任务主要是对图像进行识别和分类,那么目标检测呢?后者比前者更加复杂,不仅要分类,还要检测目标的位置,甚至分割出目标的轮廓区域。如下图所示,图中的人、巴士都是我们要检测的目标,在检测出人和巴士在图中位置的同时,还要区分出哪些目标是人,哪些目标是巴士,这就是目标检测任务:

在此系列文章中,我们将使用libtorch来实现yolov5目标检测网络,并对COCO数据集进行训练和目标检测。
01 COCO数据集简介
COCO数据集的全称为Microsoft Common Objects in Context,起源于微软2014年出资标注的Microsoft COCO数据集。
-
数据集包含多张彩色jpg图像,每张图像又可能包含人、猫、狗、马、巴士等80个种类的分类/检测目标。

-
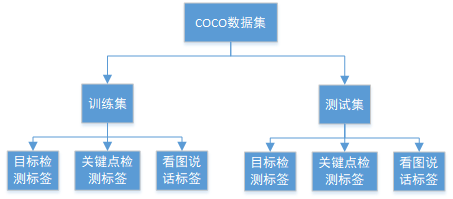
数据集主要分为训练集和测试集两个大部分。
-
训练集和测试集都有对应的标签,分别存储在不同的json文件中。其中标签又分为三大类——目标检测标签、关键点检测标签、看图说话标签,也存储于不同的json文件中。也就是说,COCO数据集作了三种标签,可分别用于目标检测、关键点检测、看图说话这三种任务的训练。
-
COCO数据集的下载地址为:
https://cocodataset.org/#download
通常使用数据集中的以下三个文件:

其中train2017.zip中包含训练集的图片、val2017.zip中包含测试集的图片,annotations_trainval2017.zip中则包含了训练集和测试集的json标签文件,如下图所示。

使用下表对以上标签文件进行分类:
| 训练集标签 | 测试集标签 | |
| 目标检测 | instances_train2017.json | instances_val2017.json |
| 关键点检测 | person_keypoints_train2017.json | person_keypoints_val2017.json |
| 看图说话 | captions_train2017.json | captions_val2017.json |
显然,本系列文章的主题是目标检测,我们要使用的标签文件为instances_train2017.json和instances_val2017.json。本文我们主要来解析json这两个标签文件。
02 COCO数据集目标检测标签json文件解析
前面我们对Cifar-10数据集进行分类时,发现每一个种类的标签就是一个数字,图像和分类标签非常容易对应起来,因此标签的存储方式非常简单。但对于目标检测任务,标签不仅包含分类标签,还包含了检测目标的位置信息,因此不能再像Cifar-10数据集那样存储标签了。
而json是一种轻量级的数据交换格式,可以将不同信息打包成一个个模块,并将这些模块按照一定顺序存储到json文件中,读文件时只需要根据关键字对相应模块进行解析,即可得到该模块的打包信息。
因此,COCO数据集把分类、位置等标签信息存储到json格式的文件,方便训练和测试时进行解析。
instances_train2017.json和instances_val2017.json文件均分为五大部分,这五部分对应的关键字分别为info、licenses、images、annotations、categories。
{
"info" : info,
"licenses" : [license1, license2, license3, ...],
"images" : [image1, image2, image3, ...],
"annotations" : [annataton1, annataton2, annataton3, ...],
"categories" : [category1, category2, category3, ...]
}
-
info部分包含了数据集的年份、版本、作者,以及描述等信息:
info
{
"description": string类型
"url": string类型
"version": string类型
"year": int类型
"contributor": string类型
"date_created": string类型
}
-
licenses部分则包含了数据集的发布证书信息,由于有多个证书,将它们的信息以序列表的形式进行存储,序列表中每个证书的存储形式是一样的:
licenses
{
"url": string 类型
"id": int类型
"name": string 类型
}
-
images部分包含了图像信息,由于有多张图像,将它们的信息以序列表的形式进行存储,序列表中每张图像信息的存储形式是一样的:
images
{
"license": int 类型,表示该图像的liecens证书属于licenses部分中的哪一个证书,对应licenses部分中证书的id号
"file_name": string 类型,图片的文件名,比如000000000001.jpg
"coco_url": string 类型,coco图片链接url
"height": int 类型,图片的高
"width": int 类型,图片的宽
"date_captured": string 类型,图片的获取日期
"flickr_url": string 类型,flickr图片链接url
"id": int 类型,图片id
}
-
annotations部分主要包含了图片中检测目标的分类信息和位置信息,由于有多张图片且每张图片中可能包含多个检测目标,将每个检测目标的信息以序列表的形式进行存储,序列表中每个检测目标信息的存储形式是一样的:
annotations
{
"segmentation": float类型,检测目标的轮廓分割级标签
"area": float类型,检测目标的面积
"iscrowd": int型,0或1:目标是否被遮盖,默认为0
"image_id": 该检测目标所属于的图片的id,对应以上images部分的id信息
"bbox": float型,包含该检测目标的矩形框信息:左上角点的x坐标、y坐标、矩形宽、矩形高
"category_id": 该检测目标所属的类别id
"id": 数据集中每个检测目标的id号
}
-
categories部分主要包含了检测目标的分类信息,由于检测目标总共有80个类别,将每个类别的信息以序列表的形式进行存储,序列表中每个类别信息的存储形式是一样的:
categories
{
"supercategory": string 类型,类别所属的大类,如卡车和轿车都属于机动车这个大类
"id": int类型,类别的id,对应以上annotations部分的category_id
"name": string 类型,类别名称,比如person、dog、cat等
};
由以上可知,在json标签文件的五大部分内容中,我们在目标检测时主要用到的是images、annotations、categories这三部分的信息,分别对应图片信息、检测目标的位置信息、检测目标的分类信息,其中:
-
images部分为序列表,序列表包含多个元素,每个元素对应数据集的一张图片。因此序列表的元素个数与数据集的图片个数一致。
-
annotations部分也为序列表,序列表包含多个元素,每个元素对应数据集的一个检测目标,该检测目标根据image_id对应到images部分的id,使检测目标与图片关联起来,同时根据category_id对应到categories部分的id,使检测目标与类别信息关联起来。因此序列表的元素个数与数据集图片中包含的所有检测目标个数一致。
-
categories部分同样为序列表,序列表包含多个元素,每个元素则对一个类别。因此序列表的元素个数与所有检测目标的类别数(80个类别)一致。

03 json文件解析的代码实现
有很多现成的C++/C库可用于解析json文件,这些库有的需要包含lib文件,有的则需要包含c/cpp/h/hpp文件,使用起来比较麻烦,本人使用的是一个超级轻便简洁的库,只有一个hpp头文件,只需要在cpp中包含该头文件即可调用库中的相关接口对json文件进行解析。该hpp下载的gittee地址为:
https://gitee.com/dzlua/json/blob/master/json.hpp
下载json.hpp头文件之后,在cpp文件中包含该头文件,并在cpp文件开头处加上以下代码即可:
include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/xfeatures2d.hpp>
#include <iostream>
#include <fstream>
#include "json.hpp" //包含头文件
using namespace std;
using json = nlohmann::json; //加上这一行代码
using namespace cv;
我们需要根据上一小节中所讲的文件结构,定义相对应的结构体,然后构造重载函数对json文件的五大部分分别进行解析,并将解析出来的信息保存到结构体中对应的位置,需注意结构体和重载函数均需要定义在同一个namespace中:
namespace ns
{
//第1部分结构体
struct info
{
std::string description;
std::string url;
std::string version;
int year;
std::string contributor;
std::string date_created;
};
//第2部分结构体
struct licenses
{
std::string url;
int id;
std::string name;
};
//第3部分结构体
struct images
{
int license;
std::string file_name;
std::string coco_url;
int height;
int width;
std::string date_captured;
std::string flickr_url;
int id;
};
//第4部分结构体
struct annotations
{
std::vector<float> segmentation;
float area;
int iscrowd;
int image_id;
float bbox[4];
int category_id;
int id;
};
//第5部分结构体
struct categories
{
std::string supercategory;
int id;
std::string name;
};
//json文件的整体结构体
struct coco_label
{
info info_obj;
std::vector<licenses> licences_list; //第2部分序列表(数组)
std::vector<images> images_list; //第3部分序列表(数组)
std::vector<annotations> annotations_list; //第4部分序列表(数组)
std::vector<categories> categories_list; //第5部分序列表(数组)
};
//解析第1部分
void from_json(const json j, info &p)
{
p.description = j.at("description");
p.url = j.at("url");
p.version = j.at("version");
p.year = (int)j.at("year");
p.contributor = j.at("contributor");
p.date_created = j.at("date_created");
}
//解析第2部分序列表中的一个元素
void from_json(const json j, licenses &p)
{
p.url = j.at("url");
p.id = (int)j.at("id");
p.name = j.at("name");
}
//解析第3部分序列表中的一个元素
void from_json(const json j, images &p)
{
p.license = (int)j.at("license");
p.file_name = j.at("file_name");
p.coco_url = j.at("coco_url");
p.height = (int)j.at("height");
p.width = (int)j.at("width");
p.date_captured = j.at("date_captured");
p.flickr_url = j.at("flickr_url");
p.id = (int)j.at("id");
}
//解析第4部分序列表中的一个元素
void from_json(const json j, annotations &p)
{
//segmentation用于分割级目标检测,我们目前只做矩形框级的检测,因此此处暂时不作解析
p.area = (float)j.at("area");
p.iscrowd = (int)j.at("iscrowd");
p.image_id = (int)j.at("image_id");
for (int i = 0; i < j["bbox"].size(); i++)
{
p.bbox[i] = (float)j["bbox"][i]; //x, y, width, height
}
p.category_id = (int)j.at("category_id");
p.id = (int)j.at("id");
}
//解析第5部分序列表中的一个元素
void from_json(const json j, categories &p)
{
p.supercategory = j.at("supercategory");
p.id = (int)j.at("id");
p.name = j.at("name");
}
//解析json文件的总体信息
void from_json(const json j, coco_label &p)
{
//解析第1部分
p.info_obj = j.at("info");
//解析第2部分的所有元素,并存储到结构体数组
p.licences_list.clear();
for (int i = 0; i < j["licenses"].size(); i++)
{
licenses s;
from_json(j["licenses"][i], s);
p.licences_list.push_back(s);
}
//解析第3部分的所有元素,并存储到结构体数组
p.images_list.clear();
for (int i = 0; i < j["images"].size(); i++)
{
images s;
from_json(j["images"][i], s);
p.images_list.push_back(s);
}
//解析第4部分的所有元素,并存储到结构体数组
p.annotations_list.clear();
for (int i = 0; i < j["annotations"].size(); i++)
{
annotations s;
from_json(j["annotations"][i], s);
p.annotations_list.push_back(s);
}
//解析第5部分的所有元素,并存储到结构体数组
p.categories_list.clear();
for (int i = 0; i < j["categories"].size(); i++)
{
categories s;
from_json(j["categories"][i], s);
p.categories_list.push_back(s);
}
}
}
测试代码:
void cjson_test(void)
{
json j;
ifstream jfile("D:/数据/coco/annotations_trainval2017/annotations/instances_val2017.json");
jfile >> j;
ns::coco_label cr;
ns::from_json(j, cr);
cout << "cr.annotations_list[0].image_id: "<< cr.annotations_list[0].image_id <<endl;
cout << "cr.annotations_list[0].category_id: " << cr.annotations_list[0].category_id << endl;
}
运行结果:
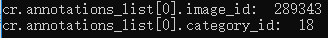
欢迎扫码关注本微信公众号,接下来会不定时更新更加精彩的内容,敬请期待~