atop使用
Linux以其稳定性,越来越多地被用作服务器的操作系统(当然,有人会较真地说一句:Linux只是操作系统内核:)。但使用了Linux作为底层的操作系统,是否我们就能保证我们的服务做到7*24地稳定呢?非也,要知道业务功能是由系统上跑的程序实现的,要实现业务功能的稳定性,选择Linux只是迈出的第一步,我们更多地工作是不让业务程序成为稳定性的短板。
当我们的服务器出现问题的时候,外在的表现是业务功能不能正常提供,内在的原因,从程序的角度看,可能是业务程序的问题(程序自身的bug),也可能是服务器上人为的误操作(不当地执行脚本或命令);从系统资源的角度看,可能是CPU抢占、内存泄漏、磁盘IO读写异常、网络异常等。出现问题后,面对各种各样可能的原因,我们应如何着手进行分析?我们有什么工具进行问题定位吗?
atop简介
本文要介绍的atop就是一款用于监控Linux系统资源与进程的工具,它以一定的频率记录系统的运行状态,所采集的数据包含系统资源(CPU、内存、磁盘和网络)使用情况和进程运行情况,并能以日志文件的方式保存在磁盘中,服务器出现问题后,我们可获取相应的atop日志文件进行分析。atop是一款开源软件,我们可以从这里获得其源码和rpm安装包。
atop使用方法
在安装atop之后,我们在命令行下敲入”atop"命令即可看到系统当前的运行情况:
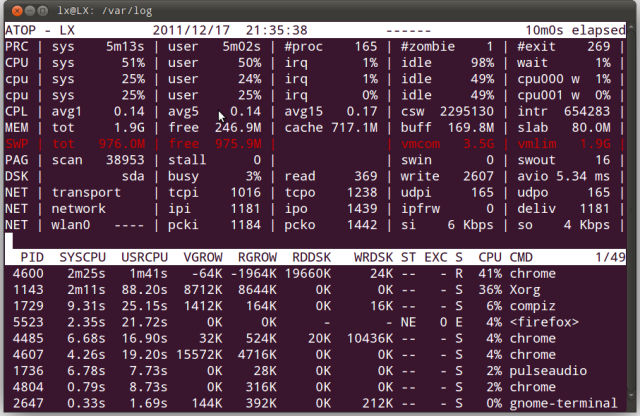
系统资源监控字段含义
上图中列出了不少字段以及数值,各字段的含义是什么?我们应该怎么看?以上每个字段的含义都是相对采样周期而言的,下面我们先来关注上图显示的上半部分。
ATOP行:该列显示了主机名、信息采样日期和时间点和信息收集的频率
PRC行:该列显示进程整体运行情况
- sys:过去10s所有的进程在内核态运行的时间总和
- usr:过去10s所有的进程在用户态的运行时间总和
- #proc:过去10s转换的进程数
- #zombie:过去10s僵死进程的数量
- #exit:atop在10s采样周期期间退出的进程数量
CPU行:cpu列展示了服务器的CPU整体的一个状态信息,包括内核和用户所占的比例、处理中断所占的比例、CPU的处于空闲下比例(这里是100%*cpu核心数,CPU有时候也会因为由于磁盘性能问题出现等待的空闲)
- sys、usr:CPU被用于处理进程时,进程在内核态、用户态所占CPU的时间比例
- irq:CPU在处理进程的中断请求所占的实际比例
- idle:CPU处于空闲状态下的时间比例(除了本身空闲,还有比如等待磁盘io的情况下也会处于空闲状态)
- wait:CPU处在“进程等待磁盘IO导致CPU空闲”状态的时间比例
CPU列各个值相加结果为N00%,其中N为cpu核数。
cpu行:每个核心的状态信息,和总的CPU信息一样,每列加起来的总和就是总的CPU的状态信息。
CPL行:cpl也反应了服务器整体的性能,展示信息包括进程等待队列数,分别从过去1分钟、5分钟、15分钟的采样信息。
- avg1、avg5和avg15字段:过去1分钟、5分钟和15分钟内运行队列中的平均进程等待数量
- csw:上下文交换次数
- intr:中断发生次数
- numcpu:cpu的核心数
MEM行:该列指示内存的使用情况
- tot:物理内存总量
- free:空闲内存的大小(不能单单从这个字段就判断内存不足,还需要参考free -m中的-/+ buffers/cache:free因为这块的内容随时就可以拿过来使用,还可以从是否有使用Swap来判断是否内存不足)
- cache:用于页缓存的内存大小
- dirty:内存中的脏页大小
- buff:用于文件缓存的内存大小
- slab:系统内核占用的内存大小
SWP行:该列指示交换空间的使用情况
- tot:交换区总量
- free:交换空间剩余空间总量
PAG行:该列指示虚拟内存分页情况
swin:换入内存页数
swout:换出内存页数
LVM/DSK行:该列指示磁盘使用情况,每一个磁盘设备对应一列,如果有sdb设备,那么增多一列DSK信息
- sda:磁盘设备标识
- busy:磁盘忙时所占比例
- read:read、KiB/r 、MBr/s:每秒读的请求数和请求的kb、mb数
- write:write、KiB/w 、MBr/w:每秒写的请求数和请求的kb、mb数
- avq:磁盘平均队列长度(根据实际的监控该列好像是磁盘平均请求数avgrq)
- avio:磁盘的平均io时间
NET行:多列NET展示了传输层(TCP/UDP)、网络层(ip)、网络接口的网络传输信息。
- transport:传输层(TCP/UDP)的数据输入输出的展示,例如在服务器的内部进程之间的数据传输就是在传输层展示,以为还不需要往下通过网络进行传输。
- network:网络层(ip)的数据输入输出的展示;
- eth0:默认的网络接口的数据输入输出的展示,也就是通过etho的ip的数据传输的展示,
- sp:网卡的带宽(1000M)
- pcki:传入的数据包的大小
- pcko:传出的数据包的大小
- si:每秒传入的数据大小
- so:每秒传出的数据大小
- coll(collisions):每秒的冲突数
- mlti(MULTICAST):每秒的多路广播的数量
- erri/erro:每秒输入输出的错误数
- drpi/drpo:每秒的输入输出的丢包数
- lo:通过127.0.0.1网络接口的数据传输的数据展示,参数和上面的eth0是一样的
进程列:进程列展示了每个进程在过去10S内的数据
m模式:内存状态模式
-
SYSCPU:过去10s内进程处于内核模式占用的CPU时间
-
USRCPU:过去10S进程处于用户模式占用的CPU时间
-
VSIZE:过去10S进程占用的虚拟空间大小
-
RSIZE:过去10S进程占用的内存空间大小
-
PSIZE:过去10S进程占用的页大小
-
VGROW:过去10S进程增长的虚拟空间大小
-
RGROW:过去10S进程增长的内存大小
-
SWAPSZ:过去10S进程使用交换空间的大小。
-
MEM:过去10S进程占用内存百分比
内存视图(Memory consumption)
内存视图展示了进程使用内存情况,按m键可进入内存视图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-43Aaiup9-1685945076992)(http://images.cnblogs.com/cnblogs_com/bangerlee/320012/r_atop%E5%86%85%E5%AD%98%E8%A7%86%E5%9B%BE.png)]
上图下半部分展示了每个进程占用的虚拟内存空间(VSIZE)、内存空间(RSIZE)大小,以及在上一个采样周期中虚拟内存和物理内存增长大小(VGROW、RGROW),MEM列指示进程所占物理内存大小。
从上图的PAG列的信息,我们可以知道此时系统内存负载较高,出现页换出情况,从进程视图中VGROW和RGROW列可看出VirtualBox进程占用内存量大量增长,部分进程占用的内存减少(VGROW或RGROW字段为负值),为VirtualBox进程腾出空间。
d模式:磁盘状态模式
- WRDSK:过去10S进程写磁盘的数据量
- DSK:过去10S进程所占磁盘的百分比
- CMD:进程名
p模式:进程状态模式,同一个名称的进程显示一列,根据进程名进行分组显示
- NPROCS:相同名称的进程数量
其它的参数上面已经有列出
v模式:线程状态模式
u模式:用户模式
根据用户进行分组显示
g模式:标准模式
默认视图(Generic information)
进入atop信息界面,我们看到的就是进程信息的默认视图(上图下半部分),按g键可以从其他视图跳到默认视图。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qiUTh24x-1685945076993)(http://images.cnblogs.com/cnblogs_com/bangerlee/320012/r_%E9%BB%98%E8%AE%A4%E8%A7%86%E5%9B%BE.png)]
从上图中,我们可以看到PID为3061的find进程在退出前在内核模式下占用了3.43秒CPU时间,在用户模式下占用了0.96秒CPU时间,共使用CPU时间为4.39秒,相对10分钟采样周期,CPU时间占用比例为1%,ST列表示进程状态,N表示该进程是前一个采样周期新生成的进程,E表示该进程已退出,EXC列指示进程的退出码。从进程名在“<>”符号中,我们亦可知该进程已退出。
s:进程当前的状态,包括:s(sleeping),R(runing)等
c:命令模式
命令视图(Command line)
按c键我们可以进入命令视图,该视图展示了与每个进程相对应的命令。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5cN8rsx8-1685945076993)(http://images.cnblogs.com/cnblogs_com/bangerlee/320012/r_atop%E5%91%BD%E4%BB%A4%E6%A8%A1%E5%BC%8F.png)]
有时我们某位“马大哈”同事执行了某个脚本或命令,使得系统资源占用率异常飙高,这时,我们可以很容易地通过atop的命令视图找到导致异常的命令。
atop的相关文件
/etc/atop:目录保存的是atop的配置文件
/etc/rc.d/init.d/atop:atop的启动文件
/etc/cron.d/atop:atop的定时任务文件,默认是每天0点开始
/var/log/atop:atop日志文件,默认是每天0点开始会产生当天的一个日志文件,然后可以通过atop -r file 查看信息,但是没有找到自动播放的的功能,只能通过输入b显示一个指定的时间的信息,可以写个循环来实现
/usr/bin/atop:atop命令目录
atop -r atop_20160510 -b 13:00 -e 17:00
1.atop产生的日志文件信息是10分钟一个采样周期进行记录,可以通过修改/etc/atop/atop.daily文件进行修改。
个时间点采样页面组合起来就形成了一个atop日志文件,我们可以使用"atop -r XXX"命令对日志文件进行查看。那以什么形式保存atop日志文件呢?
对于atop日志文件的保存方式,我们可以这样:
- 每天保存一个atop日志文件,该日志文件记录当天信息
- 日志文件以"atop_YYYYMMDD"的方式命名
- 设定日志失效期限,自动删除一段时间前的日志文件
其实atop开发者已经提供了以上日志保存方式,相应的atop.daily脚本可以在源码目录下找到。在atop.daily脚本中,我们可以通过修改INTERVAL变量改变atop信息采样周期(默认为10分钟);通过修改以下命令中的数值改变日志保存天数(默认为28天):
(sleep 3; find $LOGPATH -name 'atop_*' -mtime +28 -exec rm {} \; )&
最后,我们修改cron文件,每天凌晨执行atop.daily脚本:
0 0 * * * root /etc/cron.daily/atop.daily
将atop的记录导出文本:
顶部 -r /瓦尔/日志/顶部/顶部/atop_slot10_suse10sp2_20120622 -b 04:00 – e 16:10>>atop_log.txt
上述命令可以用一个命令使用,将atop信息重定向到一个文件中,例如:
顶部 -v -b 01:00 -e 01:05 atop_linux_20160119>我.log
atop看CPU的空闲率:
顶部 – PCPU – r atop_linux_20160119|格雷普 – v SEP|格雷普 – v RESET|awk – F””[打印 ,,(9=11=13]]100%”]”
atop的其它参数:
登录后复制
Usage: atop [-flags] [interval [samples]]
or
Usage: atop -w file [-S] [-a] [interval [samples]]
atop -r [file] [-b hh:mm] [-e hh:mm] [-flags]
generic flags:
-a show or log all processes (i.s.o. active processes only)
-R calculate proportional set size (PSS) per process
-P generate parseable output for specified label(s)
-L alternate line length (default 80) in case of non-screen output
-f show fixed number of lines with system statistics
-F suppress sorting of system resources
-G suppress exited processes in output
-l show limited number of lines for certain resources
-y show individual threads
-1 show average-per-second i.s.o. total values
-x no colors in case of high occupation
-g show general process-info (default)
-m show memory-related process-info
-d show disk-related process-info
-n show network-related process-info
-s show scheduling-related process-info
-v show various process-info (ppid, user/group, date/time)
-c show command line per process
-o show own defined process-info
-u show cumulated process-info per user
-p show cumulated process-info per program (i.e. same name)
-C sort processes in order of cpu-consumption (default)
-M sort processes in order of memory-consumption
-D sort processes in order of disk-activity
-N sort processes in order of network-activity
-A sort processes in order of most active resource (auto mode)
specific flags for raw logfiles:
-w write raw data to file (compressed)
-r read raw data from file (compressed)
special file: y[y...] for yesterday (repeated)
-S finish atop automatically before midnight (i.s.o. #samples)
-b begin showing data from specified time
-e finish showing data after specified time
参考:
https://blog.51cto.com/u_15715098/5707324
http://www.taodudu.cc/news/show-3691508.html?action=onClick