写在最前面
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization(2021ACL会议)
https://arxiv.org/abs/2106.01890
论文:https://arxiv.org/pdf/2106.01890.pdf

预期写两篇博客详细展示该论文,两篇博客分析公开的代码
(感谢吕博的分享,最近看了一些线上汇报梳理了一些论文工作)
B站有论文作者的PPT讲解:
【SimCLS:抽象概括对比学习的简单框架】 https://www.bilibili.com/video/BV1iM4y197WC/?share_source=copy_web&vd_source=5c26e6ddafba66137ab0d49dc584e2ce

模型框架
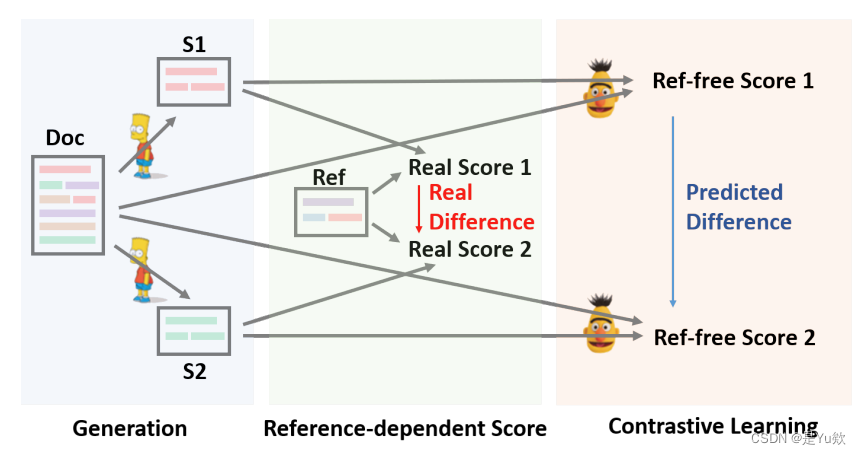
SimCLS框架进行两阶段抽象摘要 ,其中Doc、S、Ref分别表示文档、生成摘要和引用。
在第一阶段,使用Seq2Seq生成器(BART)生成候选摘要。
在第二阶段,使用评分模型(RoBERTa)来预测基于源文档的候选摘要的性能。评分模型通过对比学习进行训练,其中训练示例由Seq2Seq模型提供。
摘要
提出了一个概念上简单而经验上强大的抽象摘要框架SIMCLS,它可以通过将文本生成制定为一个无参考的评估问题(即质量估计),通过对比学习来弥补目前主导的序列到序列学习框架所产生的学习目标和评估指标之间的差距。
实验结果表明,SimCLS对现有的顶级评分系统进行了少量的修改,可以大大提高现有顶级评分模型的性能。特别是,在CNN/DailyMail数据集上,相对于BART (Lewis et al., 2020)的2.51绝对提升,相对于PEGASUS (Zhang et al., 2020a)w.r.t ROUGE-1的2.50绝对提升,将最先进的性能提升到一个新的水平。
代码和结果:https://github.com/yixinL7/SimCLS。
模型的结果已经部署到EXPLAINABOARD(Liuet al., 2021a)平台上,该平台允许研究人员以更细粒度的方式理解系统。
1 简介
序列到序列(Seq2Seq)神经模型(Sutskever et al.,2014)已广泛用于语言生成任务,如抽象摘要(Nallapati et al., 2016)和神经机器翻译(Wu et al., 2016)。
虽然抽象模型(Lewis et al., 2020; Zhang et al., 2020a)在总结任务中显示出了很好的潜力,但它们分享了Seq2Seq模型训练中广泛承认的挑战。
具体来说,Seq2Seq模型通常在最大似然估计(MLE)框架下进行训练,在实践中通常使用teacher-forcing算法(Williams and Zipser, 1989)进行训练。这引入了目标函数和评价指标之间的差距,因为目标函数基于局部的令牌级预测,而评价指标(例如ROUGE (Lin, 2004))将比较黄金参考资料和系统输出之间的整体相似性。
此外,在测试阶段,模型需要自回归地生成输出,这意味着在前面步骤中所犯的错误会累积起来。这种训练和测试之间的差距在以前的工作中被称为exposure bias 暴露偏差(Bengio et al., 2015; Ranzato et al., 2016)。
方法的主线(Paulus et al., 2018; Li et al., 2019)建议使用强化学习(RL)的范式来缓解上述差距。虽然RL训练可以根据全局预测和与评估指标密切相关的奖励来训练模型,但它引入了深度RL的共同挑战。
具体来说,基于rl的训练存在噪声梯度估计(Greensmith et al., 2004)问题,这通常会使训练不稳定并且对超参数敏感。
Minimum risk training最低风险培训,作为一种替代方案,也已用于语言生成任务(Shen et al., 2016; Wieting et al., 2019)。
然而,估计损失的准确性受到采样输出数量的限制。其他方法(Wiseman and Rush, 2016; Norouzi et al., 2016; Edunov et al., 2018)旨在扩展MLE的框架,将句子水平分数纳入目标函数。虽然这些方法可以减轻MLE训练的局限性,但评估指标和在其 方法中使用的目标函数之间的关系可以是间接的和隐含的。
在此背景下,本文将对比学习((Chopra et al., 2005))的范式进行了推广,引入了一种抽象总结的方法,从而实现了用相应的评价指标直接优化模型的目标,从而缩小了MLE训练中训练阶段和测试阶段之间的差距。
虽然一些相关工作(Lee et al., 2021; Pan et al., 2021)建议引入对比损失作为条件文本生成任务的MLE训练的增强,但本文选择通过在提出的框架的不同阶段引入对比损失和MLE损失来分离它们的功能。
具体来说,受到Zhong et al. (2020); Liu et al. (2021b)最近在文本摘要方面的工作的启发,我们建议使用一个两阶段模型进行抽象摘要,
其中首先训练Seq2Seq模型来生成带有MLE损失的候选摘要,
然后训练一个参数化评估模型来对生成的候选进行对比学习排名。
通过在不同阶段优化生成模型和评估模型,我们能够用监督学习来训练这两个模块,绕过基于rl方法的具有挑战性和复杂的优化过程。
我们在这项工作中的主要贡献是通过提出一个带有对比学习的生成-然后评估两阶段框架来接近面向度量的抽象总结训练,这不仅将CNN/DailyMail上的最新性能提升到一个新的水平(2.2 ROUGE-1对基线模型的改进),也展示了这个两阶段框架的巨大潜力。呼吁今后努力使用最大似然估计以外的方法优化Seq2Seq模型。