由于上两篇文章是按照视频教程顺下来的,很多细节地方有所忽略,本文重点对各个地方的细节进行学习与记录。
细节一:torchvision.transforms.Compose
在制作数据集的过程中,我们使用了transforms.Compose对数据进行了预处理。
torchvision.transforms是pytorch中的图像预处理包。一般用Compose把多个步骤整合到一起:如:
transforms.Compose([transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(224),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
])
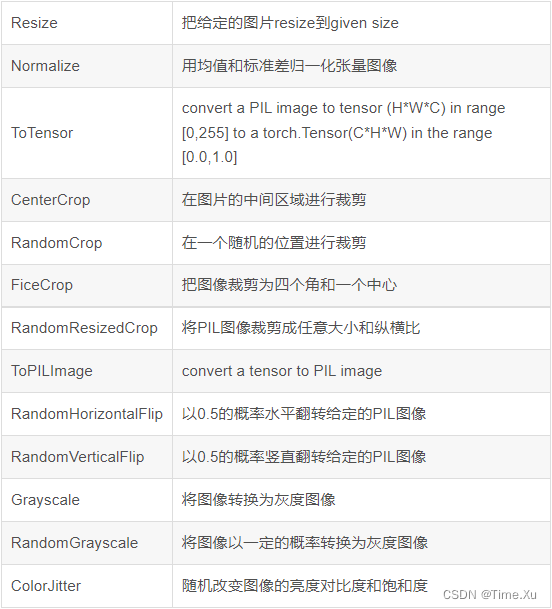
其中ToTensor是使得图片从HWC转换为CHW并从0 ~ 255转化为0 ~ 1
细节二:torchvision.datasets.ImageFolder
ImageFolder是一个通用的数据加载器,它要求以各个文件夹的这种格式来组织数据集的训练、验证或者测试图片。
#root 为data/train或者data/valid
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
参数详解:
dataset=torchvision.datasets.ImageFolder(
root, #图片储存的根目录,即各类别文件夹所在目录的上一级目录
transform=None,#预处理操作函数(细节1所定义的函数)
target_transform=None, # 对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…
loader=<function default_loader>, # 表示数据集加载方式,通常默认加载方式即可。
is_valid_file=None) #获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
返回的dataset都有以下三种属性:
self.classes:用一个 list 保存类别名称
self.class_to_idx:类别对应的索引,与不做任何转换返回的
target 对应 self.imgs:保存(img-path, class) tuple的 list

细节三:torch.utils.data.DataLoader
torch.utils.data.DataLoader 主要是对数据进行 batch 的划分。
torch.utils.data.DataLoader(image_datasets, # 数据,要求是dataset类型
batch_size=8, # 批量大小
shuffle=True, #是否进行数据洗牌)
其他的操作可见别人写的博客
细节四:model.parameters()与model.state_dict()
model.parameters()与model.state_dict()都是Pytorch中用于查看网络参数的方法。
一般来说,前者多见于优化器的初始化;后者多见于模型的保存。
如:
optomizer = torch.optim.Adam(model.parameters(), lr=1e-5)
torch.save(model.state_dict(), ‘best_model,pth’)
model.state_dict()返回的是一个OrderDict,存储了网络结构的名字和对应的参数。
model.state_dict() 获取了 model 中所有的可学习参数(weight、bias),同时还获取了不可学习参数(BN layer 的 running mean 和 running var 等)。可以将 model.state_dict() 看作是在 model.parameters() 功能的基础上,又额外获取了所有不可学习参数。
————————————————
版权声明:本文为CSDN博主「yaoyz105」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_31347869/article/details/125065271
额外知识点1:深拷贝、浅拷贝和赋值之间的区别
Python提供了三种赋值方法,最常见的是赋值=、浅拷贝copy.copy()和深拷贝copy.deepcopy()
赋值:Python中的赋值都是进行对象的引用传递,即内存地址的传递。
浅拷贝:浅拷贝只拷贝对象本身,并不会拷贝对象内部的嵌套对象。
赋值:深拷贝会拷贝对象本身以及其所有的嵌套对象。
具体可以参考这个博客
- model.state_dict()也是浅拷贝,如果令param=model.state_dict(),那么当你修改param,相应地也会修改model的参数。
细节五:torch.load()与model.load_state_dict()
torch.load(“path路径”)表示加载已经训练好的模型,这个模型就是一个state_dict
model.load_state_dict()表示将训练好的模型参数重新加载至网络模型中
# save
torch.save(model.state_dict(), PATH)
# load
model = MyModel(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
额外知识点2:Image.resize()和Image.thumbnail()
**Image.resize()**函数用于修改图片的尺寸。 > **Image.thumbnail()**函数用于制作当前图片的缩略图。
详情请参考这一篇博文~