TensorFlow学习笔记
Tensor 表示张量,是多维数组、多维列表,用阶表示张量的维数。
0 阶张量叫做标量,表示的是一个单独的数,如 123;
1 阶张量叫做向量,表示的是一个一维数组如[1,2,3];
2 阶张量叫做矩阵,表示的是一个二维数组。
TensorFlow中数据类型有tf.int32、 tf.float32、tf.float64、tf.bool、tf.string
创建张量的方法:
- tf.constant(张量内容,dtype=数据类型(可选))

shape 中数字为 2,表示一维张量里有 4 个元素。
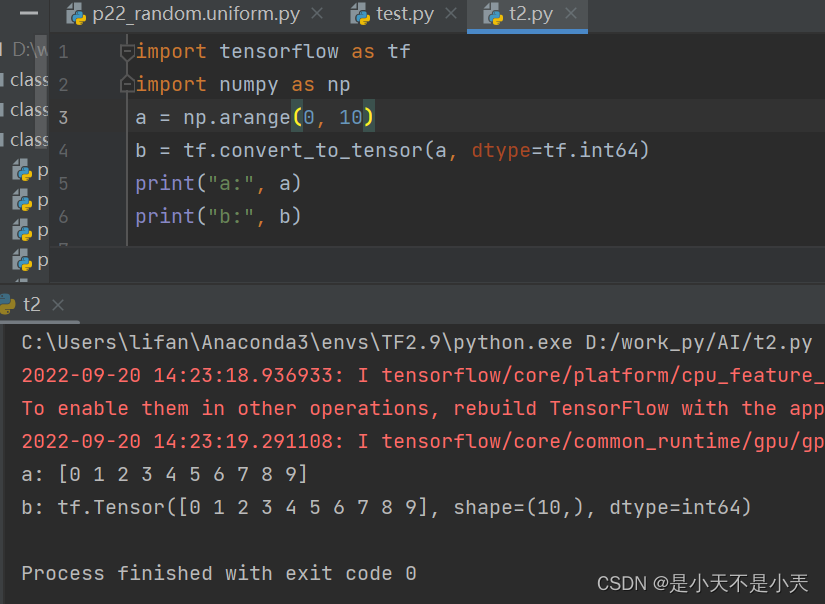
- 将numpy的数据类型转换为Tensor数据类型
tf.convert_to_tensor(数据名,dtype=数据类型(可选))
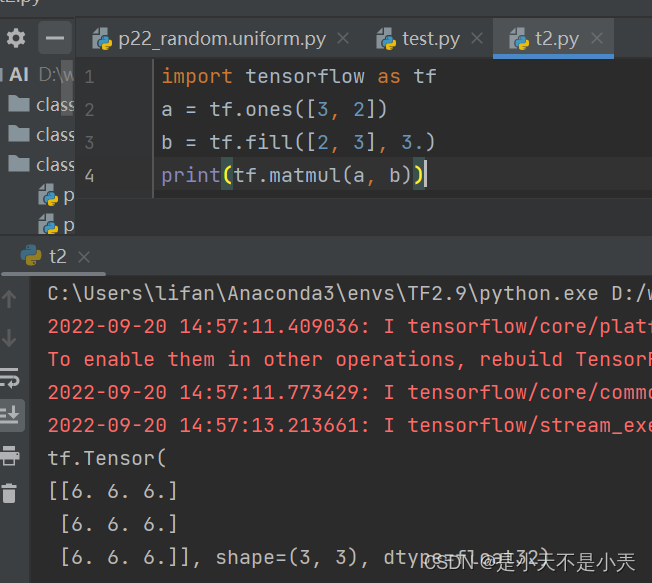
- 创建全0的张量 tf.zeros(维度)
- 创建全1的张量 tf.ones(维度)
- 创建全为指定值的张量 tf.fill(维度,指定值)

- 生成正态分布的随机数,默认均值为0,标准差为1
- tf.random.normal(维度,mean=均值,stddev=标准差)
- 生成截断式正态分布的随机数
- tf.random.truncated_normal(维度,mean=均值,stddev=标准差)
生成截断式正态分布的随机数,能使生成的这些随机数更集中一些,如果随机生成数据的取值 在 ( mean - 2 * stddev, mean + 2 * stddev ) 之外则重新进行生成,保证了生成值在均值附近

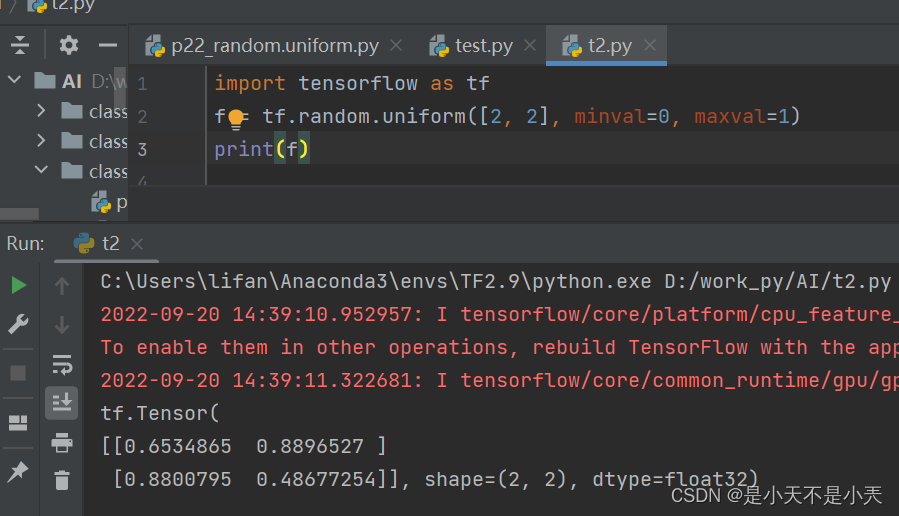
- 生成均匀分布的随机数
- tf.random.uniform(维度,minval=最小值,maxval=最大值)
生成指定维度的均匀分布随机数,用 minval 给定随机数的最小值,用 maxval 给定随机数的最大值, 最小、最大值是前闭后开区间。
其他常用函数:
- 强制tensor数据类型转换
- tf.cast(张量名,dtype=数据类型)
- tensor元素计算
- tf.reduce_min(张量名):最小
- tf.reduce_max(张量名):最大
- tf.reduce_sum(张量名):求和
- tf.reduce_mean(张量名):均值
- 利用 tf.add (张量 1,张量2)实现两个张量的对应元素相加;
- 利用 tf.subtract (张量 1,张量 2)实现两个张量的对应元素相减;
- 利用 tf.multiply (张量 1,张量 2)实现两个张量的对应元素相乘;
- 利用 tf.divide (张量 1,张量 2)实现两个张量的对应元素相除。
注:只有维度相同的张量才可以做加减乘除四则运算
可用 tf.reduce_mean (张量名,axis=操作轴)计算张量沿着指定维度的平均值。求最大最小均值同理,对于一个二维张量,如果 axis=0 表示纵向操作,axis=1 表示横向操作。

- tensor数据运算
- 平方 tf.square(张量名)
- n次方 tf.pow(张量名, n)
- 开方 tf.sqrt(张量名)

- tensor数据运算,matmul矩阵乘
- tf.matmul(矩阵 1,矩阵 2)
- tf.argmax
- 返回张量沿着指定维度最大值的索引
- tf.argmax(张量名, axis=操作轴)
- tf.data.Dataset.from_tensor_slices((输入特征, 标签))
- 该函数是dataset核心函数之一,它的作用是把给定的元组、列表和张量等数据进行特征切片。
- 切片的范围是从最外层维度开始的。
- 如果有多个特征进行组合,那么一次切片是把每个组合的最外维度的数据切开,分成一组一组的。
- 切分传入张量的第一维度,生成输入特征/标签对,构建数据集,此函数对 Tensor 格式与 Numpy 格式均适用,其切分的是第一维度,表征数据集中数据的数量,之后切分 batch 等操作都以第一维为基础。

- Variable函数
tf.Variable()将变量标记为“可训练”,被标记的变量会在反向传播中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
tf.Varible(初始值)
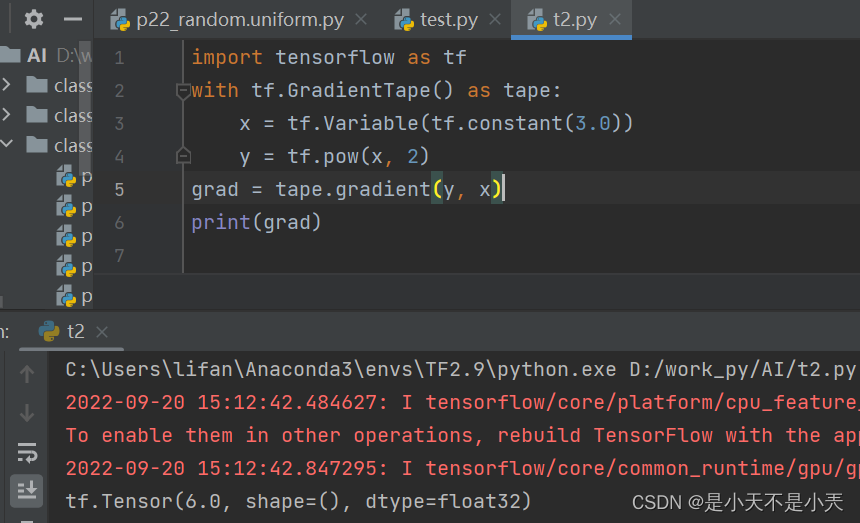
- GradientTape函数
tf.GradientTape( )函数搭配 with 结构计算损失函数在某一张量处的梯度
- GradientTape函数 多层高阶导数
- watch(tensor)
- 作用:确保某个tensor被tape追踪

另外,默认情况下GradientTape的资源在调用gradient函数后就被释放,再次调用就无法计算了。
所以如果需要多次计算梯度,需要开启persistent=True属性,例如:

- One_hot函数
- tf.one_hot(待转换数据,depth=几分类)
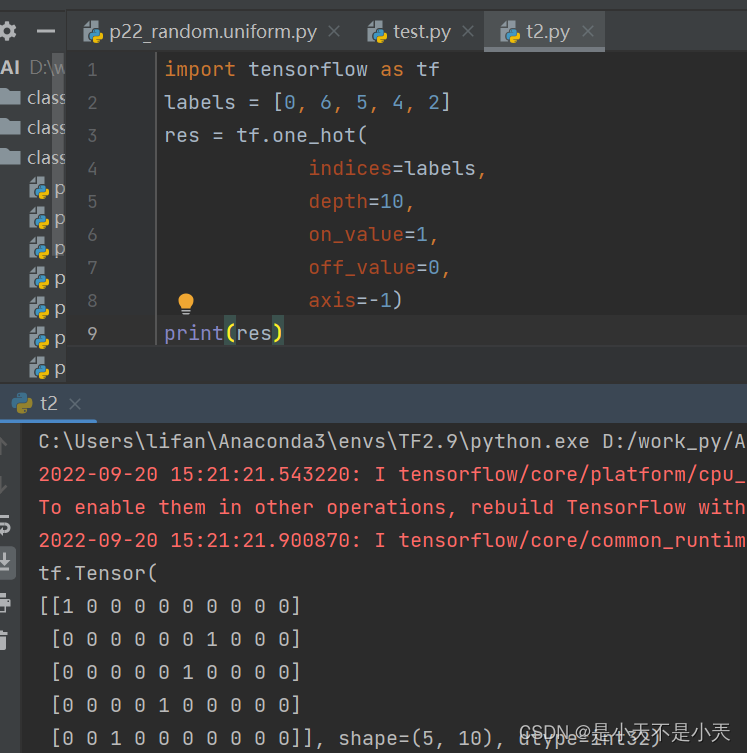
- One_hot函数
tf.one_hot(indices, depth, on_value, off_value, axis)
-
- indices是一个列表,指定张量中独热向量的独热位置,或者说indeces是非负整数表示的标签列表。len(indices)就是分类的类别数。
- tf.one_hot返回的张量的阶数为indeces的阶数+1。
- 当indices的某个分量取-1时,即对应的向量没有独热值。
- depth是每个独热向量的维度
- on_value是独热值
- off_value是非独热值
- axis指定第几阶为depth维独热向量,默认为-1,即,指定张量的最后一维为独热向量
- tf.nn.softmax函数
- tf.nn.softmax(x)函数,使输出符合概率分布

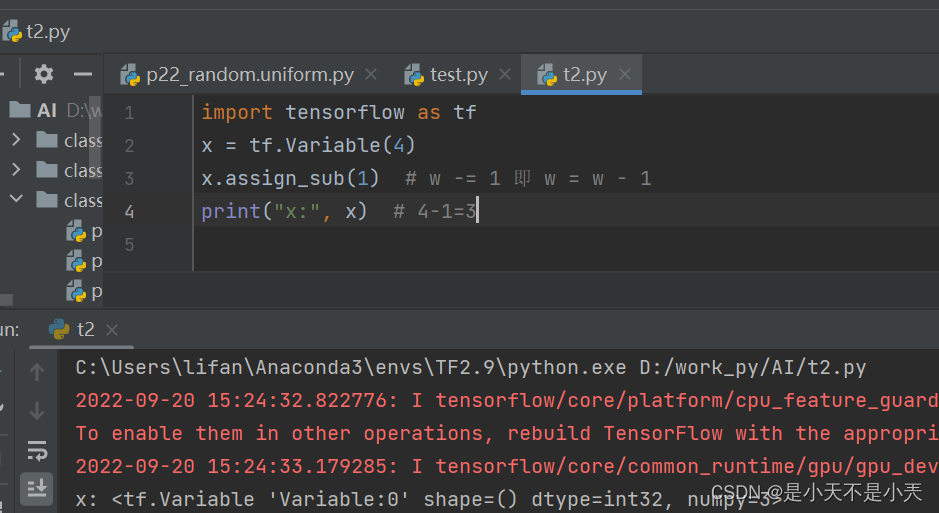
- assign_sub函数
赋值操作,更新参数的值并返回
调用assign_sub前,先用 tf.Variable定义变量w为可训练(可自更新).
w.assign_sub(w要自减的内容)