写在前面
记录一下《现代C++教程》中的要点。
现代C++是指C++11之后的语法特性,如无特别说明,下面的语法特性均是C++11后才可使用。
一、语言可用性的强化
1. 常量
1.1 nullptr
-
作用:
- 代替
NULL赋空指针;
- 代替
-
使用:
char *a = nullptr;
- 原因:
- 编译器通常定义
NULL = (void*)0或者NULL = 0; - 但由于C++不允许
void *隐式转换到其他类型的指针,必须显式转换; - 因此在函数传参时,传入
NULL就不知道是调用int还是xxx *类型的重载函数; nullptr用于区分空指针和0,而弃用NULL;nullptr所占空间和void*相同;- 注意:
NULL和\0的值都是0,所以它们取反是可以转为true布尔值的;- 但
nullptr的值不是0,所以它取反并不能转为true,应当用ptr == nullptr来判断指针是否为空;
- 编译器通常定义
1.2 constexpr
-
作用:
- 让用户显式声明的函数或者对象构造函数在编译期成为常量表达式;
- 也就是说让函数的返回值可以当常量使用;
-
使用:
constexpr声明的对象:- 必须用常量表达式(由常量或者
constexpr组成的表达式)初始化;
- 必须用常量表达式(由常量或者
constexpr声明的函数:- 如果要传入参数,则必须是常量表达式;
- 返回值必须是常量表达式;
- 除
using指令、typedef语句、static_assert断言和return语句外,不能出现其他语句; - 从C++14开始,可以使用局部变量、循环和分支;
// 对象构造函数
constexpr int a = 1 + 2 + 3;
// 函数
constexpr int fibonacci(const int n) {
return n==1 || n==2 ? 1 : fibonacci(n-1) + fibonacci(n-2);
}
int arr_1[a];
int arr_2[fibonacci(5)];
2. 变量及其初始化
2.1 可在if/switch的条件语句中声明临时变量
- 使用:
- C++17后可在if/switch的条件语句中声明临时变量;
if(
const std::vector<int>::iterator itr = std::find(vec.begin(), vec.end(), 3);
itr != vec.end()
)
{
*itr = 4;
}
[2.2] 可在成员函数中使用初始化列表
-
作用:
- 让自定义的类也可以使用
class object = {}的形式进行初始化;
- 让自定义的类也可以使用
-
使用:
- 在成员函数的形参中使用
std::initializer_list<参数类型> list; - 可以在构造函数中使用,也可以在一般的成员函数中使用;
- 在成员函数的形参中使用
class MagicFoo {
public:
std::vector<int> vec;
// 构造函数中使用
MagicFoo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
// 一般的成员函数中使用
void foo(std::initializer_list<int> list) {
for (std::initializer_list<int>::iterator it = list.begin();
it != list.end(); ++it)
vec.push_back(*it);
}
};
MagicFoo magicFoo = {
1, 2, 3, 4, 5};
magicFoo.foo({
6,7,8,9});
2.3 可自动为std::tuple类型结构化绑定
-
作用:
- 自动为std::tuple类型拆包并绑定到若干变量中,而无需知道包中各个变量的类型;
-
使用:
- C++17后可以自动拆包赋值给多个变量;
std::tuple<int, double, std::string> f() {
return std::make_tuple(1, 2.3, "456");
}
// 自动将int、double和string的值绑定到x、y和z上
auto [x, y, z] = f();
[3]. 类型推导
3.1 auto
-
作用:
- 根据等式右值自动决定等式左值的类型;
-
使用:
- C++20后可以用于函数的形参;
- 不能推导数组类型;
- 不能用作模板参数实参;
- 可以和
decltype搭配推导返回值类型,C++14后可以无需和decltype搭配使用;
auto i = 5; // i被推导为int
auto arr = new auto(10); // arr被推导为int *
auto it = vec.begin(); // it被推导为容器对应的迭代器类型
template<typename T, typename U>
auto add2(T x, U y) -> decltype(x+y){
return x + y;
}
// C++14之后
template<typename T, typename U>
auto add2(T x, U y){
return x + y;
}
3.2 decltype
-
作用:
- 得到某个表达式的类型;
-
使用:
decltype(表达式);- 可以用
decltype(auto)作为函数的返回类型,它能自动推导转发函数或者封装函数的返回类型,也就是以调用其他函数作为返回类型的情况;
auto x = 1;
auto y = 2;
// 用x+y表达式的类型定义z
decltype(x+y) z;
// 比较x和int类型是否相同
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
// 用decltype(auto)自动推导封装的返回类型
std::string look_up_a_string_1() {
return lookup1();
}
decltype(auto) look_up_a_string_1() {
return lookup1();
}
3.3 std::is_same
-
作用:
- 判断两个类型是否相等;
- 返回布尔类型;
-
使用:
// 比较x和int类型是否相同
if (std::is_same<decltype(x), int>::value)
std::cout << "type x == int" << std::endl;
4. 控制流
4.1 if constexpr
-
作用:
- 在编译过程中就计算得到if条件的布尔值;
- 这样能够加快条件判断的速度;
-
使用:
// 注意泛型的实例化在编译过程中就已经实现了
template<typename T>
auto print_type_info(const T& t) {
if constexpr (std::is_integral<T>::value) {
return t + 1;
} else {
return t + 0.001;
}
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
/* 编译时的代码为:
int print_type_info(const int& t) {
return t + 1;
}
double print_type_info(const double& t) {
return t + 0.001;
}
int main() {
std::cout << print_type_info(5) << std::endl;
std::cout << print_type_info(3.14) << std::endl;
}
*/
[4.2] 区间for迭代
-
作用:
- 无需显式给出for循环的起始位置和终止位置,即可完整遍历实现了迭代器的类对象;
-
使用:
for(auto element: 实现了迭代器的对象),然后在循环中可以用element读取对象的每个元素;for(auto &element: 实现了迭代器的对象),然后在循环中可以用element读写对象的每个元素;- 一般的针对除配接器以外的基本容器来使用的,因为这些容器均实现了迭代器;
for (auto element : vec) {
std::cout << element << std::endl; // read only
}
for (auto &element : vec) {
element += 1; // read and write
}
5. 模板
5.1 外部模板
-
作用:
- 避免每次等到遇到模板的实例化对象时由编译器自动隐式实例化,因为这样会导致模板在同一种类型上面反复实例化;
- 显式实例化可以显式地指定该类型的模板在何处实例化;
- 之所以叫做外部模板是因为与外部变量的使用很类似,加了
extern就代表在别处实例化,在本文件中使用但不重复实例化;
-
使用:
- (1) 在本源代码对应的编译输出文件中实例化:
- 类模板用
template class 模板类名<实例化类型>显式实例化; - 函数模板用
template 函数返回值类型 模板函数名<实例化类型>(参数类型)显式实例化;
- 类模板用
- (2) 在其他源代码对应的编译输出文件中实例化,在本文件中使用:
- 类模板用
extern template class 模板类名<实例化类型>显式实例化; - 函数模板用
extern template 函数返回值类型 模板函数名<实例化类型>(参数类型)显式实例化;
- 类模板用
- (1) 在本源代码对应的编译输出文件中实例化:
// 在本编译文件中实例化模板
template class std::vector<bool>;
template int add<int>(int t1, int t2);
// 不在该当前编译文件中实例化模板
extern template class std::vector<double>;
extern template int add<int>(int t1, int t2);
5.2 嵌套模板实例化
-
作用:
- 能够以实例化的模板作为类型实例化模板;
-
使用:
std::vector<std::vector<int>> matrix;
- 原因:
- 在传统C++编译器中,连续的两个右尖括号
>>会被认为是右移运算符; - 因此无法编译成功;
- 在传统C++编译器中,连续的两个右尖括号
5.3 using定义模板类型别名
-
作用:
- 在传统的用法上,增加为类型和模板定义别名的功能,可以代替
typedef;
- 在传统的用法上,增加为类型和模板定义别名的功能,可以代替
-
使用:
- (1) 用
using namespace 命名空间名称引入命名空间(传统C++); - (2) 用
using 基类::基类成员在子类中改变引用的基类成员的权限; - (3) 用
using 别名 = 类型或者模板指定别名;
- (1) 用
// 命名空间
using namespace std;
using namespace std::vector;
// 在子类中改变基类成员的权限
class Base{
protected:
int member;
};
class Derived: private Base {
// 虽然是私有继承
public:
using Base::member; // 但用using后member成为了子类的public成员
}
// 指定普通类型别名
using ULL = unsigned long long; //typedef unsigned long long ULL;
// 指定函数类型别名
using func = void(*)(int, int); //typedef void(*func)(int, int);
// 指定类成员函数类型别名
using handler_t = void(ProcessPool::*)(int);
// 指定模板别名
template <typename T>
using mapInt = std::map<int, T>;
mapInt<bool> bmap;
- 原因:
typedef不能为模板定义别名,因为模板并不是类型,而是用来产生类型的;- 而且
typedef在定义函数指针别名时的写法很独特,在形式上并不规整; - 用
using可以完全取代typedef;
[5.4] 变长参数模板
-
作用:
- 无需显式给定所有的模板参数;
-
使用:
- 可以和递归和
sizeof()函数搭配使用,实现模板参数的拆包; - 参考:
- 可以和递归和
template <typename... TS>
void magic(Ts... args) {
// 输出参数的个数
std::cout << sizeof...(args) << std::endl;
}
// 1. 用递归实现模板参数的拆包,终止函数是一个参数的函数
// 这样传入的可变参数最少是1个
template<typename T0>
void printf1(T0 value) {
// 仅一个参数
std::cout << value << std::endl;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
// 函数重载,多个参数
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// 2. 用递归实现模板参数的拆包,终止函数是无模板且无参数的函数
// 这样传入的可变参数可以是0个
void printf1() {
// 无参数
return;
}
template<typename T, typename... Ts>
void printf1(T value, Ts... args) {
// 函数重载,多个参数
std::cout << value << std::endl;
printf1(args...);
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// 3. 用逗号表达式实现模板参数的拆包
// 但这种方式只适用于各个参数的处理方式相同的情况,使用的范围比较局限
template<typename T>
void printf1(T value) {
std::cout << value << std::endl;
}
template<typename... Ts>
void printf1(Ts... args) {
// 使用std::initializer_list
int arr[] = {
(printf1(args), 0)... };
// 等价于用下面的方式
// std::initializer_list<int> {(printf1(args), 0)...};
}
int main() {
printf1(1, 2, "123", 1.1);
return 0;
}
// C++17后可以这样实现拆包
template<typename T0, typename... T>
void printf2(T0 t0, T... t) {
// 一个或者多个参数
std::cout << t0 << std::endl;
if constexpr (sizeof...(t) > 0) printf2(t...);
}
5.5 用字面量作为模板参数
-
作用:
- 除了可以用类型作为模板参数外,还可以用字面量作为模板参数;
- 字面量可以看作是不用变量符号定义的常量,如常数,字符串等;
-
使用:
template <typename T, int BufSize>
class buffer_t {
public:
T& alloc();
void free(T& item);
private:
T data[BufSize];
}
buffer_t<int, 100> buf; // 100 作为模板参数
5.6 常用模板
-
(1)
std::is_same:- 比较两类型是否相同;
- 实现原理参考:c++11 std::is_same 源码剖析;
-
(2)
std::decay:- 将类型退化到基本类型,可以:
- 去除
const和左右值引用, - 将函数名或者数组名退化到函数指针;
- 去除
- 实现原理参考:c++11 std::decay源码剖析;
- 将类型退化到基本类型,可以:
-
(3)
std::enable_if:- 相当于if的用法,用于检验类型是否可以被使用;
- 实现原理参考:std::enable_if 的几种用法;
// 比较类型1是否和类型2相同,如果是,value=true,反之,value=false
std::is_same<类型1, 类型2>::value
// 获得类型的退化类型(基本类型)
std::decay<类型>::type
// 如果布尔值=true,则type=类型,否则编译出错(类型默认为void)
std::enable_if<布尔值, 类型>::type
6. 面向对象
6.1 委托构造
-
作用:
- 可以在当前类的一个构造函数中调用另一个构造函数;
-
使用:
- 使用方式和调用父类构造函数方式类似;
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() {
// 委托Base() 构造函数
value2 = value;
}
};
6.2 继承构造
-
作用:
- 直接在子类中继承父类的构造函数,这样就不用再重新写子类的构造函数了;
-
使用:
- 通过
using关键字实现;
- 通过
class Base {
public:
int value1;
int value2;
Base() {
value1 = 1;
}
Base(int value) : Base() {
// 委托Base() 构造函数
value2 = value;
}
};
class Subclass : public Base {
public:
using Base::Base; // 继承构造
};
6.3 显式虚函数重载override和final
-
作用:
- 避免重载的函数并非是基类的虚函数;
- 避免子类覆盖了当前类重载的虚函数;
-
使用:
- 用
override保证当前重载的是基类的虚函数; - 用
final保证子类不会再覆盖当前类重载的虚函数,或者保证不会再派生子类;
- 用
struct Base {
virtual void foo(int);
};
struct SubClass: Base {
virtual void foo(int) override; // 合法
//virtual void foo(float) override; // 非法, 父类没有此虚函数
};
struct Base {
virtual void foo() final;
};
struct SubClass1 final: Base {
}; // 合法
struct SubClass2 : SubClass1 {
}; // 非法, SubClass1 已final
struct SubClass3: Base {
void foo(); // 非法, foo 已final
};
6.4 显式使用或者禁用默认函数
-
作用:
- 显式使用或者禁用默认函数;
-
使用:
函数定义 = default则显式使用默认函数;函数定义 = delete则显式禁用默认函数;
class Magic {
public:
Magic() = default; // 显式声明使用编译器生成的构造
Magic& operator=(const Magic&) = delete; // 显式声明拒绝编译器生成构造
Magic(int magic_number);
}
- 原因:
- C++默认生成默认构造函数、复制构造函数、重载赋值运算符、析构函数、new运算符和delete运算符;
- 但有时候需要显式使用或者禁止使用这些默认生成的函数,而不是将控制权交由编译器;
6.5 强类型枚举
-
作用:
- 让枚举类型可以不只是
int类型;
- 让枚举类型可以不只是
-
使用:
- 用
enum class 枚举类名: 类型 {};定义枚举类,就可以指定枚举类的类型; - 传统枚举类型的使用可以参考:C++ 枚举类型详解;
- 用
// 传统C++枚举类型
enum color_set {
red, blue, green};
color_set color1;
color1 = red;
color_set color2 = color1;
int i = color1; // 相当于int i = 0;
//color1 = 1; // 不允许将int赋值给enum
cout << color1; // 相当于cout << int(0);
//cin >> color1; // 不允许输入
// 强类型枚举
enum class color_set1: unsigned int {
red, blue, green};
enum class color_set2: int {
red, blue, green};
color_set1 color1 = red;
color_set2 color2 = red;
//color1 == color2 // 非法
//int i = color1; // 非法
//color1 == 0 // 非法
- 原因:
- 传统C++的枚举实际上是
int类型; - 但和
int不同,枚举变量的取值是有限制的,由它定义时的标识符数量决定; - 因为不同枚举类型的值比较实际上是转换成整型比较,所以是非类型安全的;
- 传统C++的枚举实际上是
二、语言运行期的强化
[1]. Lambda表达式
-
作用:
- 提供匿名函数的功能;
- 即是定义了一个函数,但又不需要作外部的函数命名,可以视作一个函数对象;
- 返回的是函数对象而非函数指针;
-
工作原理:
- 生成一个匿名类的匿名对象;
- 然后重载
operator()运算符;
-
使用:
- 表达式为
[捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 { // 函数体 },包括:- 捕获列表:将函数外部的变量捕获到函数内部,相当于传参;
- 值捕获:
[外部变量名],拷贝一个外部变量的副本传入函数; - 引用捕获:
[&外部变量名],将外部变量的引用传入函数; - 隐式捕获:
[&]或者[=],让编译器自动推导所需的引用捕获或者值捕获; - C++14后,允许捕获右值,即表达式值、函数返回值等;
- 值捕获:
- 参数列表:调用函数者需要传入的参数变量;
- mutable:可以在函数内部修改传入的值捕获变量,但对函数外部的值没有影响;
- 返回类型:函数的返回值类型;
- 捕获列表:将函数外部的变量捕获到函数内部,相当于传参;
- 使用场景:
- 作为函数指针参数传入STL中的算法函数;
- 作为实现简单功能的函数;
- 可以参考博客:《深入理解C++11》笔记-lambda函数;
- 表达式为
// 和STL算法库中的函数搭配使用
sort(testdata.begin(), testdata.end(), [](int a, int b){
return a > b; });
for_each(a, a+4, [=](int x) {
cout << x << " "; });
auto pos = find_if(coll.cbegin(), coll.cend(), [=](int i) {
return i > x && i < y; });
vec_data.erase(std::remove_if(vec.date.begin(), vec_data.end(), [](int i) {
return n < x;}), vec_data.end());
// C++14后,可以在参数列表中使用auto
auto add = [](auto x, auto y) {
return x + y;
};
cout << add(1, 4) << endl;
[2]. 函数对象包装器
2.1 std::function
-
作用:
- 相当于是函数的容器,可以将函数和函数指针作为对象进行处理;
- 是类型安全的;
-
使用:
#include <functional>;std::function<函数返回类型(函数参数类型)> 容器名 = 函数名或者lambda表达式;
#include <functional>
int foo(int para) {
return para;
}
// 封装函数foo
std::function<int(int)> func = foo;
int important = 10;
// 封装lambda表达式
std::function<int(int)> func2 = [&](int value) -> int {
return 1+value+important;
};
std::cout << func(10) << std::endl;
std::cout << func2(10) << std::endl;
2.2 std::bind
-
作用:
- 用于绑定固定的参数到已有的函数中,从而生成参数更少的新函数;
- 相当于是修改已有函数的参数列表;
-
使用:
#include <functional>;- 通过std::bind生成的函数的参数传递默认是值传递;
- 可以参考博文:c++11之std::bind简单使用;
#include <functional>
// 1. 绑定普通函数
void print(int a, int b, int c)
{
std::cout << "a = " << a << ", b=" << b << ", c=" << c << "\n\n";
}
...
// 将占位符2绑定到a,将2绑定到b,将占位符1绑定到c,生成新函数func(_1, _2)
auto func1 = std::bind(print, std::placeholders::_2, 2, std::placeholders::_1);
func1(3, 4); // 相当于是print(4, 2, 3)
...
// 2. 绑定类成员函数
class A {
public:
void print(int x, int y) {
std::cout << "x + y = " << x + y << std::endl;
}
};
...
A a;
// 将a对象的成员函数绑定到f2上
auto func2 = std::bind(&A::print, &a, 1, std::placeholders::_1);
func2(2); // 相当于是a.print(1,2)
...
[3]. 右值引用
3.1 左右值概念
- 左值:等号左边的值,在等式之后依然存在的持久对象,能够取值的地址;
- 右值:等号右边的值,在等式之后不再存在的临时对象;
- 纯右值(无名称,不能取地址):
- 非引用返回的临时变量;
- 运算表达式产生的临时变量;
- 除字符串外的字面量(字符串字面量是左值);
- Lambda表达式;
- 将亡值(有名称,可以取地址):即将被销毁,但被右值引用使之继续存活的临时变量;
- 左值是右值引用的右值;
- 左值是常量左值引用的右值;
- 纯右值(无名称,不能取地址):
- 可以参考博客:C++雾中风景10:聊聊左值,纯右值与将亡值;
3.2 左右值引用
- 左值引用:
T &;
std::string & str
- 右值引用:
T &&;- 作引用(相当于取地址)的对象是将亡值;
- 如果作引用的对象不是将亡值,则需要通过
std::move(左值变量)将左值转换成右值,注意,这样会让原来的左值变量不可被访问; - 右值引用变量本身是个左值;
std::string && str
- 一些使用的例子:
std::string lv1 = "string,"; // lv1 是一个左值
// std::string&& r1 = lv1; // 非法, 右值引用不能引用左值
std::string&& rv1 = std::move(lv1); // 合法, std::move 可以将左值转移为右值
std::cout << rv1 << std::endl; // string,
const std::string& lv2 = lv1 + lv1; // 合法, 常量左值引用能够延长临时变量的生命周期
// lv2 += "Test"; // 非法, 常量引用无法被修改
std::cout << lv2 << std::endl; // string,string,
std::string&& rv2 = lv1 + lv2; // 合法, 右值引用延长临时对象生命周期
rv2 += "Test"; // 合法, 非常量引用能够修改临时变量
std::cout << rv2 << std::endl; // string,string,string,Test
3.3 移动语义
-
拷贝语义:
- 将一个对象的资源完全拷贝到另一个对象中,也就是深拷贝;
-
移动语义:
- 将一个对象的资源移动到另一个对象中,而无需进行数据的复制;
- 只能移动在堆上的资源,即用
new申请的空间:- 因为在堆上申请的资源一般才会比较大,使用拷贝语义的话开销很高;
- 使用移动语义就可以避免频繁new和delete,从而避免拷贝开销;
- 实现方式:通过新指针的复制和旧指针的置
nullptr完成资源的移动;
- 不能移动在栈上的资源,即非
new的空间,包括指针和POD类型等;- 因为在栈上申请的资源只能在结束作用域时销毁,并不能手动释放和转移,因此不能实现真正的移动语义;
- 但也可以把这些资源置默认初始值,实现伪移动语义(即移动后不可用,但非真正的不可访问);
-
涉及的相关函数:
-
std::move():- 作用:将一个左值转为将亡值,获取该左值的一个右值引用;
- 但实际上,原来的左值并没有被释放掉,只是增加了一个它的右值引用;
- 通过这个右值引用作为函数的实参,可以调用实现了移动语义的重载函数,例如移动构造函数和移动赋值运算符重载函数;
- 是唯一的将一个左值转为右值的方法;
- 参考:
- 作用:将一个左值转为将亡值,获取该左值的一个右值引用;
-
移动构造函数
A(A&& _a):- 作用:实现移动语义的构造函数;
- 形参是右值引用;
- 将形参的堆上资源移动到当前对象,即令当前对象的指针指向形参的堆上资源,然后将形参的指针置空;
- 注意:有默认的移动构造函数,但它并不会实现移动语义,而是和默认构造函数一样仅实现浅拷贝的拷贝语义;
- 作用:实现移动语义的构造函数;
-
移动赋值运算符重载函数
A& operator=(A&& _a):- 作用:实现移动语义的赋值运算符重载函数;
- 将形参的堆上资源移动到当前对象,即令当前对象的指针指向形参的堆上资源,然后将形参的指针置空;
- 注意:有默认的移动赋值运算符重载函数,但它并不会实现移动语义,而是和默认赋值运算符重载函数一样仅实现浅拷贝的拷贝语义;
- 作用:实现移动语义的赋值运算符重载函数;
-
-
实现移动语义:
- 必须自己手动实现类的移动构造函数和移动赋值运算符重载函数;
- 然后通过
std::move()调用移动构造函数或者移动赋值运算符重载函数,实现移动语义; - 调用的方式包括:
- (1) 显式调用移动构造函数或者移动赋值运算符重载函数;
- (2) 将一个右值实参传入到一个类对象的值传递形参上;
- 此时隐式调用移动构造函数,是移动语义;
- 如果是传左值,则调用的是复制构造函数,是拷贝语义;
- 如果未实现移动构造函数,则自动调用复制构造函数,因为
const A &常量左值引用也可以接右值引用; - 如果是传入到一个类对象的右值引用形参上,则既不是移动语义也不是拷贝语义,因为这个时候实参的资源未发生移动和拷贝,仅是增加了可在函数内访问的途径(相当于指针指向),在使用上和左值引用的作用是相同的(硬要说有什么不同的是它相当于是左值引用的重载,可以区分重载函数);
- (3) 将一个函数的 临时返回对象(右值) 赋予一个类对象;
- 此时隐式调用移动赋值运算符重载函数,是移动语义;
- 如果未实现移动赋值运算符重载函数,则自动调用赋值运算符重载函数,因为
const A &常量左值引用也可以接右值引用; - 如果将函数返回对象赋予一个右值引用,则既不是移动语义也不是拷贝语义,因为这个时候该临时对象的资源未发生移动和拷贝,仅增加了在函数外访问的途径(相当于指针指向),此时该临时对象为将亡值;
-
一个代码的例子如下:
class A{
public:
char* ptr;
int val;
std::string s;
A() :ptr("hello"), val(5), s("world") {
};
A(const A& _a) {
// 拷贝语义
printf("copy constructor\n");
int _cnt = 0;
while (*(_a.ptr + _cnt) != '\0') {
_cnt++;
}
ptr = new char[_cnt + 1];
memcpy(ptr, _a.ptr, sizeof(char) * (_cnt + 1));
val = _a.val;
s = _a.s;
}
A(A&& _a) {
// 移动语义
printf("move constructor\n");
val = std::move(_a.val);
ptr = std::move(_a.ptr);
s = std::move(_a.s);
_a.val = 0;
_a.ptr = nullptr;
}
A& operator=(const A& _a) {
// 拷贝语义
printf("copy operator =\n");
int _cnt = 0;
while (*(_a.ptr + _cnt) != '\0') {
_cnt++;
}
ptr = new char[_cnt + 1];
memcpy(ptr, _a.ptr, sizeof(char) * (_cnt + 1));
val = _a.val;
s = _a.s;
}
A& operator=(A&& _a) {
// 移动语义
printf("move operator =\n");
val = std::move(_a.val);
ptr = std::move(_a.ptr);
s = std::move(_a.s);
_a.val = 0;
_a.ptr = nullptr;
}
};
A a;
printf("c: %s %s\n", a.ptr, a.s.c_str());
printf("a: %d\n", &a.ptr);
// 拷贝语义
A b(a);
printf("c: %s %s\n", b.ptr, b.s.c_str());
printf("b: %d\n", &b.ptr);
// 移动语义
A c(std::move(a));
printf("c: %s %s\n", c.ptr, c.s.c_str());
printf("c: %d\n", &c.ptr);
auto func = []() {
A tmp;
tmp.ptr = "hello again";
tmp.val = 10;
tmp.s = "new world";
return tmp;
};
A d;
// 移动语义
d = func();
printf("d: %s\n", d.ptr);
printf("d: %s\n", d.s.c_str());
A e;
// 移动语义
e = std::move(d);
printf("e: %s\n", e.ptr);
printf("e: %s\n", e.s.c_str());
3.4 引用坍缩规则
- 用于对引用进行再次引用参数传递;
- 引用坍缩规则(也称引用折叠规则)如下:
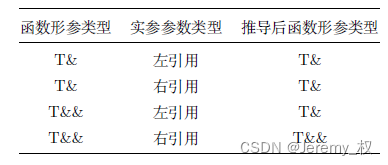
- 当仅当实参是右引用类型(将亡值)且形参是右引用类型时,传递进函数的类型才是右引用类型,其余均为左引用类型,也就是说形参的形式并不能决定引用的类型;
- 注意,右引用类型变量本身是一个左值,因此它继续往下传递的话应该是被视作左引用类型;
- 引用坍缩规则只适用于有自动推导类型的情况,如下:
- 模板函数
T&&; auto变量类型推导;decltype表达式类型推导;typedef或者using别名推导;- 参考:
- 模板函数
// 模板函数
template<typename T>
void f(T&& param);
// auto自动推导
auto&& var2 = var1;
// typedef自动推导
template<typename T>
typedef T&& RRef;
// using自动推导
template<typename T>
using RRef = T&&;
// decltype自动推导
decltype(w1)&& v2 = w2;
- 如果不是自动推导的类型,则左右值引用实际上是两种不同的类型,即:
- 无法将一个左值引用实参传递给一个右值引用形参;
- 但可以将一个右值引用实参传给常量左值引用形参;
3.5 完美转发
-
作用:
- 避免右引用类型往下作引用传递时作为左值传递;
- 这样就可以忽略右引用类型变量本身是一个左值这个有点绕的设定了;
-
使用:
- 使用
std::forward<右值或左值引用类型>(右值或左值引用变量)可以进行完美转发;
- 使用
void pass(T&& v) {
// 总作为左值转发
std::cout << " 普通传参: ";
reference(v);
// 强制转为右值转发
std::cout << " std::move 传参: ";
reference(std::move(v));
// 使用std::forward转发
std::cout << " std::forward 传参: ";
reference(std::forward<T>(v));
// static_cast<T&&>转换也符合引用坍缩规则
std::cout << "static_cast<T&&> 传参: ";
reference(static_cast<T&&>(v));
}
三、容器
1. std::array
- 作用:
- 作为传统数组的替代;
- 适用于对象大小固定的数组对象;
2. std:: forward_list
- 作用:
- 作为传统单向链表的替代;
3. std::unordered_map
- 作用:
- 底层使用哈希表;
- 时间复杂度比std::map小,为常数时间复杂度;
- 不能自动进行有序遍历;
4. std::unordered_set
- 作用:
- 底层使用哈希表;
- 时间复杂度比std::set小,为常数时间复杂度;
- 不能自动进行有序遍历;
5. std::tuple
-
作用:
- 突破std::pair只能存两个元素的限制,std::tuple可以存任意数量元素;
-
使用:
#include <tuple>;std::make_tuple(参数1,参数2...)用于返回由各参数组成的std::tuple类型元组;std::get<元组下标>(元组变量)用于获得元组变量对应下标的元素,可读写;std::tie(变量名1, 变量名2...) = 元组变量用于将元组变量拆包,然后赋值给对应的变量名,可以用std::ignore作变量名占位符;std::tuple_cat(元组变量1, 元组变量2)用于合并两个元组;std::tuple_len(元组变量)用于返回元组元素个数(元组长度);- C++14后,可以用
std::get<元素类型>(元组变量)来获得元组中的该类型元素,但如果该类型的元素不唯一,则会有编译期错误; - C++17后,可以用
std::tuple_index(元组变量, 元组下标)获得元组对应下标的元素; - 参考:
auto student = std::make_tuple(3.8, ’A’, " 张三");
std::get<0>(student) = 3.6; // 修改元组的元素
cout << std::get<0>(student) << endl; // 读取元组的元素
std::get<double>(student) = 3.6 // C++14后
std::tie(gpa, std::ignore, name) = student;
auto new_tuple = std::tuple_cat(get_student(1), std::move(t));
for(int i = 0; i != tuple_len(new_tuple); ++i)
// 运行期索引,C++17后
std::cout << tuple_index(new_tuple, i) << std::endl;
四、智能指针与内存管理
[1]. std::shared_ptr
-
作用:
- 记录多少个shared_ptr共同指向同一个对象;
- 当引用计数为0的时候自动将对象删除;
-
使用:
#include <memory>;- 用
std::make_shared<对象类型>(对象值)可以生成一个对象,并返回它的shared_ptr指针,推荐这样使用; - 用
get()可以获取原始指针而不增加引用计数; - 用
reset()可以将当前shared_ptr的指向和引用计数清空,同时将其他指向同一个对象的shared_ptr的引用计数减一; - 可以赋值为
nullptr;
std::make_shared<int> pointer0(new int); // 不推荐这样使用
auto pointer = std::make_shared<int>(10);
auto pointer2 = pointer; // 引用计数+1
auto pointer3 = pointer; // 引用计数+1
int *p = pointer.get(); // 这样不会增加引用计数
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 3
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 3
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 3
pointer2.reset();
std::cout << "reset pointer2:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 2
std::cout << "pointer2.use_count() = "
<< pointer2.use_count() << std::endl; // pointer2 已reset; 0
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // 2
pointer3.reset();
std::cout << "reset pointer3:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl; // 1
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl; // 0
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl; // pointer3 已reset; 0
[2]. std::unique_ptr
-
作用:
- 独占一个对象的指向,禁止别的智能指针与它共享一个对象;
-
使用:
#include <memory>;- 可以用
std::unique_ptr<对象类型> 智能指针名(指向对象的指针)生成一个对象; - C++14后可以用
std::make_unique<对象类型>(对象值)生成一个对象,并返回它的unique_ptr指针,推荐这样使用; - 虽然std::unique_ptr是独占的,但可以用
std::move(unique_ptr)把它指向的对象转移给别的std::unique_ptr; - 可以赋值为
nullptr;
std::unique_ptr<Foo> p1(std::make_unique<Foo>());
// p1 不空, 输出
if (p1) p1->foo();
{
std::unique_ptr<Foo> p2(std::move(p1));
// p2 不空, 输出
f(*p2);
// p2 不空, 输出
if(p2) p2->foo();
// p1 为空, 无输出
if(p1) p1->foo();
p1 = std::move(p2);
// p2 为空, 无输出
if(p2) p2->foo();
std::cout << "p2 被销毁" << std::endl;
}
// p1 不空, 输出
if (p1) p1->foo();
// Foo 的实例会在离开作用域时被销毁
[3]. std::weak_ptr
-
作用:
- 弱引用,不会增加引用计数;
- 不能取值(没有*运算符)和取指针(没有->运算符);
- 只用于检查shared_ptr指向的对象是否还存在,或者获得一个指向对象的新的shared_ptr;
-
使用:
#include <memory>;- 只能通过shared_ptr来构建weak_ptr;
- 用
expired()可以检查当前指向的对象是否还存在,返回布尔类型; - 用
use_count()可以检查当前指向的对象的引用计数; - 用
lock()可以返回当前指向对象的一个shared_ptr指针; - 可以参考博客:weak_ptr基本用法以及怎么解决循环引用;
shared_ptr<int> sp(new int(10));
weak_ptr<int> wp(sp);
auto new_sp = wp.lock();
if(wp.expired()) {
cout << "weak_ptr无效,资源已释放";
}
else {
cout << "weak_ptr有效, *new_sp = " << *new_sp << endl;
}
- 原因:
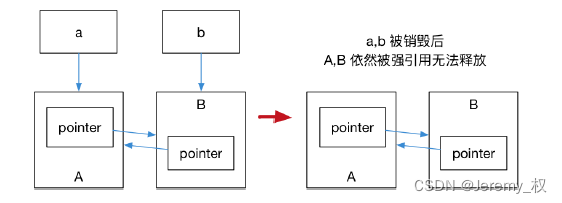
- 如果shared_ptr指向的对象内部有shared_ptr,就有可能引起当前shared_ptr的引用计数不为1,导致释放的死锁(循环引用问题);
- 因为如果要释放shared_ptr指向的内存,就需要它的引用计数为0;
- 但要shared_ptr的引用计数为0,有可能需要先释放它指向内存空间,因为里面有一个智能指针可能会占用当前对象的引用计数;
- 因此该内存空间是无法释放而造成泄漏的,如下图:
4. 小结
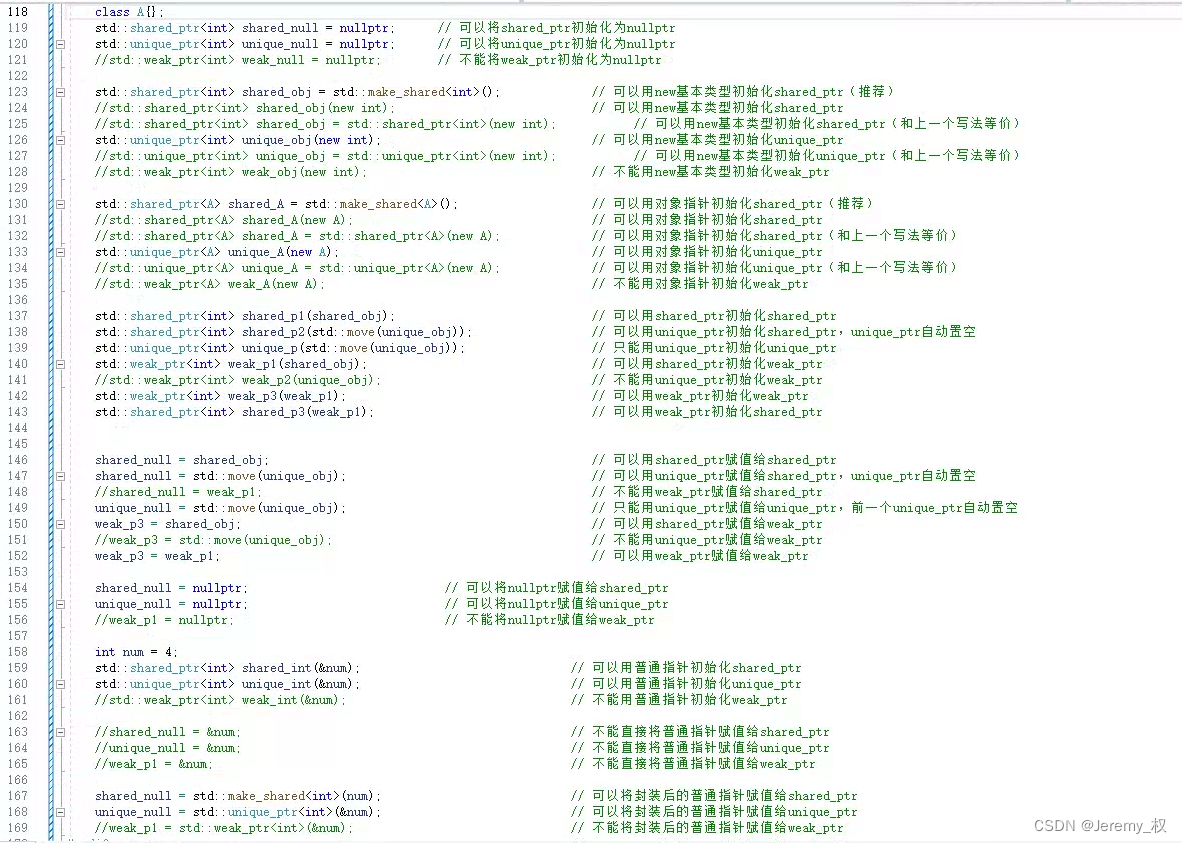
- 三种智能指针的用法总结如下:
weak_ptr:- 只能由
shared_ptr或者weak_ptr初始化; - 只能由
shared_ptr或者weak_ptr赋值;
- 只能由
unique_ptr:- 只能由对象指针或者
std::move(unique_ptr)初始化; - 只能由
nullptr、std::move(unique_ptr)或者unique_ptr<对象类型>(对象指针)赋值;
- 只能由对象指针或者
shared_ptr:- 可以由对象指针、
shared_ptr、std::move(unique_ptr)或者weak_ptr初始化; - 可以由
nullptr、shared_ptr、std::move(unique_ptr)或者shared_ptr<对象类型>(对象指针)赋值;
- 可以由对象指针、
五、并行与并发
- 这里主要介绍多线程编程;
[1]. std::thread
-
作用:
- 创建一个执行的线程实例;
-
使用:
#include <thread>;- 用
std::thread 线程实例名(线程执行的函数名, 函数参数1, 函数参数2...)创建一个执行函数的线程;- 线程执行的函数名必须是全局函数或者静态成员函数;
- 注意,这里的函数参数和
std::bind()一样,如果是值传递或者指针传递,则和普通函数一样,但如果是引用传递,则需要用std::ref(对象名)代替直接使用对象名作为实参;- 如果不用
std::ref(对象名),则普通的左值引用传递仍然是值传递的实现,右值引用传递(使用std::move())才是真正引用传递的实现; - 这主要是为了提醒使用者留意可能发生的引用的对象在函数内部使用时生命周期失效的情况,但实际上传入的指针指向的内存也有被释放的风险;
- 如果不用
- 参考博客:
- 可以用Lambda表达式作为函数参数创建线程;
- 线程实例的成员函数:
join()用于阻塞创建线程实例的线程直至线程实例执行完毕;- 如果线程未脱离,且主线程析构其他线程的时候其他线程仍存活,则会发生
terminate called without an active exception错误; - 因此,未脱离线程时一定要使用
join()使得主线程等待各个线程结束后再结束;
- 如果线程未脱离,且主线程析构其他线程的时候其他线程仍存活,则会发生
detach()用于将线程实例从创建线程实例的线程中脱离开,成为守护线程,这样:- 无法再通过线程实例名获得该线程实例的控制权;
- 但仍能够通过
std::future在创建线程实例的线程中获得线程实例执行的结果; - 各自执行结束之后由系统释放它们的资源,相互无影响,这样可以避免主进程的线程结束后也将未完成处理的子线程一并结束;
#include <iostream>
#include <thread>
int main() {
std::thread t([](){
std::cout << "hello world." << std::endl;
});
// 阻塞main()直至t线程执行完毕
t.join();
return 0;
}
[2]. std::mutex
-
作用:
- 为线程提供互斥量;
- 一些概念:
- 临界区:仅允许一个线程访问的代码区域,但只能在一个进程中实现互斥访问;
- 互斥量:内核对象,可在内核中进行锁操作,可以跨多个进程实现互斥访问;
- 产生死锁的四个条件:
- 互斥:请求的资源是互斥的;
- 请求和保持:请求阻塞时,已有的资源继续保持不释放;
- 不剥夺:不能剥夺别的线程占用的资源,只能由自己释放;
- 环路等待:需要出现一个资源等待的环路;
- 互斥量的锁实现开销是很大的,适合较大临界区代码的互斥;
-
使用:
#include <mutex>;- 成员函数:
lock():当前线程尝试锁住该互斥量,- 如果成功,则当前线程拥有该互斥量锁,直到
unlock(); - 如果不成功,则等待其他线程释放该互斥量锁直到成功,当前线程被阻塞;
- 如果成功,则当前线程拥有该互斥量锁,直到
unlock():当前线程释放该互斥量;try_lock():尝试锁住互斥量,- 如果成功,则当前线程拥有该互斥量锁,直到
unlock(); - 如果不成功,则返回false,当前线程不会被阻塞;
- 如果成功,则当前线程拥有该互斥量锁,直到
std::lock_guard<互斥量类型> 名称(互斥量变量):mutex的RAII语法,用于:- 用来代替
mutex对象.lock(),在对象构造时即尝试为mutex对象上锁; - 自动在作用域结束时(包括异常退出等非正常结束情况)释放互斥量,无需手动调用
unlock()释放; - 注意:
- 在手动
release()之前一定要先unlock(),否则互斥量是无法释放锁的,会导致其他地方陷入竞争锁死锁; - 所以尽量不要使用
release(),尤其是不要误用了release();
- 在手动
- 用来代替
std::unique_lock<互斥量类型> 名称(互斥量变量):mutex的RAII语法,比lock_guard更加灵活,允许:- 在临界区之内手动释放互斥量;
- 在临界区结束时自动释放互斥量;
- 甚至是可以将互斥量的锁以返回值的方式传到作用域外部unique_lock对象上,延长锁的持有时间;
- 比lock_guard和原生的信号量更推荐使用;
- 可以参考博客:
#include <iostream> // std::cout
#include <thread> // std::thread
#include <mutex> // std::mutex
// 调用mutex成员函数
volatile int counter(0); // non-atomic counter
std::mutex mtx; // locks access to counter
void attempt_10k_increases() {
for (int i=0; i<10000; ++i) {
if (mtx.try_lock()) {
// only increase if currently not locked:
++counter;
mtx.unlock();
}
}
}
// 使用lock_guard
void critical_section(int change_v) {
static std::mutex mtx;
std::lock_guard<std::mutex> lock(mtx); // 相当于mtx.lock()
// 执行竞争操作
v = change_v;
// 离开此作用域后mtx 会被释放
}
// 使用unique_lock
void critical_section(int change_v) {
static std::mutex mtx;
std::unique_lock<std::mutex> lock(mtx); // 相当于mtx.lock()
// 执行竞争操作
v = change_v;
std::cout << v << std::endl;
// 将锁进行释放
lock.unlock(); // 相当于mtx.unlock()
// 在此期间,任何人都可以抢夺v 的持有权
// 开始另一组竞争操作,再次加锁
lock.lock(); // 相当于mtx.lock()
v += 1;
std::cout << v << std::endl;
}
[3]. std::packaged_task和std::future
-
作用:
- std::packaged_task和std::future通常是搭配使用;
- std::packaged_task:相当于是封装了一个函数,使之能够在多线程环境中被调用,且可以通过std::future获得该封装函数的执行结果;
- std::future:阻塞当前进程,直到获得其他线程执行的std::packaged_task函数的异步结果;
- std::packaged_task和std::function类似,但提供了多线程环境下的函数封装和结果返回;
- std::future相当于是一种异步调用线程的同步手段,即barrier;
- 一些概念:
- 同步:发出一个调用后,需要等待它执行完毕后再继续执行,如调用
future.get()或者thread.join(); - 异步:发出一个调用后,不需要等待它执行完毕就可以继续往下执行,如创建一个
thread执行函数功能;
- 同步:发出一个调用后,需要等待它执行完毕后再继续执行,如调用
- std::packaged_task和std::future通常是搭配使用;
-
使用:
- 均为
#include <future>; - 用
std::packaged_task<函数返回类型(函数参数类型)> 容器名(函数名或者lambda表达式)创建一个std::packaged_task对象; - 用
std::futrue<函数返回类型> 容器名 = std::packaged_task对象.get_future()创建一个获得std::packaged_task执行结果的future对象; - 用std::future的
get()获得std::packaged_task执行结果; - 参考博客:C++11 并发指南四( 详解二 std::packaged_task 介绍)和C++11 并发指南四( 详解三 std::future & std::shared_future);
- 均为
#include <iostream> // std::cout
#include <future> // std::packaged_task, std::future
#include <chrono> // std::chrono::seconds
#include <thread> // std::thread, std::this_thread::sleep_for
// count down taking a second for each value:
int countdown (int from, int to) {
for (int i=from; i!=to; --i) {
std::cout << i << '\n';
std::this_thread::sleep_for(std::chrono::seconds(1));
}
std::cout << "Finished!\n";
return from - to;
}
int main ()
{
std::packaged_task<int(int,int)> task(countdown); // 设置 packaged_task
std::future<int> ret = task.get_future(); // 获得与 packaged_task 共享状态相关联的 future 对象.
std::thread th(std::move(task), 10, 0); //创建一个新线程完成计数任务.
int value = ret.get(); // 等待任务完成并获取结果.
std::cout << "The countdown lasted for " << value << " seconds.\n";
th.join();
return 0;
}
[4]. std::condition_variable
-
作用:
- 为一组竞争同一个互斥量的线程提供一套信号量机制,允许阻塞当前线程或者唤醒别的阻塞线程;
- 也就是在互斥量锁的基础上,增加了同步的机制,允许控制竞争互斥量锁的先后顺序,避免无意义的竞争而耗费资源;
-
使用:
#include <condition_variable>;std::condition_variable 条件变量名;定义条件变量;- 在一组竞争同一个互斥量的线程中,调用:
条件变量对象.wait(unique_lock对象),当前线程被阻塞,同时释放拥有的互斥量对象锁;条件变量对象.wait(unique_lock对象, bool类型返回值函数),仅当函数返回值为false,才将当前线程阻塞,同时释放拥有的互斥量对象锁;条件变量对象.notify_all(),释放拥有的互斥量对象锁,唤醒所有wait()的线程,并让它们竞争互斥信号量;条件变量对象.notify_one(),释放拥有的互斥量对象锁,唤醒某一个wait()的线程,并让它们竞争互斥信号量,但这样没有办法实现并发的竞争,效率较低,不太推荐在并发环境中使用;
- 注意
wait()的对象是持有mutex的unique_lock对象,而非mutex对象本身; - 参考博客:
#include <queue>
#include <chrono>
#include <mutex>
#include <thread>
#include <iostream>
#include <condition_variable>
int main() {
std::queue<int> produced_nums;
std::mutex mtx;
std::condition_variable cv;
bool notified = false; // 通知信号
// 生产者
auto producer = [&]() {
for (int i = 0; ; i++) {
std::this_thread::sleep_for(std::chrono::milliseconds(900));
std::unique_lock<std::mutex> lock(mtx);
std::cout << "producing " << i << std::endl;
produced_nums.push(i);
notified = true;
// 释放mtx,唤醒所有wait(mtx)的线程
cv.notify_all();
}
};
// 消费者
auto consumer = [&]() {
while (true) {
std::unique_lock<std::mutex> lock(mtx);
while (!notified) {
// 避免虚假唤醒
// 释放mtx,等待别的线程唤醒自己
cv.wait(lock);
// 虚假唤醒:可能是由于别的原因而非notify()让自己获得了互斥量锁
}
// 消费者慢于生产者,则短暂取消锁,使得生产者有机会在消费者消费前继续生产
lock.unlock();
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
// 加锁消费
lock.lock();
while (!produced_nums.empty()) {
std::cout << "consuming " << produced_nums.front() << std::endl;
produced_nums.pop();
}
notified = false;
}
};
// 分别在不同的线程中运行
std::thread p(producer);
std::thread cs[2];
for (int i = 0; i < 2; ++i) {
cs[i] = std::thread(consumer);
}
p.join();
for (int i = 0; i < 2; ++i) {
cs[i].join();
}
return 0;
}
[5]. std::atomic
-
作用:
- 为线程提供CPU指令级的原子操作以实现互斥的变量操作;
- 开销小于std::mutex,用于变量的互斥;
-
使用:
#include <atomic>;- 并非所有的类型都可以实现原子操作的,整型和浮点型可以,其他类型可以用
std::atomic<T>::is_lock_free()函数来检查T类型的对应原子类型是否支持真正的原子操作; - 成员函数:
fetch_add():加法操作,也有“+”运算符重载;fetch_sub():减法操作,也有“-”运算符重载;load():返回原子变量值;store():更新原子变量值;exchange():将原子变量设置为新值,并返回旧值;
- 关于
atomic变量重载函数和成员函数的原子性:- 并不是所有的赋值运算都是原子的;
- 总体而言,调用它的成员函数基本都是原子的,但运算符重载可能会使得多个原子操作无法直观看出;
- 自增、自减运算是原子的,但特别注意的是
x = x + y这个运算不是原子的; - 推荐是尽量用它的成员函数,而不使用它的运算符重载,这样操作的原子性比较直观;
- 参考博客:
#include <atomic>
#include <thread>
#include <iostream>
//std::atomic<int> count = {0};
int main() {
std::atomic<int> count;
std::atomic_init(&count, 0);
std::thread t1([](){
count.fetch_add(1);
});
std::thread t2([](){
count++; // 等价于fetch_add
count += 1; // 等价于fetch_add
});
t1.join();
t2.join();
std::cout << count << std::endl;
return 0;
}
[6]. 原子操作的内存模型
6.1 一致性模型
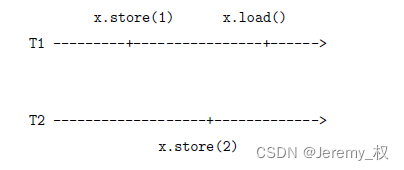
- (1) 线性一致性/强一致性/原子一致性:
- 每一次都能读到变量最新写的数据;
- 所有线程看到的操作顺序和全局时钟下的顺序是一致的;
- 全局时钟顺序即在事件真实发生的时间顺序,但由于有通信延迟,所以各个线程看到的操作顺序不一定是全局时钟顺序;
- 如下图,各线程看到的顺序一定是写
x = 1,写x = 2,读x = 2;
- (2) 顺序一致性:
- 每一次都能读到变量最新写的数据;
- 但不要求所有线程看到的操作顺序和全局时钟下的顺序是一致的,只要求能够找到一种在所有线程看来都合理的全局操作排序,符合程序的读写顺序即可;
- Zookeeper使用的是顺序一致性;
- 可以参考博客:什么是顺序一致性?;
- 如下图,各线程保证一定能读到
x = 3,但不保证看到的x写入1一定在写入2之前执行;

- (3) 因果一致性:
- 只保证各个线程所看到的有因果关系的操作顺序是符合因果顺序的;
- 无因果关系的操作顺序不保证;
- 微信朋友圈使用的是因果一致性;
- 如下图,仅保证各线程看到
c在a和b的写入之后执行;

- 最终一致性:
- 如果没有写操作,那么最终所有线程读取的结果都是一致的;
- 它并未保证当前读取到的结果一定是最新的,仅保证最终读取到的结果一定是最新的;
- 如下图,仅保证各线程最终一定能读到
x = 4,但当前不一定读到;

- 一些参考:
6.2 std::memory_order
- 可以为原子对象的
load()、store()和fetch_add()增加参数std::memory_order_xxx控制原子操作的一致性,进而降低同步的开销; - (1) 顺序一致性模型:
std::memory_order_seq_cst;- 各线程的原子操作满足顺序一致性;
- 如:
counter.fetch_add(1, std::memory_order_seq_cst);
-
(2) 释放/获取模型:
std::memory_order_release;- 用于
store(); - 确保当前线程之前的代码对所有变量的读写操作不会发生在该释放操作之后;
- 相当于是一个写操作的barrier;
- 本线程的release结束后所有写入对其他施加acquire语义的线程可见,因为release会将本线程所有的写入操作同步到内存;
- 相当于mutex的unlock操作,做完读写再释放锁;
- 用于
std::memory_order_acquire;- 用于
load(); - 确保当前线程之后的代码对所有变量的读写操作不会发生在该获取操作之前;
- 相当于是一个读操作的barrier;
- 可以看见其他线程对该原子变量及之前所有原子变量施加release语义的写入,因为acquire会读入最新内存的值到本线程;
- 相当于mutex的lock操作,获得锁再做读写;
- 用于
std::memory_order_acq_rel;- 同时具备读的acquire语义和写的release语义;
- 可以看见其他线程施加release语义的所有写入,同时自己的release结束后所有写入对其他施加acquire语义的线程可见;
- 参考博客:内存顺序(Memory Order);
-
一个图例如下:
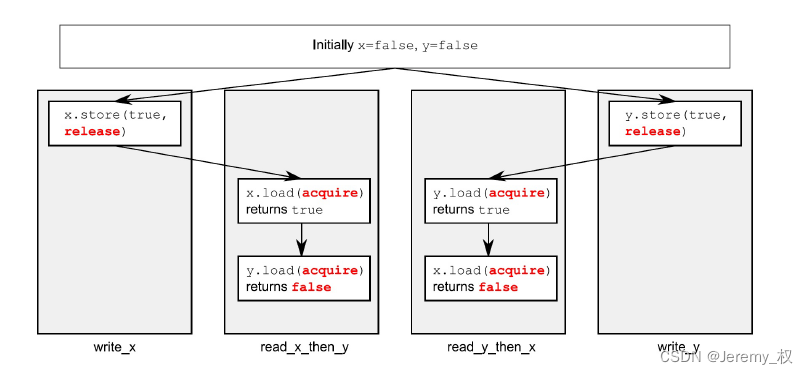
-
一个代码的例子如下:
a = 0;
b = 0;
c = 0;
thread 1:
{
a = 1;
b.store(2, memory_order_relaxed);
c.store(3, memory_order_release);
}
thread 2:
{
while (c.load(memory_order_acquire) != 3)
;
// 以下 assert 永远不会失败
assert(a == 1 && b == 2);
assert(b.load(memory_order_relaxed) == 2);
}
- (3) 释放/消费模型:
std::memory_order_consume;- 用于
load(); - 可以看见其他线程对该原子变量及对该原子变量有依赖关系的原子变量施加release语义的所有写入;
- 是读的acquire语义的稍弱一点版本;
- 一般不建议使用该模型;
- 用于
a = 0;
c = 0;
thread 1:
{
a = 1;
c.store(3, memory_order_release);
}
thread 2:
{
while (c.load(memory_order_consume) != 3)
;
assert(a == 1); // assert 可能失败也可能不失败
}
-
(4) 宽松模型:
std::memory_order_relaxed;- 本线程内的原子操作是顺序执行的,但不同线程中的原子操作顺序任意;
-
一些总结如下:



6.3 自旋锁
- 用于在用户态中实现多线程环境中对共享资源的原子操作,实现的原理的同时使用循环和CAS(Compare And Set)函数;
- 自旋锁既不需要真正地使用互斥量加锁,也不是一个原子操作,但可以实现原子操作的效果;
std::atomic中的CAS函数有两个:原子变量.compare_exchange_weak(期望值, 设置值):- 将原子变量和期望值进行比较,如果相等,则令原子变量等于设置值并返回真;否则,更新期望值为原子变量值,返回假;
- 允许在原子变量等于期望值时因为竞争失败返回假,因为可能有其他线程也是原子变量等于期望值但竞争成功而修改了值;
- 对竞争的要求低,效率更高;
原子变量.compare_exchange_strong(期望值, 设置值):- 将原子变量和期望值进行比较,如果相等,则令原子变量等于设置值并返回真;否则,更新期望值为原子变量值,返回假;
- 它不会因为竞争失败而返回假,如果返回假,则一定是因为原子变量值和期望值不相等;
- 能够很好地解决竞争问题,但效率更低;
- 它们区别的一些解释如下:

- 一个用自旋锁实现的计数器例子如下:
#include <atomic>
#include <thread>
#include <iostream>
int main() {
std::atomic<int> count(0);
std::thread t1([&]() {
for (int i = 0; i < 1000000; ++i) {
/*以下是计数器自旋锁实现*/
int expected = count.load();
// 尝试将count设置为expected+1
// 如果count == expected则设置成功,返回true
// 否则,将expected设置为为count.load(),返回false
while (!count.compare_exchange_weak(expected, expected + 1)) {
}
}
});
std::thread t2([&]() {
for (int i = 0; i < 1000000; ++i) {
/*以下是计数器自旋锁实现*/
int expected = count.load();
while (!count.compare_exchange_weak(expected, expected + 1)) {
}
}
});
t1.join();
t2.join();
std::cout << "count = " << count.load() << '\n';
return 0;
}
六、其他
1. long long int
- 至少有64bit的int类型;
[2]. noexcept
-
作用:
- 声明当前函数不可能抛出异常;
- 如果声明的函数抛出异常,则立即终止程序;
- 能够组织异常的扩散传播;
-
使用:
函数返回值类型 函数名(函数参数类型) noexcept;用于声明一个函数不会抛出异常;noexcept(表达式)用于判断表达式是否有异常;
// 可能抛出异常的函数
void may_throw() {
throw true;
}
auto non_block_throw = []{
may_throw();
};
// 不抛出异常的函数
void no_throw() noexcept {
return;
}
auto block_throw = []() noexcept {
no_throw();
};
3. 自定义字符串字面量
-
作用:
- 避免在字符串中添加大量的转义符等;
-
使用:
R"(字符串)"将字符串定义为字符串字面量;- 重载双引号
""后缀运算符可自定义整型字面量、浮点型字面量、字符串字面量和字符字面量为字符串字面量;
// 字符串字面量自定义必须设置如下的参数列表
std::string operator"" _wow1(const char *wow1, size_t len) {
return std::string(wow1)+"woooooooooow, amazing";
}
std::string operator"" _wow2 (unsigned long long i) {
return std::to_string(i)+"woooooooooow, amazing";
}
int main() {
auto str = "abc"_wow1;
auto num = 1_wow2;
std::cout << str << std::endl;
std::cout << num << std::endl;
return 0;
}

4. 控制内存对齐
-
作用:
- 查询或者重新修改结构体的对齐方式;
-
使用:
alignof(结构体):返回结构体的有效对齐值;struct alignas(有效对齐值) 结构体名{};:修改结构体的有效对齐值,只能往大对齐;- 参考博客:C++11的alignof和alignas;
struct alignas(4) stTestAlign // 修改有效对齐值为4字节
{
char a;
char b;
stTestAlign()
{
cout << "sizeof(stTestAlign) =" << sizeof(stTestAlign) << endl; //4
cout << "alignof(stTestAlign) =" << alignof(stTestAlign) << endl; //4
}
};
struct stTestAlign
{
char a;
alignas(4) char b; // char原本是1字节,强制作为4字节对齐
stTestAlign()
{
cout << "sizeof(stTestAlign) =" << sizeof(stTestAlign) << endl; //8
cout << "alignof(stTestAlign) =" << alignof(stTestAlign) << endl; //4
}
};
补充:类或者结构的默认对齐方式
- 参考博客:C++ 内存对齐;
- 概念:
- 编译器对齐系数:
#pragma pack(n),由系统的位数和编译器决定,通常默认为8; - 有效对齐值:对齐系数和结构体中最长数据类型的长度之间的最小值;
- 如果结构体中又含有结构体类型成员,则只取该成员内部最长数据类型的长度,也就是说结构体的最长数据类型的长度由它内部最长基本数据类型的长度决定;
- 编译器对齐系数:
- 对齐规则:
- 结构体的每个成员相对于结构体首地址的偏移量 = min{ 有效对齐值, 该成员的数据类型长度} 整数倍,成员之间的空隙会增加填充字节;
- 结构体的总大小为有效对齐值的整数倍,成员之间的空隙会增加填充字节;
七、C++20特性
1. 协程
-
定义:
- 协程是可以被挂起然后在稍后重新继续执行的函数;
- 完全是用户态操作,切换不需要陷入内核;
-
作用:
- 可以避免回调地狱,即回调函数逻辑过深且不清晰;
- 回调函数:作为参数传入其他函数供其他函数调用的函数,可以是普通的函数,也可以是匿名函数;
-
使用:
- 可以在协程函数里面使用以下三种关键字:
co_await Awaitable结构体:调用一个Awaitable对象,由它内部定义决定它是挂起还是继续以及挂起和恢复时的行为:await_ready():询问Awaitable结构体是否已经准备好而不需要等待;await_suspend():传入一个coroutine_handle类型的参数挂起Awaitable结构体;await_resume():协程重新运行时调用该函数,同时返回值,返回值的Promise;
co_yield:暂停执行并返回一个值;co_return:完成执行并返回一个值;
// 用回调函数实现init + 100
using call_back = std::function<void(int)>;
void Add100ByCallback(int init, call_back f) //init是传入的初始值,add之后的结果由回调函数f通知
{
std::thread t([init, f]() {
std::this_thread::sleep_for(std::chrono::seconds(5)); // sleep一下,假装很耗时
f(init + 100); // 耗时的计算完成了,调用回调函数
});
t.detach();
}
// 将回调函数封装成协程结构
struct Add100AWaitable
{
Add100AWaitable(int init):init_(init) {
}
bool await_ready() const {
return false; }
int await_resume() {
return result_; }
void await_suspend(std::experimental::coroutine_handle<> handle)
{
// 定义一个回调函数,在此函数中恢复协程
auto f = [handle, this](int value) mutable {
result_ = value;
handle.resume(); // 这句是关键
};
Add100ByCallback(init_, f);
}
int init_; // 将参数存在这里
int result_; // 将返回值存在这里
};
// 调用协程计算init + 100,可以多次调用
Task Add100ByCoroutine(int init, call_back f)
{
int ret = co_await Add100AWaitable(init);
ret = co_await Add100AWaitable(ret);
ret = co_await Add100AWaitable(ret);
f(ret);
}
- 参考:
2. 概念与约束
-
作用:
- 能够让编译器在编译期时对模板参数进行判断,从而检查和限制模板参数的使用;
-
使用:
- 使用
concepts关键字;
- 使用
3. 模块
-
作用:
- 拆分代码成各个模块;
-
使用:
- 使用
export、module和import等关键字;
- 使用